Mais pourquoi l’IA est-elle utilisée pour faire la guerre ?, demande le sociologue Ori Schwarz dans un passionnant article pour Big Data & Society, en observant l’usage qu’en a fait l’armée israélienne à Gaza (voir notre dossier L’IA ça sert, d’abord, à faire la guerre). Qu’apporte-t-elle, que permet-elle que les techniques de guerre traditionnelle n’apportent pas ?
Pour le chercheur, l’IA a été utilisée pour accélérer la génération de cibles, car l’armée israélienne a adopté une doctrine axée sur la « létalité » (visant à maximiser le nombre de victimes) tout en intégrant le droit international humanitaire (qui impose de distinguer les cibles militaires des civils). L’IA n’était pas tant requise pour personnaliser le traitement, que pour justifier d’un traitement uniforme en créant des justifications adaptées, explique-t-il. Elle a été instrumentalisée pour légitimer tueries et destructions de masse en fusionnant et en analysant automatiquement des données pour transformer des milliers d’individus et de bâtiments en cibles légitimes assorties de scores de probabilité individuels.
Pour le chercheur, le profilage, la « singularisation automatisée » (que proposait le sociologue allemand Andreas Reckwitz dans son livre, The Society of Singularities, Polity, 2020), c’est-à-dire le fait que chacun soit traité différemment selon les données récoltées sur lui, est utilisée avec succès dans tous les domaines que le numérique transforme (marketing, médecine, tarification…). Mais, alors que le profilage ne cesse de promettre une distinction plus précise, il permet finalement de générer des effets de masses désastreux, comme dans le cas des destructions lors de la guerre à Gaza, brouillant la distinction entre cibles militaires et populations protégées. « Plus de 71 000 Palestiniens ont été tués, selon les chiffres officiels palestiniens et les estimations de l’armée israélienne. Mais seuls 20 % d’entre eux seraient des militants du Hamas alors que près de la moitié des victimes seraient des femmes et des mineurs. Des milliers d’autres sont portés disparus et d’autres encore sont morts de maladie et de malnutrition. Près de 2 millions de personnes ont perdu leur logement, la plupart des bâtiments résidentiels de Gaza ayant été détruits ou gravement endommagés. L’ampleur des pertes civiles a conduit la Cour internationale de Justice à saisir Israël pour violation présumée de la Convention sur le génocide. »
Une grande partie de ces victimes et destructions visait des cibles identifiées par les services de renseignement israéliens grâce à une utilisation sans précédent de technologies numériques sophistiquées. Schwartz y voit un paradoxe. D’un côté, l’armée israélienne s’est vantée d’effectuer la sélection des cibles à l’aide d’outils d’IA et d’analyse de données les plus sophistiqués pour identifier des cibles humaines et des infrastructures liées au Hamas ; pourtant, le résultat de cet investissement sans précédent dans un ciblage sophistiqué donne l’impression d’une destruction et de tueries massives et indiscriminées. « Si l’objectif est de tuer sans distinction, pourquoi une technologie aussi avancée est-elle nécessaire ? »
Pour Schwarz, si l’IA est utilisée pour procéder à des tueries de masse, c’est justement en raison de sa capacité de distinction : « en singularisant les justifications de tueries indiscriminées, elle produit de la distinction au service de l’indiscrimination ». Cela se produit parce que les effets sociaux de l’IA ne sont pas prédéterminés par les caractéristiques technologiques, mais façonnés par les contextes juridique, structurel, culturel, politique et moral dans lesquels la technologie s’inscrit. En particulier, les tueries et les destructions indiscriminées découlent de la construction politique de « cibles ». À une époque où le droit international humanitaire ainsi que les normes éthiques et professionnelles militaires exigent de ne viser que des « cibles » légitimes, l’impact du big data sur la guerre ne consiste pas nécessairement à réduire les massacres et les destructions en trouvant « l’aiguille dans la botte de foin », comme on l’affirme généralement. Mais, tout le contraire : « il s’agit de transformer le foin en aiguilles, en « incriminant » presque tous habitants ou tous les immeubles résidentiels par l’élaboration d’un récit singulier les associant exclusivement à l’ennemi, légitimant ainsi une destruction indiscriminée. » Pour le chercheur, les massacres et les destructions ne s’expliquent pas uniquement par ces développements technologiques bien sûr, mais la justification technique a permis de renforcer les dynamiques politiques en cours.
Les raisons du succès de l’élimination ciblée
Longtemps, les assassinats extrajudiciaires se limitaient à de rares opérations clandestines visant des opposants de haut rang, rappelle le chercheur. Puis l’élimination ciblée s’est transformée en une politique déclarée, systématiquement mise en œuvre à une échelle toujours plus vaste.
Cette politique s’appuie sur trois principes. Premièrement, l’individualisation de la guerre : l’affrontement est requalifié en une action de police ou de poursuite judiciaire visant des individus. Les individus deviennent des cibles non pas en raison de leur statut (appartenance à une force armée ennemie), mais en raison de leur comportement ou de la menace qu’ils représentent. Chaque individu reçoit un score qui détermine son implication quelque soit les biais du calcul. Et la valeur que l’on attribue à cette implication peut varier.
Deuxièmement, la juridicisation de la guerre : face à la complexité croissante du droit international humanitaire, les armées ont intégré des juristes à leurs équipes pour protéger leurs personnels des poursuites. Désormais, il faut pouvoir établir la légalité des attaques, au regard de principes de nécessité, de proportionnalité et de distinction. Tout en trouvant des modalités pour interpréter le droit international de manière extensive… La juridicisation a conduit à devoir collecter des données pour établir la légalité des ciblages.
Troisièmement, le transfert de risque vise à minimiser le risque pour les soldats en les transférant aux civils ennemis, par exemple en recourant à des bombardements aériens, de préférence par drones, plutôt qu’à des combats terrestres ou à des arrestations. « Depuis 2000, l’ampleur des « assassinats ciblés » a connu une croissance spectaculaire, passant de quelques dizaines à plusieurs milliers de victimes. Cette augmentation est due à l’élargissement controversé de la définition des cibles légitimes », qui a inclus les membres non combattants d’organisations terroristes, puis les civils ayant contribué indirectement aux hostilités. Cet élargissement a engendré un nouveau défi que les systèmes d’IA ont cherché à relever par le scoring : prouver le lien de la cible avec l’organisation ennemie. Si ce lien était évident lorsqu’il s’agissait de cibler des commandants de haut rang, il est devenu de plus en plus difficile à prouver à mesure que le nombre de cibles augmentait. Ce n’est qu’au cours de la guerre de Gaza de 2023, avec la décision d’attaquer des dizaines de milliers de jeunes militants du Hamas, que la nécessité de vérifier si la cible envisagée pour un assassinat avait un lien quelconque avec une organisation terroriste, s’est imposée. « L’utilisation du big data a transformé les cibles d’exécutions extrajudiciaires, passant d’individus isolés (des personnes importantes et connues) à des cas regroupés en clusters dynamiques calculés par des algorithmes. Si les « assassinats ciblés » requièrent certaines technologies de renseignement et de surveillance, l’analyse des mégadonnées a été progressivement introduite, d’abord pour réduire le taux élevé d’erreurs d’identification humaine, puis, à plus grande échelle, pour rationaliser les opérations d’assassinat, en réduire les coûts et en étendre la portée ». Bien que l’utilisation de l’IA pour « incriminer » des cibles repose sur l’individualisation et la juridicisation de la guerre, la quantification automatique des risques entre en conflit avec des principes juridiques fondamentaux tels que le raisonnement, la réflexion et la prise de décision contextualisée. Les chercheurs critiques Nicola Perugini et Neve Gordon affirment que les assassinats ciblés reposent sur un « dispositif de distinction » conçu pour désigner des cibles humaines à des fins militaires en identifiant des « anomalies » dans les relations entre les données, c’est-à-dire en surveillant les comportements et en repérant les irrégularités. Les écarts statistiques sont alors considérés comme des écarts normatifs passibles de la peine de mort, comme l’expliquait le politologue Hendrik Huelss.
Avant même leur automatisation, les assassinats se fondaient déjà sur l’identification de schémas de vie associés au terrorisme. La surveillance et les données permettent de requalifier des individus, auparavant considérés comme des « civils » protégés, en cibles ennemies jugées moralement et légalement abattables, même lorsqu’ils ne participent pas directement aux hostilités. Eric Bonds a qualifié ce phénomène de « violence humanisée », une nouvelle forme de violence qui se manifeste à la fois par une pratique (fondée sur la surveillance et les technologies d’élimination de précision) et par un discours de légitimation (qui s’appuie sur le langage des droits de l’homme et qui, comme le présente ses partisans, paraît rationnel, mesuré et humain, car ils s’efforcent de minimiser les dommages causés aux civils innocents en évaluant les dommages collatéraux prévus de chaque frappe par rapport à son avantage militaire). Ceci produit un « effet paradoxal » : le strict respect des procédures et des critères juridiques (qui interdisent de cibler les civils ne participant pas aux hostilités et exigent que les dommages causés aux civils soient minimaux) tout en permettant de les contourner.
Le scoring pour renforcer la tolérance à l’intolérable
Le paradoxe, c’est que la justification par le calcul renforce la tolérance à l’égard des meurtres de civils. « L’utilisation de technologies avancées visant à réduire les dommages causés aux civils (par exemple, la reconnaissance faciale pour éviter les erreurs d’identification et l’imagerie satellitaire pour estimer les dommages collatéraux et calculer la proportionnalité avec une précision actuarielle) et le recours à des calculs proportionnels à l’avantage militaire renforcent la légitimité et la tolérance à l’égard des meurtres de civils ».
En effet, ces calculs rendent chaque attaque juridiquement justifiée et les décès de civils regrettables, mais légitimes. Les efforts déployés pour minimiser les « dommages collatéraux » (en avertissant les civils avant les attaques et grâce aux calculs de proportionnalité) présentent les incidents ayant entraîné de nombreuses victimes civiles comme des accidents involontaires comme l’explique Craig Jones dans son livre The War Lawyers (Oxford University Press 2020 ou Yael Levy, dans le sien Shooting without crying: The new militarization of Israel in the 2000s, 2023). Et la numérisation renforce considérablement cette légitimation : les scores calculés par algorithme bénéficient d’une aura d’objectivité et de confiance en raison de la confiance bien documentée accordée aux chiffres – notamment par l’historien des sciences Theodore Porter dans son livre, La confiance dans les chiffres (Les Belles lettres, 2017). En convertissant l’incertitude quant aux dommages potentiels causés aux citoyens en « risques » mesurables, les algorithmes transforment les dilemmes moraux en procédures technico-informatiques et finalement réduisent les doutes moraux et la réflexivité, comme le montrait Lucy Suchman dans un article de recherche. Finalement, le ciblage automatisé permet de légitimer les frappes, qu’importe les dégâts qu’elles causent. Or, la violence « humanisée » tue principalement des civils (60 % à 90 % des décès sont des « dommages collatéraux » expliquaient déjà Perugini et Gordon, rappelant également qu’elle est imprécise et surtout qu’elle restreint les catégories protégées tout en légitimant le meurtre).
Contrairement aux tirs des chars, les frappes aériennes contres des cibles spécifiées par le renseignement sont soumises aux principes du droit international humanitaire qui définit les conditions de la légitimité de la violence militaire et doivent donc être traduit en procédures formelles qui encadrent la définition des cibles. Le droit humanitaire repose notamment sur des principes de distinction (ne cibler que les cibles militaires dont l’attaque procure un avantage militaire, et non les civils ou les infrastructures civiles), de proportionnalité (interdire les attaques qui causent des dommages disproportionnés aux civils par rapport à l’avantage militaire obtenu) et de précaution. Mais une autre doctrine est venue également changer le cours de la guerre : la doctrine de la létalité. Plus que le contrôle du terrain, le nombre de morts ennemis est devenu le principal critère d’évaluation des opérations militaires ou des performances des unités. L’industrialisation de l’extermination de précision, défendue par Aviv Kokhavi, chef d’état major de l’armée israélienne, exigeait la production en masse de cibles pour les frappes aériennes. Mais la cible, même légitime, est une construction politique et sociale, comme le montrait l’article de +972 Magazine, qui évolue selon le contexte, à l’image des dommages collatéraux afférents autorisés ou du niveau du scoring qui transforme un soupçon en cible.
En effet, les procédures utilisées pour transformer des personnes ou des bâtiments en cibles impliquent divers acteurs s’intégrant à un réseau : non seulement les définitions juridiques, les concepts moraux et les agents de renseignement, mais aussi les documents de renseignement, les technologies de surveillance qui les produisent et les technologies utilisées pour les traiter et les analyser. La construction des cibles n’étant pas uniquement un processus social, les évolutions technologiques peuvent la transformer. Et le scoring est justement en passe de devenir le facteur d’accélération.
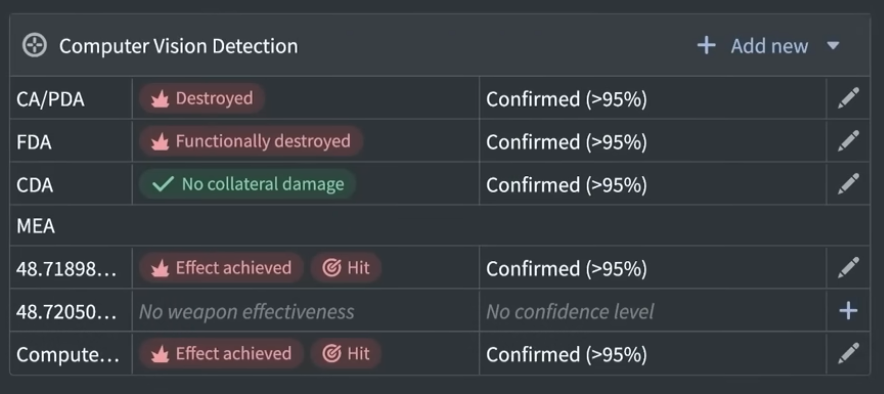
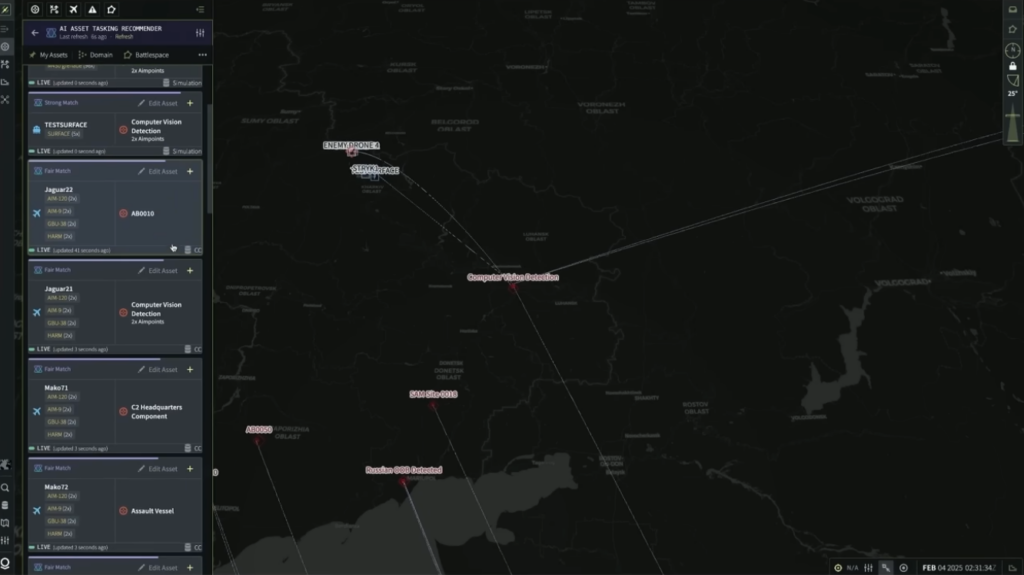
Comment l’IA a-t-elle modifié la construction des cibles, qui n’est pas uniquement un processus social ? Lors de la guerre de Gaza, Israël a utilisé deux types de systèmes d’IA distincts, l’un pour les cibles d’infrastructure et l’autre pour les cibles humaines, explique Schwarz. Ces systèmes avaient des historiques différents, mais présentaient de nombreux points communs. Les personnes interrogées ont souligné que ces deux systèmes ne prenaient pas de décisions à la place des humains, mais accéléraient la production de cibles de deux manières : en fusionnant les informations provenant de sources multiples et en rendant accessibles aux analystes toutes les informations pertinentes concernant chaque cible potentielle ; et en classant les cibles potentielles selon leur probabilité estimée. Ainsi, les analystes humains peuvent se concentrer exclusivement sur les cibles les plus susceptibles d’être approuvées : « [Supposons] que vous disposiez d’un milliard d’informations et que (…) vous n’ayez que 100 cibles alors que vous avez 10 000 candidats. Alors, à quoi sert l’IA ? À une seule chose : les trier par ordre de priorité. (…) [L’ordinateur] a pris les 10 000 suspects, a examiné quelques milliers de cas avérés et [a reçu l’instruction de trier] tout ce qui se ressemble sur tous les points. Ensuite, la machine établit les priorités, c’est tout. Une fois les priorités établies, elle indique aux services de renseignement : vérifiez ceci, cela et cela. Attribuez une file d’attente. (…) Cela signifie que le travail est rationalisé. Mais aucune machine ne décide », déclarait un officier de l’armée israélienne.
Ce discours humaniste et anthropocentrique, également fréquent dans les déclarations de Tsahal sur l’IA, minimise le rôle de la technologie, la réduisant à un simple outil au service d’objectifs humains. L’armée israélienne a décrit le système d’IA « Gospel » comme un simple « outil technique destiné aux analystes du renseignement », car sa traçabilité et son intelligibilité permettent aux analystes d’examiner eux-mêmes les éléments de renseignement sur lesquels reposent ses recommandations. Cependant, même une délégation partielle du ciblage peut avoir des conséquences plus importantes : d’une part, les pressions organisationnelles de niveau intermédiaire en faveur de l’efficacité et les biais d’automatisation de niveau micro peuvent conduire les analystes humains à approuver les recommandations du système de manière quasi automatique (comme nous le disions dans la seconde partie de notre dossier) ; d’autre part, les outils ne se contentent pas de réaliser les objectifs des utilisateurs, mais les façonnent également en proposant de nouvelles pistes d’action permettant l’accélération. Yossi Sariel, ancien commandant de l’unité de renseignement 8200 de Tsahal, a soutenu que l’accélération est l’une des deux principales contributions de l’automatisation informatique au renseignement. Selon lui, la production d’un plus grand nombre de cibles est nécessaire pour exercer une pression constante sur l’ennemi et le vaincre, mais l’intervention humaine constitue un goulot d’étranglement, car la création d’un tel nombre de cibles exigerait des milliers d’enquêteurs traitant et analysant les données pendant des années. Pour lever cet obstacle, il faudrait une « équipe homme-machine » capable de constituer une base de données de dizaines de milliers de cibles et d’en générer des milliers d’autres chaque jour de combat, comme il l’expliquait dans son livre éponyme. La seconde contribution identifiée par Sariel est la prédiction, définie comme le fait de « compléter les informations manquantes » à partir des tendances observées dans les données massives. La prédiction n’est donc pas seulement orientée vers l’avenir (prédire qui commettra un attentat-suicide), mais surtout vers le présent et le passé (prédire où des armes ont été dissimulées). Les prédictions revêtent alors une importance épistémologique : « elles permettent d’incriminer des personnes et des lieux sur la base d’informations incriminantes inconnues, déduites d’éléments non incriminants connus ». L’IA sert à la production d’inférences, de décisions probabilistes que leur niveau de probabilité valide.
La probabilité sert à générer les cibles et intensifier les frappes
La génération par IA de cibles d’infrastructures (de bâtiments) s’effectue au sein de la Direction du ciblage de l’armée israélienne, créée en 2019, explique Schwarz. Cette création faisait suite à un rapport du Contrôleur de l’État indiquant que la banque de cibles disponible au début de la guerre de 2014 entre Israël et le Hamas était bien inférieure au potentiel réel. Une personne interrogée a expliqué les raisons de la création de cette direction en ces termes : « On veut disposer d’une banque de cibles de qualité, que l’on peut frapper pour contraindre le Hamas à capituler » ; or, en 2014, « cela ne s’est pas passé ainsi : il a fallu envoyer des troupes au sol ». L’armée et les médias israéliens ont présenté cette direction et le système d’IA « Gospel » comme la solution.
Lors des conflits précédents, la banque de cibles s’épuisait après quelques jours ou semaines de bombardements intensifs, limitant le volume de tirs. La direction a promis de remédier à ce problème en accélérant et en rationalisant la génération de cibles, tant avant que pendant les hostilités, afin de « transformer la capacité de destruction de Tsahal en un système industriel » capable de « détruire des milliers de cibles chaque jour », explique un article de Ynet, l’un des journaux en ligne hébreu. Pour y parvenir, Gospel fusionne des milliards de données provenant de sources variées (et notamment du renseignement, telles que des appels téléphoniques interceptés et des photographies aériennes), identifie des cibles potentielles grâce à l’apprentissage automatique (en se fondant sur leur ressemblance avec des cibles précédemment validées) et les classe selon la probabilité qu’il s’agisse de cibles légitimes et de qualité. Ces recommandations classées sont ensuite transmises à des analystes humains pour décision, puis à des officiers supérieurs pour approbation.
Cette automatisation partielle accélère considérablement la génération de cibles. Un officier supérieur du renseignement a noté : « Gospel dispose d’une interface utilisateur très simple qui organise la file d’attente des cibles en fonction de la probabilité et de l’importance. Ainsi, l’opérateur humain reçoit simplement une liste établie par la machine, indiquant la probabilité qu’il s’agisse d’une cible valide ainsi que son importance. Le système fonctionne par scores. Par exemple, il s’agit d’une cible avec une probabilité de 80 % ou de 30 %. La machine émet donc une recommandation : « À mon avis, c’est une cible. » L’opérateur prend alors le relais, vérifie le processus suivi par la machine, exerce son jugement – car la machine peut parfois commettre des erreurs – et décide finalement s’il s’agit bien d’une cible. »» Un autre officier a expliqué que la priorisation automatisée était devenue nécessaire en raison de la « croissance exponentielle » du volume de données (consécutive à la numérisation, à la « datafication » et à l’impératif de collecter et d’analyser toutes les données), rendant l’analyse humaine impossible : « Que faire ? Recruter 50 000 agents de renseignement ? Nous ne les avons pas. Alors, utilisons un bon ordinateur pour effectuer la priorisation à notre place. En somme, c’était la mission assignée à la Direction du ciblage. » Un juriste impliqué dans l’élaboration des cibles a affirmé que la cadence de production du système était 50 fois supérieure à celle d’une équipe de 20 officiers de renseignement. Les personnes interrogées ainsi que les déclarations officielles de l’armée ont souligné que la Direction du ciblage avait pour vocation de « constituer de vastes banques de données » afin de permettre l’attaque de « milliers de cibles en une seule journée », industrialisant ainsi l’extermination. Comme souvent, cette industrialisation s’est accompagnée d’une intensification du travail : dès 2019, les soldats de cette direction nouvellement créée ont fait état de pressions visant à accélérer la production de cibles en faisant l’impasse sur un examen approfondi, avec des mesures incitatives – telles que des jours de congé – pour les équipes les plus « productives ». La durée de validité limitée des cibles a été prolongée grâce à une modification des procédures, autorisant le bombardement de cibles plusieurs mois après leur identification, sans nouvel examen, expliquait Haaretz.
« L’accélération de la production de cibles est jugée cruciale en temps de guerre et l’IA permet justement d’accélérer la production ». Cette accélération a atteint son paroxysme lors de la guerre contre Gaza : au 27e jour du conflit, Tsahal a annoncé avoir frappé 12 000 cibles tout en générant simultanément 1 200 nouvelles cibles grâce à son « usine à cibles » fonctionnant 24 heures sur 24.
Mais l’utilisation de l’IA pour identifier des listes de personnes à cibler plutôt que des lieux relève d’une autre dynamique, explique Schwarz. Une dynamique qui a débuté avec le recours à l’IA pour des arrestations préventives.
À l’automne 2015, Israël a dû faire face à une vague d’attaques spontanées, perpétrées principalement par des adolescents. Il était difficile de déjouer ces attaques, car les auteurs n’étaient affiliés à aucun réseau terroriste ou de guérilla. En conséquence, les services de renseignement israéliens ont mis au point un modèle visant à prédire quels adolescents étaient les plus susceptibles de commettre des attaques, en analysant les schémas d’activité sur les réseaux sociaux (publications, « like », commentaires, émojis, nouveaux liens) ainsi que des données provenant d’autres sources (par exemple, les données de localisation), en attribuant à chaque adolescent palestinien un score de risque. Le modèle s’appuyait sur des schémas prédictifs identifiés à la fois par l’apprentissage automatique (analyse de mégadonnées) et par des analystes humains (par exemple, de nouvelles coupes de cheveux, les auteurs d’attentats-suicides adoptant souvent une nouvelle coiffure peu avant de passer à l’acte). Ce modèle a conduit à l’arrestation préventive de centaines d’adolescents palestiniens.
D’autres systèmes ont été développés par la suite pour identifier des membres d’organisations terroristes en vue de leur arrestation et de leur interrogatoire. Lors de la guerre à Gaza, cette stratégie a été étendue pour dresser des listes de cibles à éliminer d’une longueur sans précédent, appliquant les principes de la police prédictive pour produire des cibles à éliminer. Le système d’IA « Lavender » attribuait à presque tous les habitants de Gaza un score de probabilité d’appartenance au Hamas, en se fondant sur des facteurs couramment utilisés dans la police prédictive comme le montre la sociologue Sarah Brayne dans son livre, Predict and surveil (2021, Oxford university Press), notamment les réseaux personnels, les habitudes de vies comme les lieux fréquentés et les déplacements. 37 000 Palestiniens ont été identifiés par algorithme comme étant probablement des membres du Hamas comme le montrait Abraham dans son article pour +972 Magazine.
« Les scores de probabilité transforment la distinction entre terroriste et civil, passant d’une catégorie binaire à un continuum statistique ». Les individus classés par l’IA comme membres probables du Hamas étaient alors ajoutés aux listes de cibles à éliminer sans réel examen supplémentaire. D’autres rapports font état d’une certaine forme de supervision humaine ; par exemple, des officiers auraient corrigé une erreur d’interprétation de l’IA qui avait pris une liste d’élèves du secondaire pour une liste de militants potentiels, une erreur qui aurait pu conduire à désigner à tort 1 000 adolescents comme cibles.
Reste que l’accélération n’a pas été que technologique, elle a aussi été politique. Le Premier ministre Benjamin Netanyahu aurait reproché au chef d’état-major Herzi Halevi de n’avoir bombardé « que » 1 500 cibles au cours des 48 premières heures du conflit ; il a rejeté l’explication de Halevi, qui indiquait ne pas disposer de 5 000 cibles, en déclarant : « Je m’en fiche ». Sans l’IA, estime Schwarz, « il aurait été difficile d’atteindre une telle ampleur de morts et de destructions ».
L’armée israélienne a assoupli son interprétation du droit international humanitaire pendant la guerre sans pour autant abandonner totalement ce cadre, par exemple en relevant les seuils de « dommages collatéraux » et en autorisant des attaques ciblées contre chacun des 37 000 membres présumés de rang inférieur du Hamas, à condition que le nombre de décès civils anticipés reste inférieur au seuil. La pratique du « roof-knocking » (bombardements d’avertissement) a été abandonnée et des cibles présentant une probabilité moindre ont été prises en compte. En conséquence, le taux de mortalité civile s’est envolé. L’approche vis-à-vis des infrastructures civiles a également évolué pour maximiser la destruction : des immeubles de grande hauteur et des bâtiments universitaires par exemple ont été désignés comme des cibles essentielles et visés en raison de la présence d’un objectif militaire légitime à un seul étage, mais détruits par un armement provoquant l’effondrement de l’édifice tout entier.
Au regard du droit international, cela pourrait être considéré comme une violation des principes de proportionnalité et de précaution. Mais cette proportionnalité et ces précautions, on le voit, permettent aussi de faire varier les classement en ajustant les justifications, sur la base de données singulières et spécifiques l’associant au Hamas avec une certaine probabilité. Tout l’enjeu consiste à fourbir des probabilités et les compléter de narratifs adaptés afin de produire des explications. La destruction des infrastructures civiles, quelle que soit la raison, est devenu l’objectif derrière les justifications : toutes les cibles détectées sont devenues un moyen pour raser Gaza.
L’IA : l’outil pour légitimer la guerre
Pour Ori Schwarz, « les systèmes d’IA ont épargné les dilemmes moraux en légitimant les attaques. Le rôle de l’IA a donc consisté à ériger le général en singulier, transformant presque tout en cible ». Pour Schwarz, avec la guerre à Gaza, l‘IA est devenue un outil de légitimation : l’automatisation permet le respect des procédures. Elle est un moyen pour « préserver les normes éthiques en les inscrivant dans le code, les transformant de règles réglementaires en règles génératives inviolables ».
Comme c’est le cas depuis longtemps, l’automatisation est censée garantir l’éthique. Mais ce n’est pas si vrai. D’abord parce que le système permet d’abaisser le seuil de confiance du ciblage et donc faire que la machine contourne la règle. Et surtout que l’opacité et la complexité du calcul permettent de faire disparaître ses défaillances et la surveillance par les opérateurs humains.
Le statut moral dépend désormais des procédures et non des résultats. Mais surtout, en validant les dommages collatéraux, l’IA a servi de mécanisme de légitimation des massacres de civils. Tactiquement, le rasage des zones urbaines avant les manœuvres terrestres permettait aussi de protéger les soldats israéliens. Enfin, le ciblage fournit un prétexte pour la destruction, une « couverture morale ».
Certains officiers souhaitaient que l’IA puisse générer elle-même les attaques depuis les scores produits. Cette proposition ne s’est pas encore concrétisée, mais les digues sont prêtes à lâcher, estime Schwarz. Notamment parce que les humains dans la boucle de la vérification ne servent déjà plus que d’agents d’enregistrement, chargés de validés les cibles en quelques secondes, sans avoir le temps d’examiner les données ni de comprendre les calculs qui les produisent. Pour Schwarz, si l’armée israélienne n’a pas franchi le pas, c’est notamment parce que le droit international humanitaire exige qu’un humain réponde de chaque décision. Mais plus encore, parce que garder un humain dans la boucle donne l’apparence d’une décision issue d’une délibération humaine.
C’est oublier que l’IA n’organise pas seulement la file d’attente des cibles, elle les désigne. Ce sur quoi les humains ont encore le contrôle reste surtout les critères pris en compte par les données et les seuils. Pour Schwarz, l’élaboration des cibles n’est pas un processus purement social, mais elle n’est pas non plus purement technologique. Le ciblage doit pouvoir être expliqué, contre-interprété. Les opérateurs ne font pas nécessairement confiance aux scores produits, tant qu’ils ne pensent pas les comprendre « et après l’avoir testé sur la durée, en constatant qu’il est cohérent avec le scénario qu’il a en tête » (même constat pour les radiologues confrontés aux résultats de l’IA). La validation d’une cible repose toujours sur une preuve, c’est à dire un récit. Et les analystes doivent souvent défendre leurs choix et validation, comme s’ils étaient face à un tribunal. Ils doivent défendre la cohérence des éléments qu’ils ont sous les yeux. Le risque à terme, suggère Schwarz, c’est que l’IA produise aussi les récits, quand bien même ils seraient aussi faux que les éléments cohérents que valident les humains. Un système d’IA pourrait identifier un lieu fréquenté par plusieurs militants et lui attribuer une priorité élevée, sans envisager qu’il puisse s’agir d’un restaurant, ou qu’une conversation interceptée évoquant le terrorisme provienne en réalité d’un film diffusé à la télévision. Les systèmes d’IA servent « à trouver des corrélations (…) entre toutes sortes de variables que vous ne jugiez pas intéressantes jusqu’alors (…) Évidemment, je présente aux analystes du renseignement une grande quantité de données et de corrélations en leur disant : « Regardez, c’est intéressant ». » Les analystes tentent ensuite d’ouvrir la « boîte noire » et d’élaborer un récit expliquant le fonctionnement du modèle et les raisons de son efficacité, une étape nécessaire pour que le modèle inspire confiance et soit mis en service. « Je leur montre des points de données très précis, [des variables prédictives] », explique un officier chargé de la formation des agents aux outils. Toutefois, il souligne que dans ces situations, les prédictions du système ne servent pas à désigner des cibles tant que les analystes n’ont pas ouvert la boîte noire et expliqué pourquoi ces variables spécifiques intégrées au modèle permettent de prédire les résultats. Pour Schwarz, ces débats contredisent la promesse épistémologique de l’IA – fondée sur un empirisme radical – selon laquelle la prédiction rendrait l’explication superflue, ou qu’il n’y aurait plus besoin de théorie.
Reste, rappelle Schwarz, que même si vous faites confiance à vos experts en science des données et que vous avez collecté et testé les données avec soin, vous ne pouvez pas juger de leur qualité. Vous devez expliquer le plus précisément possible ce que les variables indiquent et pourquoi le modèle prédit ce qu’il prédit. Par conséquent, l’analyste ne renoncera pas à comprendre la signification des corrélations et les raisons des choix du modèle. Les développeurs débattent souvent de la meilleure façon de représenter ces corrélations sans induire les utilisateurs en erreur. Si la classification algorithmique des individus comme cibles à forte probabilité est effectuée automatiquement, sans récit, les agents de renseignement en construisent, à la fois en amont, lors du développement du système, et ultérieurement, afin de conférer sens et légitimité aux recommandations algorithmiques (même si cette dernière dimension a pu s’éroder en raison de l’accélération de la production de cibles en temps de guerre).
Instaurer la confiance : camoufler l’IA
La confiance dans les chiffres n’est pas aussi omniprésente et automatique que la littérature pourrait le laisser croire. Dans notre cas, les utilisateurs finaux des systèmes de mégadonnées (analystes du renseignement) étaient initialement méfiants à l’égard de l’automatisation et des probabilités calculées algorithmiquement. Un développeur que Schwarz a interviewé leur a reproché de se méfier des systèmes d’IA en raison de leur « peur de l’erreur » et de leur prudence excessive (« Ils ont besoin d’un niveau de certitude non pas de 100 %, mais de 200 %, et une telle chose n’existe pas »). Face aux soupçons et à la nécessité de « faire confiance aux chiffres », les developpeurs du système ont entrepris un travail de sensibilisation et élaboré une stratégie sophistiquée : dissimuler le rôle de l’IA et insister sur l’implication humaine. « Les agents du renseignement n’utilisent pas l’IA, ils utilisent des outils conçus pour eux, et de leur point de vue (…), s’il y a de l’IA, d’après mon expérience, ils ne lui font pas confiance. En fait, pour les inciter à l’utiliser, nous n’avons pas dit “c’est de l’IA pure”, mais nous nous sommes assurés que l’agent qui examine une cible puisse voir que Sharon l’a déjà examinée, qu’il puisse voir le nom de la personne qui l’a fait, et qu’il connaisse Sharon. » Ils doivent savoir que Sharon est la meilleure pour identifier les cibles et, par conséquent, ils peuvent lui faire confiance. Dans cet exemple, ils ont tiré parti de la confiance que le personnel du renseignement accordait à une ancienne agente de renseignement très appréciée (« Sharon »), promue et mutée au sein de l’équipe technique. Elle y étiquette les données et valide les cibles générées par algorithme avant leur transmission aux services de renseignement et juridiques pour approbation. La confiance personnelle en Sharon peut faire toute la différence : « Nous avons constaté que lorsqu’une personne comme Sharon est présente, ils font confiance au système ; en revanche, lorsqu’on leur dit “ce n’est qu’un modèle”, ils n’y croient pas [et recommencent le processus manuellement depuis le début]. » Paradoxalement, la confiance dans l’IA (nécessaire à la délégation partielle du travail de renseignement aux algorithmes) exigeait la confiance envers les personnes qui faisaient confiance à l’IA, camouflant ainsi le rôle de cette dernière.
Nous savons que l’IA n’est pas une magie sans intervention humaine ; elle repose sur le travail humain, parfois dissimulé sous l’apparence de décisions de la machine, rappelle Schwarz en évoquant les travaux relatifs au Digital Labor. Or, ici, c’est l’inverse qui se produit : lors du développement des modèles, les décisions des machines doivent être expliquées par des experts humains qui en reconstituent la logique ; et plus tard, lorsque ces systèmes sont utilisés pour produire des cibles, leurs recommandations doivent être camouflées en décisions d’experts humains. Enfin, en temps de guerre, lorsque les analystes du renseignement consacrent à peine 20 secondes à approuver les recommandations de l’IA, le travail de cette dernière est une fois de plus dissimulé sous l’apparence de délibérations humaines.
C’est peut-être à cela que sert encore l’humain dans la boucle : valider les procédures humaines plus que juger du travail des systèmes d’IA.
En examinant de près l’utilisation de l’IA pendant la guerre de Gaza, l’article de Ori Schwarz montre que l’IA était nécessaire non pas pour personnaliser le traitement, mais pour justifier un traitement uniforme en créant des justifications personnalisées pour le ciblage de presque chaque bâtiment ou agent présumé du Hamas, et pour accélérer l’incrimination et la production de cibles à des niveaux sans précédent sans s’écarter complètement du cadre du droit international humanitaire, légitimant ainsi des massacres et des destructions de masse effroyables en s’appuyant sur des calculs et des procédures de probabilité prétendument objectifs, inscrits dans le code.
L’article de Schwarz, montre également que les études critiques sur les impacts sociaux des algorithmes doivent aller au-delà de la simple critique de leurs erreurs et de leurs biais. Ces derniers ont constitué jusqu’à présent le cœur des critiques, et ce pour une bonne raison : malgré leur prétention à la neutralité, les systèmes d’IA sont sujets aux erreurs en général et, en particulier, à la reproduction d’inégalités découlant de biais, dans la mesure où les données utilisées pour leur entraînement consignent et reflètent des préjugés humains. Plus précisément, les erreurs et les biais sont au centre des débats sur l’usage de l’IA dans la guerre, y compris lors du conflit à Gaza.
Mais, estime-t-il, un système d’IA parfait, sans erreur ni biais, « pourrait aboutir aux mêmes conséquences effroyables, simplement en accélérant considérablement la production de cibles et en en réduisant le coût » : le fait de cibler des dizaines de milliers d’objectifs identifiés par le renseignement – une tâche dont la réalisation était pratiquement impossible avant l’IA – conduit presque inévitablement à des destructions et à des tueries de civils à grande échelle. Pire, l’IA permet bien plus de produire des justifications, même de ses erreurs et errements, en les recouvrant d’une complexité et d’un vernis d’explication.
Si la destruction de Gaza répondait à des motivations politique, l’IA a été indispensable pour inscrire la destruction dans le cadre du droit international humanitaire (tout comme les ciblages sociaux s’inscrivent également dans le cadre du droit, malgré leurs défaillances manifestes). Ce potentiel de légitimation pourrait être exploité au-delà du contexte israélien, alors que des systèmes similaires sont adoptés par d’autres armées officiellement attachées au respect du droit humanitaire international. « Si l’accélération peut sembler relever d’un simple changement quantitatif, elle a en réalité engendré une transformation qualitative majeure. Le rôle joué par l’IA dans la légitimation de ces massacres nous rappelle que les caractéristiques et les affordances ne définissent pas les technologies de manière isolée : elles sont façonnées par les contextes juridiques, structurels, culturels et moraux, ainsi que par les réseaux ou dispositifs hétérogènes au sein desquels les technologies opèrent. Il est crucial de prendre en compte ce contexte pour comprendre comment il a pu engendrer des effets effroyables, mais aussi pourquoi il s’est avéré impossible d’éliminer l’humain de la boucle, et pourquoi le travail culturel de production de sens effectué par les humains était nécessaire pour légitimer l’automatisation partielle ayant conduit à cette accélération sans précédent de la production de cibles.»
*
La possibilité d’accéder à toutes les données disponibles bouleverse comme nulle autre le rapport des armées à leurs missions. Sans limites, ce sont les valeurs mêmes de leurs missions qui seront transformées. Et c’est ce que produit le score d’appartenance à l’ennemi et les seuils de dommages collatéraux autorisés. La guerre de demain se joue sur les données, leurs croisements sans limites et les seuils adaptables. Des éléments sur lesquels le droit international n’a pour l’instant pas défini de pratiques et qui, sans encadrement, risquent de permettre tous les glissements moraux du calcul, comme on le constate partout où le scoring se déploie.
Hubert Guillaud