Le 29 Avril 2025 j’ai été (avec d’autres) auditionné à l’assemblée nationale dans le cadre de la commission sur « Les effets de Tiktok sur les mineurs ». L’ensemble des auditions (qui se poursuivent) est disponible en ligne sur le site de l’assemblée.
Initialement invité en compagnie d’Aurélie Jean et de David Chavalarias qui ont finalement dû décliner (j’espère qu’ils pourront tout de même être entendus), le périmètre de cette audition a finalement réuni :
- Mme Sihem Amer-Yahia, directrice de recherche au CNRS, directrice adjointe du Laboratoire d’informatique de Grenoble
- Mme Lucile Coquelin, maître de conférences en sciences de l’information et de la communication, Laboratoire DyLIS, Inspé Normandie Rouen Le Havre, Sciences Po Paris
- M. Marc Faddoul, directeur et cofondateur d’AI Forensics.
- et moi

Pour préparer cette audition, on nous avait envoyé une liste de 18 questions. Je vous livre ci-dessous les réponses que j’y ai apportées et que j’ai également transmises à ladite commission. Comme j’aime bien partager ma vie avec mes étudiant.e.s du meilleur BUT Infocom de la galaxie connue, je leur avais raconté et annoncé cette audition et leur avais aussi demandé de répondre à quelques-unes des questions qui m’avaient été adressées, en le faisant depuis leur point de vue d’utilisateur et d’utilisatrice de la plateforme. J’en ai extrait (avec leur accord et en les anonymisant) quelques verbatims que vous trouverez en toute fin d’article.
A titre personnel cette expérience fut à la fois intéressante mais essentiellement frustrante. Il s’agit d’un dispositif « court » : nous étions ici 4 universitaires à être auditionnés sur un temps d’un peu plus d’une heure. Ajoutez-y les questions et les propos « liminaires » et cela reste court. Mais chaque commission auditionne énormément de personnes et il est donc normal et nécessaire de limiter la temporalité de ces temps d’échange. Il y a aussi une forme de solennité biaisée : nous sommes conviés en tant que praticiens et praticiennes spécialistes d’un sujet auquel nous avons consacré plusieurs dizaines d’années de recherche, de travaux, d’ouvrages et d’articles, mais nous nous adressons à la puissance publique dans un cadre dont il est difficile de déterminer quelle est la part attendue de l’analyse réflexive, et celle de l’opérationnalité immédiate exigée ; car à la fin, tout cela devra se traduire par des mesures concrètes susceptibles de produire ou d’orienter des cadres législatifs à l’origine de décisions politiques. Le dernier point de difficulté est que nous débarquons dans cette commission sans savoir quel est le niveau réel d’acculturation des députés aux éléments que nous allons présenter. J’avais de mon côté écouté l’ensemble des auditions précédentes pour tenter d’éviter les redites et produire un minimum de continuité dans les travaux de la commission, mais même en ayant pris le temps de le faire, l’exercice reste délicat.
Tout ça pour dire que je suis bien content de pouvoir, au calme, transmettre par écrit mes réflexions à cette commission, car si elle devait se fonder uniquement sur ce que je lui ai déclaré à l’oral (ainsi que mes camarades d’audition), je ne pense pas qu’elle serait très avancée ou informée  J’espère donc surtout qu’elle pourra prendre le temps de lire tout cela (ainsi que la synthèse que j’en dresse à la fin en mode TLDR).
J’espère donc surtout qu’elle pourra prendre le temps de lire tout cela (ainsi que la synthèse que j’en dresse à la fin en mode TLDR).
Cela a commencé ainsi.
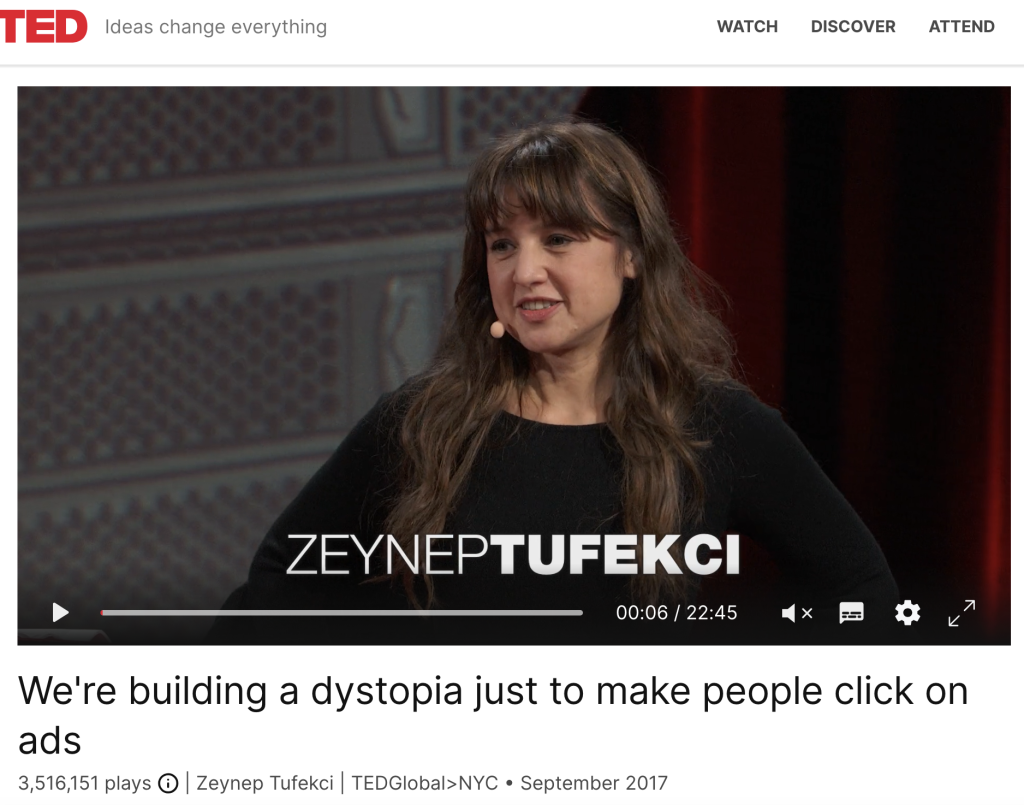
[On nous demande d’abord de nous présenter brièvement et on nous laisse un « propos liminaire » de 5 minutes] Je suis enseignant chercheur en sciences de l’information. Si les universitaires qui étudient la sociologie se définissent comme sociologues, je peux me définir comme « médiologue ». J’étudie les médias numériques (moteurs de recherche, réseaux sociaux, plateformes) et ce qu’ils modifient dans notre rapport à l’information, à la connaissance, aux autres et à nous-mêmes. Depuis 25 ans je documente l’évolution de ces outils avec – essentiellement – des méthodes d’observation participante. Et si je devais résumer 25 ans de recherche en une seule phrase je dirai que tout est de la faute du modèle économique de ces plateformes. Ou pour reprendre le titre d’une conférence d’une collègue, Zeinep Tufekci : « nous avons construit une dystopie, juste pour obliger les gens à cliquer sur des publicités« .
[Propos liminaire 1] En guise de propos liminaires je veux rappeler et insister sur le fait que ces « réseaux sociaux » qui sont en fait des « médias sociaux » doivent être pensés et analysés comme des biotopes particuliers dans un écosystème général qui est celui de l’économie des médias (radio, télé, presse, etc.). Et que ces médias sociaux procèdent (en partie) comme des parasites qui vont littéralement venir phagogyter les autres écosystèmes médiatiques. Les exemples sont nombreux. Il y avait eu à l’époque (circa 2010) le fait que plein de sites de presse ou de médias avaient accepté d’installer sur leur site le bouton « Like » de Facebook qui avait fait d’eux de simples vassaux numériques et médiatiques de cette plateforme devenue hôte. J’écrivais alors et alertais : « Le Like tuera le lien« .
Aujourd’hui il y a toujours des liens d’écho, de résonance très forts entre différents écosystèmes médiatiques mais dans certains cas d’usages, auprès de certaines populations, pour certains segments d’âge ou d’éducation, les médias sociaux sont le premier biotope informationnel. C’est cette question qu’il faut adresser (pour TikTok comme pour les autres) et pour laquelle la part « éditoriale » de ce que l’on appelle « les algorithmes » doit être clarifiée, débattue, encadrée. Encadrée de manière contraignante.
[Propos liminaire 2] Les algorithmes sont comme des ritournelles auxquelles on s’accoutume à force de les fréquenter, que l’on retient – et que l’on maîtrise parfois – dans une forme d’intelligence situationnelle altérée par l’expérience sans cesse renouvelée de cette fréquentation. Comme la ritournelle chez Deleuze et Guattari dans leur ouvrage « Mille Plateaux », les algorithmes sont trois choses à la fois :
- D’abord ce qui nous rassure par une forme de régularité attendue, que l’on devine et anticipe.
- Ensuite ce qui installe l’organisation nous semblant familière d’un espace que l’on sait public mais que l’on perçoit et que l’on investit en partie comme intime : ils « enchantent » l’éventail de nos affects et sont l’état de nature de nos artifices sociaux.
- Enfin ils sont ce qui, parfois, nous accompagne et nous équipe aussi dans la découverte d’un ailleurs, parce qu’y compris au sein de représentations cloisonnées, ils sont des « chants traversants. »
[Propos liminaire 3] La question nous est posée de savoir si l’on peut « exiger des réseaux sociaux d’être entièrement transparents sur leur algorithme« . Oui. En tout cas sur la partie éditoriale, cela me semble nécessaire de l’exiger. En définissant le périmètre de cette éditorialisation pour éviter qu’elle ne puisse être totalement instrumentalisée (par exemple si tout le monde sait qu’un bouton like vaut 1 point et qu’un bouton colère vaut 5 points, nos comportements sont susceptibles de changer).
Mais plus fondamentalement nous parlons d’outils qui ont totalement explosé le cadre anthropologique de la communications entre les êtres humains. On peut se parler à distance, en absence, à la fois à plusieurs et en dialogue, en multimodalité, via des avatars, dans des mondes « réels » ou dans d’autres « virtuels », etc.
Nous parlons d’outils qui touchent chaque jour et de manière récurrente davantage de monde que jamais aucun média n’a jamais été en capacité d’en toucher et ce dans toute l’histoire de l’humanité. Ce ne sont pas seulement des médias de masse mais des médias d’hyper-masse.
Et enfin il y a la question du rythme, de la fragmentation et de la séquentialité hypercourte : notre cerveau n’est pas fait, n’est pas calibré pour s’informer par tranches de 6 à 15 secondes en passant d’un sujet à un autre.
Cette triple révolution anthropologique de la communication ne peut s’accommoder de demi-mesures ou de clairs-obscurs législatifs et réglementaires. A fortiori lorsque la mauvaise foi, la duperie et la tromperie de ces plateformes a été démontrée et documentée à de très nombreuses reprises, grâce notamment aux lanceurs et lanceuses d’alertes.
Et a fortiori encore dans un monde où ces applications et plateformes sont devenues totalement indissociables de pouvoirs politiques qu’elles servent toujours par intérêt (soit pour échapper à des régulations, soit pour jouir de financements publics, soit pour tuer la concurrence comme le documentent encore les actuelles actions en justice contre Google et Meta notamment).
[Propos liminaire 4] Je veux citer ce que j’écrivais dans l’article « Ouvrir le code des algorithmes ne suffit plus »
Après les mensonges de l’industrie du tabac sur sa responsabilité dans la conduite vers la mort de centaines de millions de personnes, après les mensonges de l’industrie du pétrole sur sa responsabilité dans le dérèglement climatique, nous faisons face aujourd’hui au troisième grand mensonge de notre modernité. Et ce mensonge est celui des industries extractivistes de l’information, sous toutes leurs formes. (…) Et même s’ils s’inscrivent, comme je le rappelais plus haut, dans un écosystème médiatique, économique et politique bien plus vaste qu’eux, leur part émergée, c’est à dire les médias sociaux, sont aujourd’hui pour l’essentiel de même nature que la publicité et le lobbying le furent pour l’industrie du tabac et du pétrole : des outils au service d’une diversion elle-même au service d’une perversion qui n’est alimentée que par la recherche permanente du profit.
Les questions de la commission (et mes réponses).
Ces questions étaient organisées en cinq grandes parties :
- Sur le fonctionnement des algorithmes utilisés par les réseaux sociaux.
- Sur les données personnelles utilisées par les algorithmes des réseaux sociaux
- Sur la transparence des réseaux sociaux
- Sur l’éducation aux réseaux sociaux
- Questions générales
Sur le fonctionnement des algorithmes utilisés par les réseaux sociaux
1. Quels sont les multiples facteurs pris en compte par les algorithmes utilisés par les réseaux sociaux, notamment pour déterminer les contenus présentés aux utilisateurs ? Identifiez-vous des spécificités propres au fonctionnement de TikTok ?
De manière générale les algorithmes de recommandation fonctionnent sur 4 critères.
- Le premier est celui de la personnalisation déclarative (on dit ce que l’on aime ou ce que l’on n’aime pas).
- Le second est celui de l’historique de navigation réel : indépendamment de ce que l’on dit aimer, les plateformes « voient » ce que l’on consomme réellement et ce sur quoi on est appétent.
- Le troisième critère est celui de la moyenne statistique (comparativement à d’autres ayant déclaré les mêmes centres d’intérêt, et/ou dans le même groupe d’âge, de genre, etc.)
- le quatrième critère est celui de la stochastique, de l’aléatoire. Depuis le début des systèmes de recommandation, les ingénieurs qui fabriquent ces algorithmes savent que si on ne sort pas de temps en temps de nos centres d’intérêt déclaratifs on va avoir des phénomènes de désintérêt ou de lassitude. Ils injectent donc un peu (ou beaucoup) d’aléatoire pour « affiner » et « ajuster » mais aussi pour (souvent) nous « ramener » des des contenus plus directement monétisables. La question c’est de savoir jusqu’où peut aller cet aléatoire (plus ou moins loin de nos habitudes de. navigation et de consultation) et de quelle manière et en quelles proportions il peut-être corrélé à d’autres moyennes statistiques.
Reste la particularité de l’algorithme de Tiktok qui est la question du rythme. Alors que la durée moyenne d’une vidéo TikTok est de 15 ou 16 secondes, toutes les 3, 4, 5 ou 6 secondes, donc sur des temps et des rythmes extrêmement courts, il y a une interaction, donc une documentation de notre pratique, donc une information pour l’algorithme. La vitesse de consommation est en elle-même une information. Elle fonctionne comme un arc réflexe. Chaque vidéo, chaque contenu affiché est l’équivalent du petit coup de marteau sur votre genou pour déclencher l’arc réflexe. Sauf que cette fois l’arc réflexe recherché est un arc réflexe cognitif. Cette rythmique a été copiée par les autres plateformes : Reels sur Insta, Spotlights sur Snapchat, Shorts sur Youtube.
A cette rythmique s’ajoute aussi la multiplication des points d’entrée dans les logiques de recommandation : « Pour toi » mais aussi « abonnements » (« suivis »), « amis », « lives », « explorer ».
Et une stratégie du fou, de l’irrationalité : certains contenus mis en avant disposent de chiffres de visibilité et d’engagement hallucinants (plusieurs centaines de millions de vues) alors que d’autres beaucoup plus travaillés et pertinents ne décolleront jamais. La question des métriques est par ailleurs là aussi une spécificité de TikTok qui fonctionne comme un vertige, une ivresse de notoriété : la moindre vidéo peut atteindre des nombres de vues immensément plus important que sur d’autres plateformes. Comme sur les autres plateformes, absolument rien ne permet en revanche d’authentifier la sincérité de ces métriques.
2. Les algorithmes des réseaux sociaux peuvent-ils favoriser certains types de contenus ? Le font-ils effectivement ? Si oui, selon quels facteurs et quelles modalités ? Identifiez-vous des spécificités propres au fonctionnement de TikTok ?
Dans l’absolu la réponse est oui car la nature même d’un algorithme est de trier et d’organiser l’information et les contenus. Donc de hiérarchiser. Donc d’éditorialiser (cf « Un algorithme est un éditorialiste comme les autres« ). Ce qui est plus complexe c’est de documenter finement la manière dont ils procèdent. Mais on a eu un exemple indépassable avec le rachat de Twitter par Elon Musk et la manière dont du jour au lendemain la ligne éditoriale a totalement changé (cf mon article « ouvrir le code des algorithmes ne suffit plus« ).
[Nota-Bene] J’entends le terme « d’éditorialisation » comme le définit Marcello Vitali-Rosati : « L’éditorialisation est l’ensemble des dispositifs qui permettent la structuration et la circulation du savoir. En ce sens l’éditorialisation est une production de visions du monde, ou mieux, un acte de production du réel. »
L’autre enjeu c’est de comprendre à quels intérêts ces changements correspondent ; un algorithme étant nécessairement la décision de quelqu’un d’autre, qu’est-ce qui motive ces décisions ?
- L’idéologie ? Exemples récents et récurrents de rétablissement de comptes masculinistes ou pro-avortement, prime donnée à ces contenus, etc.
- La géopolitique ? Exemples récents de contenus plutôt pro-israëliens sur Facebook après le 7 Octobre (en tout cas invisibilisation de contenus pro-palestiniens) à l’inverse de contenus plutôt pro-palestiniens sur TikTok.
- L’argent (recettes et monétisation publicitaire) ?
Un concept clé pour comprendre la favorisation de certains contenus c’est celui de la publicitarisation. La « publicitarisation » c’est une notion définie ainsi par Valérie Patrin-Leclère, enseignante au CELSA :
« une adaptation de la forme, des contenus, ainsi que d’un ensemble de pratiques professionnelles médiatiques à la nécessité d’accueillir la publicité. Cette adaptation consiste en un aménagement destiné à réduire la rupture sémiotique entre contenu éditorial et contenu publicitaire – elle se traduit, par exemple, par l’augmentation des contenus éditoriaux relevant des catégories « société » et « consommation » ou par le déploiement de formats facilitant l’intégration publicitaire, comme la « téléréalité » – mais aussi en un ménagement éditorial des acteurs économiques susceptibles d’apporter des revenus publicitaires au média (…) »
Cette publicitarisation est là encore très ancienne. Un des responsables partenariats de Google (David Eun) déclarait il y a plus de 20 ans : « Ads Are Content ». Traduction : « les publicités sont du contenu« , et par extension, « les publicités c’est le contenu« . Le résultat aujourd’hui c’est ce verbatim d’utilisateurs et d’utilisatrices pour qui « le fait que le contenu est sponsorisé n’est pas toujours explicite et même parfois volontairement dissimulé. Les publicitaires reprennent également les codes des influenceurs et les trends, ce qui floute la frontière entre une recommandation personnelle et un contenu sponsorisé. »
Concernant la dimension géopolitique ou idéologique, là où TikTok est un objet encore plus complexe c’est parce que lui-même est en quelque sorte le premier réseau social directement, presqu’ontologiquement géopolitique. Créé par la Chine, comme un facteur, vecteur, agent d’influence. Mais avec des déclinaisons différentes dans chaque pays ou zone : le TikTok Chinois n’est pas le TikTok américain qui lui-même n’est pas exactement le TikTok européen, etc.
Une autre particularité forte de l’algorithmie de TikTok (en plus de son rythme propre) c’est ce qu’on appelle le « beauty / pretty privilege » et qui fait que des phénomènes comme le SkinnyTok ont un impact majeur presqu’indépendamment du nombre d’utilisateurs actifs de la plateforme (saisine par Clara Chappaz de l’ARCOM et de la commission européenne à ce sujet). Et qui fait que certains corps (noirs, gros, trans, etc.) sont invisibilisés ou dénigrés.
Les réseaux et médias sociaux, via leurs décisions et tamis algorithmiques, sont essentiellement deux choses :
- des machines à cash
- des machines à fabriquer de la norme
Et plus il y aura de normes édictées par les médias sociaux, plus elles seront facilement suivies (public captif), plus elles seront publicitarisables, plus il y aura de cash, plus il y aura de nouveaux espaces de publicitarisation. Ad Libitum.
Et pour être ces machines à cash et à fabriquer de la norme, les algorithmes de ces plateformes ont un rapport particulier à la mémoire : ils sont structurellement dans une forme d’hypermnésie permanente (du fait de la conservation de nos historiques) mais sont conjoncturellement tout à fait capables d’amnésie lorsque cela les arrange ou le nécessite (par exemple pour nous re-proposer des contenus dont nous avons dit qu’ils ne nous intéressaient pas mais qui sont rentables pour la plateforme).
3. Quels sont les conséquences du modèle économique des réseaux sociaux et particulièrement de TikTok quant à la construction et la mise en œuvre des algorithmes utilisés ?
Ils cadrent tout. Au sens où le sociologue Erving Goffman parle des « cadres de l’expérience ».
Toute expérience humaine renvoie, selon Goffman, à un cadre donné, généralement partagé par toutes les personnes en présence ; ce cadre oriente leurs perceptions de la situation ainsi que les comportements qu’elles adoptent par rapport à elle. Ceci étant posé, l’auteur s’attache, selon son habitude, à classer les différents types de cadres, en distinguant d’abord les cadres primaires des cadres transformés. (Source)
Ces cadres vont ensuite être « modalisés », c’est à dire subir différentes transformations. Et donc la conséquence du modèle économique des réseaux sociaux c’est que la publicité, ou plus exactement la publicitarisation est la première modalisation de ce cadre d’expérience commun qu’est la navigation dans les contenus de chaque plateforme.
La publicitarisation fabrique littéralement de la consommation (au sens économique mais aussi informationnel et navigationnel), consommation qui elle-même fabrique des formes de compulsion (FOMO, etc.) qui elles-mêmes viennent nourrir et optimiser la rentabilité du cadre de la publicitarisation.
Sur ce sujet, je cite souvent l’exemple de la position des deux fondateurs du moteur de recherche Google, Serguei Brin et Larry Page; En 1998, ils publient un article scientifique pour expliquer le fonctionnement de l’algorithme Pagerank qui va révolutionner le monde de la recherche en ligne. Et dans une annexe de leur article scientifique ils écrivent :
« nous déclarons que les moteurs de recherche reposant sur un modèle économique de régie publicitaire sont biaisés de manière inhérente et très loin des besoins des utilisateurs. S’il est vrai qu’il est particulièrement difficile, même pour les experts du domaine, d’évaluer les moteurs de recherche, les biais qu’ils comportent sont particulièrement insidieux. Une nouvelle fois, le Google de ces dernières années en est un bon exemple puisque nous avons vendu à des entreprises le droit d’être listé en lien sponsorisé tout en haut de la page de résultats pour certaines requêtes. Ce type de biais est encore plus insidieux que la « simple » publicité parce qu’il masque l’intention à l’origine de l’affichage du résultat. Si nous persistons dans ce modèle économique, Google cessera d’être un moteur de recherche viable. »
Et ils concluent par :
« Mais nous croyons que le modèle publicitaire cause un nombre tellement important d’incitations biaisées qu’il est crucial de disposer d’un moteur de recherche compétitif qui soit transparent et transcrive la réalité du monde. »
On a donc des plateformes qui « ontologiquement » ont pleine conscience et connaissance de la dénaturation opérée par leur modèle de régie publicitaire mais qui passent outre à la seule fin d’une rentabilité maximale. Cela pourrait être simplement considéré comme du cynisme. Mais à l’échelle des dégâts produits à la fois dans le débat public mais aussi dans la psyché de certains des plus jeunes ou des plus fragiles, c’est de l’irresponsabilité. Et c’est pénalement condamnable. Cela devrait l’être en tout cas.
4. Quelles sont les conséquences des opinions des concepteurs des algorithmes utilisés par les réseaux sociaux, et notamment de leurs éventuels biais, dans la construction et la mise en œuvre de ces algorithmes ?
J’ai déjà répondu plus haut avec l’exemple du rachat de Twitter par Musk et dans mon article « Ouvrir le code des algorithmes ne suffit plus« . Mais on peut aussi compléter par le récent changement de Zuckerberg qui impacte directement les contenus diffusés sur Facebook. Encore une fois : il n’y a pas d’algorithmes, juste la décision de quelqu’un d’autre. Très longtemps on a refusé de le voir. Aujourd’hui, plus le monde se clive, plus les conflits sont mondialisés dans leur médiatisation, plus les plateformes sont par nature ou par intérêt des outils de Soft Power, et plus l’opinion ou l’agenda de leurs concepteurs est déterminant et cadrant.
Ce qui est très frappant aujourd’hui c’est ce qu’écrivait Kate Crawford dans son Atlas de l’IA (2021) et qui s’applique tout particulièrement aux algorithmes en tant que systèmes de pouvoir et que facteurs de puissance.
(…) il n’y a pas de boîte noire unique à ouvrir, pas de secret à révéler, mais une multitude de systèmes de pouvoir entrelacés. La transparence totale est donc un objectif impossible à atteindre. Nous parviendrons à mieux comprendre le rôle de l’IA dans le monde en nous intéressant à ses architectures matérielles, à ses environnements contextuels et aux politiques qui la façonnent, et en retraçant la manière dont ils sont reliés.
Pour les algorithmes, c’est exactement la même chose : il faut nous intéresser simultanément à leurs architectures matérielles, à leurs environnements contextuels et aux politiques qui les façonnent, et retracer la manière dont ils sont reliés. Un algorithme, aujourd’hui, n’est plus uniquement une suite d’instructions logico-mathématiques, c’est une suite de systèmes de pouvoirs entrelacés.
5. Faut-il considérer les algorithmes comme des objets statiques ? Comment un algorithme évolue-t-il ? Peut-il évoluer sans intervention humaine, en apprenant de son propre fonctionnement ? À votre connaissance, comment cela s’applique-t-il aux réseaux sociaux, et particulièrement à TikTok ?
Je reprends ici ce que j’indiquais dans mes propos liminaires. Les algorithmes sont comme des ritournelles auxquelles on s’accoutume à force de les fréquenter, que l’on retient – et que l’on maîtrise parfois – dans une forme d’intelligence situationnelle altérée par l’expérience sans cesse renouvelée de cette fréquentation. Comme la ritournelle chez Deleuze et Guattari dans leur ouvrage « Mille Plateaux », les algorithmes sont trois choses à la fois :
- D’abord ce qui nous rassure par une forme de régularité attendue, que l’on devine et anticipe.
- Ensuite ce qui installe l’organisation nous semblant familière d’un espace que l’on sait public mais que l’on perçoit et que l’on investit en partie comme intime : ils « enchantent » l’éventail de nos affects et sont l’état de nature de nos artifices sociaux.
- Enfin ils sont ce qui, parfois, nous accompagne et nous équipe aussi dans la découverte d’un ailleurs, parce qu’y compris au sein de représentations cloisonnées, ils sont des « chants traversants. »
L’algorithme de TikTok n’est pas plus intelligent, plus efficace ou plus machiavélique que d’autres ; simplement, nous passons beaucoup plus de temps à nous en occuper, et nous le faisons, du fait de sa rythmique propre, avec une fréquence beaucoup plus élevée et avec un soin sans commune mesure avec les autres. Notre rapport à l’algorithme de Tiktok relève littéralement d’une forme de clinique au sens étymologique du terme, c’est à dire emprunté au grec klinikos, « propre au médecin qui exerce son art près du lit de ses malades » (lui-même de klinê, « le lit »). Selon que nous adoptons le point de vue de la plateforme ou le notre, nous sommes le médecin ou le malade.
6. Comment les algorithmes utilisés par les réseaux sociaux, et particulièrement TikTok, s’adaptent-ils à des comportements humains parfois changeants d’un jour à l’autre ?
Par effet d’entrainement. Nous éduquons et entraînons les algorithmes au moins autant qu’ils ne nous formatent en retour. Et tout parciculièrement celui de TikTok comme je l’expliquais juste ci-dessus.
Et puis par leur rythme (cf supra). L’algorithme se moque de savoir si vous êtes de gauche aujourd’hui alors que vous étiez de droite hier, végétarien aujourd’hui alors que vous étiez végan hier. Ce qui intéresse les concepteurs de l’algorithme c’est la captation en temps réel de l’ensemble de ce qui définit votre surface informationnelle numérique. L’algorithme a pour objet de scanner en permanence et si possible en temps réel des éléments qui constituent à la fois votre surface informationnelle (ce qui vous intéresse), votre surface sociale (avec qui partagez-vous ces intérêts) et votre surface comportementale (« sur quoi » ou « avec qui » passez-vous plus ou moins de temps).
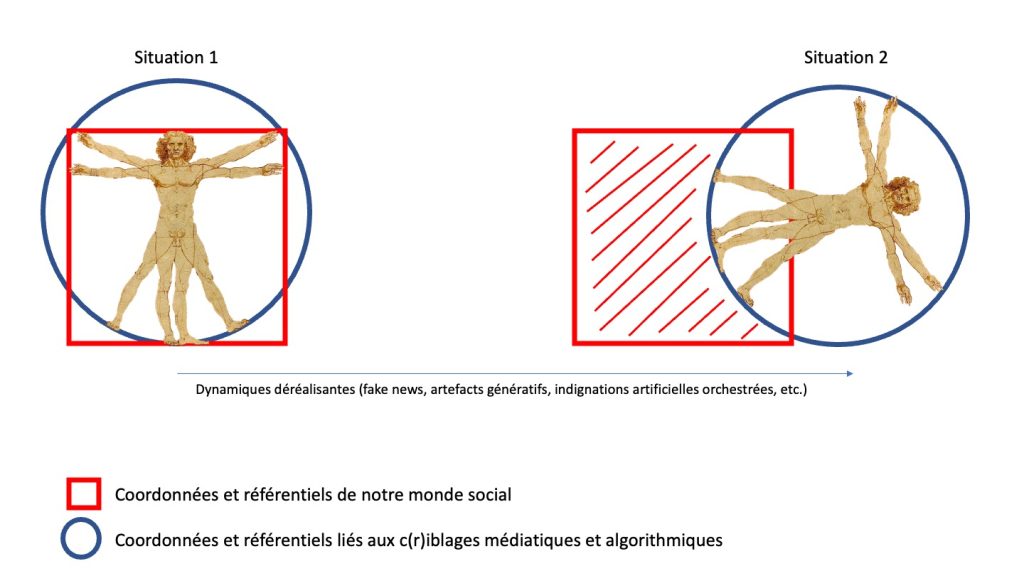
Le grand problème est d’ailleurs aussi celui de la personnalisation : c’est à dire que, sur certains types de requêtes en tout cas, plus personne ne voit la même chose en réponse à la même question (ceci vaut pour les plateformes dans lesquels on démarre la navigation par une recherche). Et pour les plateformes, comme TikTok, dans lesquelles il n’est besoin d’aucun amorçage mais uniquement de scroller, tout le monde à l’impression de voir des choses différentes (personnalisées) alors qu’en fait tout le monde voit pour l’essentiel la même chose ; mais cette « même chose » se réduit exclusivement à ce qui est bon économiquement pour la plateforme, c’est à dire soit ce qui fait le buzz et va vous obliger à réagir (polarisation émotionnelle), soit ce qui vous maintient attentionnellement captif et peut donc possiblement renforcer des troubles conatifs (« Symptômes liés à une réduction des capacités d’effort, d’initiative, et à une dégradation de la volonté et des tendances à l’action. Les formes majeures peuvent aboutir à une inactivité avec repli, parfois incurie et résistance aux sollicitations de l’entourage, voire indifférence affective.« )
Je ne sais pas si l’image vous parlera mais plutôt que l’idée des « bulles de filtres » d’Eli pariser (idée que les algorithmes enferment chacun d’entre nous dans une bulle informationnelle plus ou moins étanche) je parlais de mon côté d’un comportement d’autarcithécaires ; cette idée que, du point de vue des plateformes et de leurs algorithmes, il s’agit de nous faire croire que nous sommes en situation d’autarcie informationnelle, c’est à dire de nous donner l’impression que ce qu’elles nous donnent à voir est à la fois suffisant, complet et représentatif, précisément pour que nous perdions progressivement le besoin d’aller regarder ailleurs ou même simplement de considérer qu’il existe un ailleurs informationnel. Ou pour le dire d’une autre manière, comment nous faire passer de la peur de rater quelques chose (FOMO) à la certitude d’une non-nécessité d’aller voir ailleurs.
7. Peut-on envisager des algorithmes « éthiques », notamment eu égard aux enjeux de santé mentale ? Pouvez-vous expliquer le concept d’« informatique sociale » ?
Pour moi l’éthique algorithmique passe par le rendu public de l’ensemble des critères et métriques relevant de formes d’éditorialisation. Et pour répondre par une comparaison, bien sûr que oui, on peut tout à fait imaginer des algorithmes éthiques comme on peut imaginer des vêtements fabriquées de manière éthique, des aliments fabriqués de manière éthique et qui ne soient pas immensément transformés. La seule question est : pourquoi ne le faisons-nous pas ? Pourquoi lorsqu’il en existe parfois personne ne s’y intéresse ?
La réponse à ces questions est évidemment la même que pour l’agro-alimentaire ou les vêtements : c’est une question de coût (ce qui n’est pas éthique est moins cher) et de cadres sociétaux de consommation (où l’on minore et où l’on invisibilise les problèmes posés par cette absence d’éthique).
A chaque fois il faut des drames pour que la société parvienne à se réveiller temporairement. Comme lors de l’effondrement du Rana Plaza au Bangladesh en 2013 qui fait exploser le scandale de la fast fashion. Mais malheureusement à chaque fois au lendemain de ces réveils sociétaux il se produit deux choses : le pouvoir politique ne saisit pas l’opportunité impérieuse de légiférer, et lorsqu’il le fait, la puissance du lobbying et du pantouflage vient tout édulcorer ou tout remettre à plus tard.
En complément, il y a un point particulier d’une éthique algorithmique qui consiste à se mettre en situation (pour les plateformes), où à donner l’injonction (pour la puissance publique) de casser les chaînes de contamination virales. De ralentir. D’ajouter de la friction dans les possibilités de partage, etc. On a vu et on a documenté que cela marchait, et que les plateformes le savaient. Je cite ici, avec les exemples en lien, ce que j’écrivais en Mars 2022 dans mon article « Par-delà le Like et la colère » :
« Ensuite il faut casser les chaînes de contamination virales qui sont à l’origine de l’essentiel des problèmes de harcèlement, de désinformation, et des discours de haine dans leur globalité. Et là encore le cynisme des plateformes est aussi évident que documenté puisqu’elles ont elles-mêmes fait la démonstration, et à plusieurs reprises, que si par exemple elles diminuaient le nombre de personnes que l’on peut inviter par défaut dans les groupes Whatsapp ou le nombre de conversations et de groupes vers lesquels on peut automatiquement transférer des messages, elles diminuaient aussi considérablement la vitesse de circulation des fake news, notamment en période électorale ; que si elles supprimaient la visibilité de nombre de likes ou de réactions diverses sur un post (et que seul le créateur du post était en mesure de les voir), elles jouaient alors sur les effets souvent délétères de conformité (et de pression) sociale et qu’elles permettaient d’aller vers des logiques de partage bien plus vertueuses car essentiellement qualitatives et non plus uniquement quantitatives ; que si elles se contentaient de demander aux gens s’ils avaient bien lu l’article qu’ils s’apprêtaient à partager avant que de le faire sous le coup de l’émotion, elles diminuaient là encore la circulation de fausses informations de manière tout à fait significative. Il y a encore quelques jours, c’était Youtube qui annonçait supprimer l’affichage public du compteur des « dislikes » pour « protéger » les créateurs notamment de formes de harcèlement, un effet qu’il connaît et documente pourtant depuis déjà de longues années. »
Sur les données personnelles utilisées par les algorithmes des réseaux sociaux
8. Pouvez-vous expliquer le concept d’« identité numérique » ? Quelles données personnelles partageons-nous lorsque nous utilisons les réseaux ? Comment ces données sont-elles utilisées par les algorithmes des réseaux sociaux et particulièrement de TikTok ?
Pour reprendre, en l’actualisant, la définition que j’en donnais dans mon ouvrage éponyme paru en 2013, je dirai que :
L’identité numérique peut être définie comme la collection des traces (écrits, contenus audios ou vidéos, messages sur des forums, identifiants de connexion, navigations, éléments d’interactions, etc.) que nous laissons derrière nous, consciemment ou inconsciemment, au fil de nos activités connectées, et le reflet de cet ensemble de traces tel qu’il apparaît « remixé » par les moteurs de recherche ainsi que par les médias et les plateformes sociales, et qui sont autant d’éléments en capacité de nourrir des choix algorithmiques visant à mieux cibler les contenus qui nous seront proposés dans le cadre du modèle économique de la plateforme concernée.
(version actualisée de Ertzscheid, Olivier. Qu’est-ce que l’identité numérique ?. OpenEdition Press, 2013, https://doi.org/10.4000/books.oep.332.)
9. Est-il possible de limiter ce partage de données personnelles ? Est-il possible et souhaitable d’en limiter la collecte, par exemple par le paramétrage des réseaux sociaux ?
Concernant la première partie de la question (est-il possible d’en limiter le partage), et pour autant qu’elle s’adresse aux utilisateurs et utilisatrices de ces plateformes, je réponds oui pour les données personnelles « déclaratives » (nous pouvons disposer d’un tamis plus ou moins large). Mais je réponds « non » pour les données personnelles qui relèvent de la sphère comportementale (ce que l’on voit, ce avec quoi l’on interagit, etc.).
Si la question s’adresse aux plateformes, alors là c’est un oui pour les données personnelles déclaratives comme pour les données comportementales. Elles sont tout à fait en capacité d’en limiter la collecte (mais cela vient heurter leur modèle publicitaire) et sont tout autant en capacité d’en limiter les usages dans le temps.
Le problème principal tient au statut discursif ou énonciatif de l’ensemble de ce qui circule, se dit et se voit dans ces plateformes ou applications : nous ne savons jamais réellement si nous sommes dans un espace discursif ou médiatique intime (où il serait OK et parfois nécessaire de partager ces données personnelles), privé, ou public. Dès 2007, trois ans après le lancement de Facebook, danah boyd indiquait que le problème des réseaux sociaux est qu’ils étaient des espaces semi-publics et semi-privés (« la privauté de ces espaces publics ou semi-publics pose problème« ). Ce problème n’a jamais été résolu.
L’autre problème (et la grande responsabilité des plateformes) c’est qu’elles changent en permanence et sous plein de prétextes différents, le réglage de nos paramètres de confidentialité ou de navigation. Et qu’elles complexifient, par défaut, la possibilité de limiter ce partage de données personnelles (dark patterns, etc.)
Sur la deuxième partie de la question (est-ce possible et souhaitable de limiter cette collecte), je réponds que c’est possible, que c’est souhaitable, et que c’est, surtout, absolument nécessaire.
Il y a un grand récit marketing et technologique qui nous fait croire que plus on collecte de données personnelles, et plus on peut nous proposer de l’information et des contenus personnalisés, et plus ce serait donc intéressant pour nous. C’est une vaste et totale fumisterie. Le seul récit qui vaille est le suivant : plus on collecte de données personnelles, plus on propose des contenus personnalisés, plus on ne fait que « publicitariser » les expériences navigationnelles et informationnelles, et plus on efface la notion de référent commun sur tout un ensemble de sujets, plus on saborde à l’échelle d’une société la question des « régimes de vérité » (cf Foucault ci-dessous), et plus on crée donc à la fois de l’isolement, du conflit, et de la défiance.
« Chaque société a son régime de vérité, sa politique générale de la vérité : c’est-à-dire les types de discours qu’elle accueille et fait fonctionner comme vrais ; les mécanismes et les instances qui permettent de distinguer les énoncés vrais ou faux, la manière dont on sanctionne les uns et les autres ; les techniques et les procédures qui sont valorisées pour l’obtention de la vérité ; le statut de ceux qui ont la charge de dire ce qui fonctionne comme vrai. » Michel Foucault
Longtemps la « personnalisation » n’a été que thématique et déclarative. Du genre : je préfère l’actualité sportive à l’actualité politique, et dans l’actualité sportive, je préfère le rugby au foot. Dès que la personnalisation a gommé cette dimension déclarative explicite, dès qu’elle a surtout été indexée sur nos propres croyances, comportements et opinions plutôt que sur des médias aux formes et aux pratiques d’éditorialisation transparentes, elle est devenue un instrument purement marketing avec un impact politique massivement délétère.
Sur la transparence des réseaux sociaux
10. Pensez-vous qu’il soit possible d’exiger des réseaux sociaux d’être entièrement transparents sur leur fonctionnement et les algorithmes qu’ils utilisent ?
Je reprends ici une partie de mes propos liminaires. Oui il est possible de l’exiger. En tout cas sur la partie éditoriale, cela me semble nécessaire de l’exiger. En définissant le périmètre de cette éditorialisation pour éviter qu’elle ne puisse être totalement instrumentalisée (par exemple si tout le monde sait qu’un like vaut 1 point et qu’une colère vaut 5 points, nos comportements sont susceptibles de changer mais pour autant il est impératif que chacun sache combien « vaut » chaque type d’interaction mobilisée).
Mais plus fondamentalement nous parlons d’outils qui ont totalement explosé le cadre anthropologique de la communications entre les êtres humains. On peut se parler à distance, en absence, à la fois à plusieurs et en dialogue, en multimodalité, via des avatars, etc.
Et d’outils qui touchent chaque jour et de manière récurrente davantage de monde que jamais aucun média n’a jamais été en capacité d’en toucher et ce dans toute l’histoire de l’humanité. Ce ne sont pas seulement des médias de masse mais des médias d’hyper-masse.
Et enfin il y a la question du rythme, de la fragmentation et de la séquentialité hypercourte : notre cerveau n’est pas fait, n’est pas calibré pour s’informer par tranches de 6 à 15 secondes en passant d’un sujet à un autre.
Cette triple révolution anthropologique de la communication ne peut s’accommoder de demi-mesures ou de clairs-obscurs législatifs et réglementaires. A fortiori lorsque la mauvaise foi, la duperie et la tromperie de ces plateformes a été démontrée et documentée à de très nombreuses reprises, grâce notamment aux lanceurs et lanceuses d’alertes.
Et a fortiori encore dans un monde où elles sont devenus totalement indissociables de pouvoirs politiques qu’elles servent toujours par intérêt (soit pour échapper à des régulations, soit pour jouir de financements publics, soit pour tuer la concurrence comme le documentent encore les actuelles actions en justice contre Google et Meta notamment).
11. Est-on en mesure de contrôler cette transparence ? Comment, tant au niveau européen qu’au niveau français ?
Nous n’avons aujourd’hui plus besoin de produire des textes, lois et règlements. Nous avons besoin de faire appliquer ceux qui existent déjà (DSA, DMA, RGPD). Et d’organiser un cadre politique dans lequel la main de l’exécutif ne tremblera pas. Par exemple au titre de l’application du DSA, Twitter devenu X aurait pu et probablement dû être au moins temporairement fermé et interdit à l’échelle européenne (il l’a été au Brésil pendant plusieurs mois).
Nous sommes aujourd’hui pour la régulation de ces mass média en plein paradoxe de la tolérance tel qu’exprimé par Popper. A force d’être tolérants y compris avec les intolérants, nous courrons droit dans le mur. [« Popper affirme que si une société est tolérante sans limite, sa capacité à être tolérante est finalement détruite par l’intolérant. Il la décrit comme l’idée apparemment paradoxale que « pour maintenir une société tolérante, la société doit être intolérante à l’intolérance. » Wikipedia]
Il faut à ce titre aussi exiger des plateformes qu’elles appliquent leurs propres règles, et par exemple ne traitent pas différemment leurs « power users » car à ce jour ces plateformes, toutes ces plateformes, ont d’abord un immense problème de démocratie interne.
12. Les apports du DSA sont-ils suffisants ?
Oui pour autant qu’il y ait la volonté politique de l’appliquer en chacun de ses termes.
13. Est-ce techniquement possible, a minima, d’exiger des réseaux sociaux des garanties que leurs algorithmes ne comprennent pas de biais susceptibles d’avoir des conséquences néfastes (sur-représentation de contenus dangereux pour la santé mentale, propagation de fake news, discriminations, etc) ?
Je crois qu’on se trompe en plaçant cette question sous l’angle « technique ». Ce n’est pas à la « technique » d’arbitrer des questions qui relèvent de la santé publique ou de l’éthique. Je me permets une comparaison. Se poserait-on la question de savoir s’il est possible « techniquement » d’exiger d’une bibliothèque que son plan de classement de comprenne pas de biais ? Non. Parce que le problème ce n’est pas le plan de classement, ce sont les unités documentaires que l’on choisit de classer, donc de donner à voir, ou de ne pas classer. Les plateformes et leurs algorithmes sont « techniquement » en pleine capacité de faire respecter des règles a minima de représentativité sur un ensemble de sujets, y compris politiques, religieux ou sociétaux. Jamais en réalité nous n’avons disposé d’outils aussi puissants et aussi précis pour y parvenir. Si les plateformes (et leurs algorithmes) ne le font pas ce n’est en rien un problème technique. En rien. C’est un problème de choix économiques (business first). Et d’idéologies et d’interêts partisans (ou cyniquement opportunistes) de leurs propriétaires et de leurs actionnariats.
14. Quelle méthodologie utilisez-vous pour étudier les algorithmes utilisés par les réseaux sociaux, et particulièrement TikTok ? Quelles difficultés rencontrez-vous ? Que signifierait, pour le monde de la recherche, la publicité des algorithmes utilisés par les réseaux sociaux ?
A titre personnel, dans mon domaine de recherche, soit on procède par enquête sociologique, soit par observation participante. Comme les sociologues allaient à l’usine pour documenter au plus près le travail concret des ouvriers, on va « aux algorithmes » pour documenter au plus près leurs effets.
Un des grands sujets de notre temps, c’est que nous avons perdu la maîtrise des corpus. Quand je dis « nous » je parle du monde universitaire et donc ensuite du monde de la décision politique. Tous les programmes partenariaux publics permettant à des universitaires d’avoir accès à l’immensité des corpus détenus par les plateformes, tous ces programmes partenariaux ont été fermés. La plupart des API supprimées. L’opacité, hier sur les algorithmes, aujourd’hui sur les données, est absolument totale. Et nous en sommes réduits à faire confiance aux chercheurs employés par ces plateformes (mauvaise idée), ou à attendre la prochaine fuite d’un repenti ou d’une lanceuse d’alerte (encore plus mauvaise idée). La puissance publique, les chercheurs et universitaires de la puissance publique, n’ont plus aucune entrée ou maîtrise des corpus (linguistiques, sociologiques, etc) qui circulent dans ces plateformes et qui les constituent. Et c’est non seulement très inquiétant, mais c’est surtout très inacceptable.
Sur l’éducation aux réseaux sociaux
15. Le grand public est-il familiarisé avec le fonctionnement des algorithmes, et particulièrement de ceux utilisés par les réseaux sociaux ? Adapte-t-il son comportement en conséquence ?
Les travaux existants montrent qu’en effet, lorsqu’un fonctionnement algorithmique est suffisamment connu on a tendance à l’intégrer à notre pratique. Et en général les plateformes mettent donc en place des dispositifs pour contrer ces usages « non naturels » (exemple du Google Bombing). Aujourd’hui, même en connaissant certains « tips » agorithmiques, on ne s’en affranchit pas automatiquement. Et il est beaucoup plus difficile de connaître ou de tricher avec la « totalité » d’un algorithme aujourd’hui que cela ne l’était hier.
Par ailleurs, y compris les ingénieurs qui développent ces algorithmes sont de moins en moins nombreux à en connaître la totalité des fonctionnements. Et la capacité de tourner à plein sans supervision humaine des ces algorithmes n’a jamais cessé d’augmenter. Et cela ne vas pas s’arranger. Récemment le CEO de Google, Sundar Pinchai, confiait qu’environ 30% de l’ensemble du « code » informatique utilisé par l’ensemble des produits de la société Alphabet (maison mère de Google, Youtube, etc) était directement produite par des IA.
Quand à notre comportement adaptatif, il demeure très relatif. Nous ne l’adaptons que dans la mesure où nous avons l’impression que cette adaptation va servir directement (et rapidement) nos intérêts immédiats. Sur le reste, nous sommes plutôt d’une passivité totale, nous nous laissons algorithmiser parce que tout est fait pour fausser notre perception de la balance bénéfices / risques.
16. Pensez-vous que les enfants et adolescents soient suffisamment outillés, notamment par leurs établissements scolaires, pour se protéger des risques que ces algorithmes présentent ? Pensez-vous que les parents soient suffisamment outillés pour en protéger leurs enfants ?
La question de l’accompagnement aux écrans est une question … complexe. Ce que les jeunes et adolescents cherchent dans ces espaces (cf notamment les travaux de danah boyd aux USA ou d’Anne Cordier en France) ce sont des espaces qui soient transgressifs, la première transgression étant cette d’être à l’abri du regard des parents et des adultes. Les espaces numériques sont aussi ces alcôves algorithmiques qui permettent à la fois de se mettre à l’abri (du regard de l’adulte), d’être ensemble (y compris parfois « seuls ensemble » comme l’explique Shirley Turckle), et d’être dans la transgression autant que dans la construction d’un intime. Et cela est tout à fait normal et ne doit sous aucun prétexte être condamné ou, pire, criminalisé. Le problème, le seul et le grand problème, c’est que la construction de cet intime est toujours scruté par des autorités qui ne sont plus « parentales » mais industrielles.
Bonne nouvelle : on observe déjà et très largement des pratiques de « sevrage » temporaire mises en place par les adolescents et jeunes adultes. Cela peut-être à l’approche d’un examen à la fac, du bac français, etc. Pratiques où ils et elles désinstallent temporairement l’application de leur smartphone. Cela veut dire (pour ces publics) qu’une bonne partie du travail de pédagogie est déjà fait. Il faut ensuite trouver un effet cliquet, qui permette d’éviter de délétères retours en arrière. Et c’est bien là le rôle de la puissance publique.
Rappeler aussi que l’enjeu n’est et ne doit pas être d’interdire les écrans, mais de disposer, dans le cadre de l’organisation de notre vie sociale, éducative, publique et citoyenne, d’espaces qui demeurent des espaces non nécessairement déconnectés ou sans écrans, mais à tout le moins sans écrans et connexions qui ne soient autres que collectives ou a minima duales.
A ce titre oui, je suis convaincu par exemple qu’à l’école et au collège, les smartphones devraient être totalement interdits, dans les cours (de récréation) comme en cours. Et vous savez quoi ? Accrochez-vous bien. BINGO. C’est déjà le cas
Et qu’au lycée et même à l’université, ils devraient continuer de l’être pendant les cours. Mais qu’il n’est pour cela ni utile ni nécessaire de passer par la loi. C’est à chaque enseignante ou enseignant et éventuellement à chaque université ou composante de le décider et surtout, surtout, surtout, de l’expliquer. Parce qu’il ne s’agit pas de faire oeuvre de censure ou de police. Mais parce que si l’on considère que la transmission de savoirs tout comme l’acquisition des sociabilités primaires et fondamentales, passe par un pacte attentionnel minimal aux autres et à celui ou celle en charge de vous les transmettre et de vous les faire acquérir, alors il faut aussi accepter que celui ou celle qui est en charge de cela, quelque soit son talent et sa détermination, ne sera jamais, absolument jamais, en situation de rivaliser attentionnellement avec un objet technologique qui contient à lui seul tous les savoirs et toutes les sociabilités du monde.
Rappeler aussi que la question de la santé mentale, notamment chez les jeunes, est toujours, toujours multi-factorielle : elle tient à la fois à des paramètres éducatifs, culturels, familiaux, économiques. Donc il peut y avoir aussi bien des corrélations que, dans certains contextes, des causalités entre l’usage de TikTok et les questions de santé mentale. Mais si l’on veut s’attaquer (et il le faut) aux questions de santé mentale qui affectent désormais de manière alarmante des générations entières, alors il faut aussi et surtout traiter la question des politiques de santé publiques.
Rappeler enfin qu’il existe des métiers (professeurs documentalistes) et des organismes (CLEMI) qui font ce travail formidable au long cours. Il faut en créer davantage et leur donner des moyens sans aucune commune mesure avec ceux actuels.
Questions générales
17. De quels mécanismes de contrôle étrangers la France ou l’Europe devraient-elles, d’après-vous, s’inspirer ?
Je crois avoir déjà répondu plus haut que nous disposions de suffisamment de textes et règlements à l’échelle Européenne. Et qu’il reste à les appliquer entièrement.
18. Avez-vous des recommandations à transmettre à la commission d’enquête ?
Ma première recommandation est un avertissement que je reprends de mes propos liminaires et d’un article que j’avais publié.
« Après les mensonges de l’industrie du tabac sur sa responsabilité dans la conduite vers la mort de centaines de millions de personnes, après les mensonges de l’industrie du pétrole sur sa responsabilité dans le dérèglement climatique, nous faisons face aujourd’hui au troisième grand mensonge de notre modernité. Et ce mensonge est celui des industries extractivistes de l’information, sous toutes leurs formes.
Nous avons aimé croire que le calcul intensif se ferait sans travail intensif, que le Data Mining ne nécessiterait pas de mineurs de fond, que l’informatique en nuage (Cloud Computing) ne dissimulait pas la réalité d’une industrie lourde. Nous ne pouvons plus aujourd’hui nous réfugier dans ces mensonges. Sur les industries extractivistes de l’information, nous avons l’avantage d’en connaître déjà les mécanismes et les routines ; la chance d’en observer les infrastructures de marché (du Cloud Computing au High Frequency Trading en passant par la précarisation des différentes formes de Digital Labor) ; la chance d’être capables de documenter la toxicité de ces prismes dans le cadre de certains sujets de société ; la chance d’avoir pu documenter et prouver à de trop nombreuses reprises l’insincérité fondamentale et aujourd’hui fondatrice de toutes ces plateformes et de leurs créateurs et administrateurs. Et même s’ils s’inscrivent, comme je le rappelais plus haut, dans un écosystème médiatique, économique et politique bien plus vaste qu’eux, leur part émergée, c’est à dire les médias sociaux, sont aujourd’hui pour l’essentiel de même nature que la publicité et le lobbying le furent pour l’industrie du tabac et du pétrole : des outils au service d’une diversion elle-même au service d’une perversion qui n’est alimentée que par la recherche permanente du profit. »
Pour le dire en d’autres termes, connaître la recette exacte du Coca-Cola ne change rien au phénomène de l’obésité : la seule chose qui compte c’est de se doter de politiques de santé publique qui éduquent, régulent, contraignent et qui dépublicitarisent, qui démonétisent symboliquement ce qu’est et ce que représente le Coca-Cola.
De la même manière, connaître l’impact du pétrole sur le réchauffement climatique et la part qu’y jouent nos modes de transport et les industriels extractivistes ne changera rien à l’avenir de la planète si l’on n’a pas de politique publiques sur l’écologie capable de proposer des alternatives aux premiers mais aussi de contraindre les seconds, et là encore de dépublicitariser, de démonétiser tout cela.
Pour les algorithmes, y compris et a fortiori pour celui de TikTok, c’est exactement la même chose : connaître son mode exact de fonctionnement ne changera rien aux errances et aux effondrements affectifs, psychologiques, conatifs, informationnels qu’il alimente. Il nous faut des politiques publiques du numérique. Dont des politiques de santé publique numérique.
Et il faut davantage de postes de professeurs documentalistes dans les lycées et collèges, avec davantage d’heures de cours dédiées à la culture numérique. Et aussi il faut financer et multiplier les structures et opérateurs comme le CLEMI. Oui je l’ai déjà dit. Mais oui je le redis. Et le redirai sans cesse.
[Verbatim étudiantes et étudiants]
L’échantillon est d’une petite soixantaine d’étudiantes et d’étudiants, en 1ère année de BUT Information et Communication (donc en gros âgés de 18 ou 19 ans) et avec qui j’ai déjà effectué quelques heures de cours autour des questions de culture numérique, de l’histoire d’internet et du web, et aussi un peu des enjeux sociétaux des algorithmes. La seule consigne donnée était de partir de leur expérience personnelle de la plateforme pour répondre aux questions de la commmission.
De manière générale ils et elles soulignent l’importance (et le manque) de politiques de santé publique et de communication, dans l’espace public, sur ce sujet.
- « On voir rarement de campagne de prévention dans l’espace public sur le lien entre utilisation RS et questions de santé mentale, alors même que jamais les jeunes n’ont autant parlé de l’importance et de la fragilité de la santé mentale«
- « il faut renforcer la communication publique, notamment dans le cadre scolaire«
Ils et elles soulignent également l’importance de faire à ces sujets davantage de place au collège et au lycée et surtout, d’en parler autrement que sous le seul angle de la culpabilisation ou des dérives comme le cyberharcèlement.
- « tout le monde accuse tiktok d’être dangereux mais personne ne parle réellement des risques qui y sont associés et comment on s’en protège«
- « intégrer ces questions dans les machins genre Pix«
- « la plupart du temps, au lycée ou au collègue, ces plateformes ne sont abordées que sous l’angle du cyberharcèlement, mais jamais sous l’angle des algorithmes, de leur côté addictif, chronophage, démotivant« .
Ils et elles ont aussi une grande maturité sur la nécessité d’un contrôle d’accès réel avec une vérification de l’âge qui soit autre chose qu’un bouton « oui promis j’ai 18 ans » :
- « faire un vrai contrôle d’accès selon l’âge, comme sur blablacar avec présentation d’un document d’identité«
Ils et elles ont des idées très concrètes de ce qu’il faudrait obliger Tiktok (et d’autres plateformes) à mettre en place :
- « obliger TikTok à implémenter des fonctionnalités permettant de mieux gérer le temps d’écran et à sensibiliser ses utilisateurs aux risques d’une utilisation excessive«
- « être plus à l’écoute des signalements. Et plus vigilants sur les contenus de type suicide : personne n’aime regarder des vidéos de suicide (ou de comment se suicider) et personne ne devrait se voir recommander des vidéos comme ça«
J’ai enfin été particulièrement frappé, dans leurs verbatims, d’une large majorité qui indique explicitement que les impacts et effets négatifs sur leur humeur sont plus importants que les aspects positifs. Et de la manière dont ils documentent et analysent cela. Le verbatim ci-dessous résume très bien ce que j’ai lu dans beaucoup de leurs réponses individuelles :
- « À titre personnel, tik tok a plus d’impact négatif que positif. En effet, une fois que je suis sur l’application, il m’est presque impossible de réguler mon temps passé sur cette
dernière. Une heure est ressentie comme 15 minutes et arrêter de scroller est très compliqué. De plus, lorsque mon application est active, l’heure ne s’affiche plus sur mon écran, ce qui biaise encore plus mon rapport au temps. Ce temps passé sur tik tok est perdu pour faire d’autre activité, et souvent, je repousse les tâches que j’ai à faire. Après avoir passé plusieurs heures sur tik tok je culpabilise énormément et me sens mal. J’ai remarqué que mon moral était affecté par mon utilisation de tik tok, plus je passe de temps à scroller moins je suis de bonne humeur.«
[Et puis soudain Gabriel Attal]
Voilà je m’apprêtais à demander à ChatGPT une version synthétique de ce long texte en extrayant les éléments mobilisables immédiatement dans le cadre d’une proposition de loi et puis soudain, je tombe sur plusieurs éléments complémentaires.
Premier élément : Gabriel Attal. Qui s’allie au pédopsychiatre Marcel Ruffo pour proposer des mesures qui sont, pour l’essentiel, des caricatures au carré. Caricature d’une pensée magique où tout est, sans indistinction, la faute aux écrans et où leur suppression guérirait donc tous les maux, et où toute cette faute mériterait donc des régimes disciplinaires qui sont autant imbéciles qu’inapplicables et dangereux en démocratie. Voici donc ce qu’ils proposent :
- une évaluation de l’addiction aux écrans de chaque jeune à l’entrée en sixième et en seconde.
- interdire l’accès des moins de 15 ans aux réseaux sociaux (et imposer une vérification d’âge sur ces plateformes).
- imposer un couvre-feu pour les 15-18 ans qui bloque l’accès aux réseaux sociaux entre 22h et 8h.
- faire passer l’écran en noir et blanc, pendant au moins une heure, après 30 minutes d’utilisation.
- création d’un “addict-score” (sur le modèle du nutri-score) pour mesurer le potentiel addictif des plateformes.
- créer une taxe de 2 % qui financerait la recherche et la prise en charge de la santé mentale.
J’ai donc immédiatement réfléchi à une critériologie assez fine permettant de caractériser chaque mesure proposée. Critériologie que voici :
- « C’est complètement con » : 3C
- « Inapplicable et Imbécile » : 2I.
- « Pourquoi pas mais surtout … pourquoi ? » : 3P.
Revoici maintenant ces mesures à l’aune de mon analyse subtile.
- une évaluation de l’addiction aux écrans de chaque jeune à l’entrée en sixième et en seconde : 3P
- interdire l’accès des moins de 15 ans aux réseaux sociaux : 3C2I
- imposer un couvre-feu pour les 15-18 ans qui bloque l’accès aux réseaux sociaux entre 22h et 8h : 3C2I
- faire passer l’écran en noir et blanc, pendant au moins une heure, après 30 minutes d’utilisation. 3C3P
- création d’un “addict-score” (sur le modèle du nutri-score) pour mesurer le potentiel addictif des plateformes. 3P
Je ne retiens donc que deux mesures :
- « imposer une vérification d’âge sur ces plateformes. » Mais certainement pas pour « interdire » l’accès mais pour responsabiliser les plateformes qui organisent cet accès et font absolument n’importe quoi quelque soit l’âge réel de leurs utilisateurs et utilisatrices, âge réel que de leur côté elles sont la plupart du temps en pleine capacité de connaître (et donc d’en déduire la part d’utilisateurs et d’utilisatrices qui n’ont absolument rien à faire là puisqu’elles sont normalement interdites aux moins de 13 ans).
- « créer une taxe de 2 % qui financerait la recherche et la prise en charge de la santé mentale. » Là je dis oui, mais je dis surtout « seulement 2% ?! »
Pour le reste, je vous invite à lire la chronique et l’analyse impeccable de François Saltiel dont je partage chaque ligne et chaque mot.
Et je vous invite aussi, à chaque fois que vous entendrez diverses gesticulations politico-médiatiques sur une interdiction totale ou partielle des écrans chez les enfants et adolescents, à relire (notamment) cet article grand public et surtout de grande utilité publique d’Anne Cordier, publié en Mai 2024, et dans lequel elle rappelle la réalité de deux points fondamentaux, celui de la panique morale sur ce sujet, et celui de la réalité des études scientifiques sur ce même sujet :
Ce phénomène des paniques morales exprime une crainte quant à la déstabilisation des valeurs sociétales, et se cristallise autour des usages juvéniles desdits écrans et des conséquences de ces usages sur la santé mentale et sociale des enfants et adolescents, ainsi que sur leur développement cognitif et leur culture générale.
Pourtant une importante et robuste étude américaine, menée sur le long terme auprès de 12000 enfants entre 9 et 12 ans, conclut sans hésitation à l’absence de lien entre temps passé « devant les écrans » et incidence sur les fonctions cérébrales et le bien-être des enfants. Pourtant encore, en France, une enquête longitudinale d’envergure, déployée cette fois auprès de 18000 enfants depuis leur naissance, montre que ce sont des facteurs sociaux qui jouent un rôle prépondérant dans le développement de l’enfant.
Malgré ces faits scientifiques, le débat autour de la place desdits écrans dans notre société se polarise, et se caractérise récemment par une ultraradicalisation des postures, ce qui a pour premier effet de porter préjudice à la compréhension de tout un chacun.
Je répète : « ce sont des facteurs sociaux qui jouent un rôle prépondérant dans le développement de l’enfant. » La place et l’usage des écrans n’est que l’un de ces facteurs sociaux parmi d’autres bien plus essentiels.
[Et puis soudain le Pew Internet Research Center]
Le 22 Avril 2025 est sortie une étude du Pew Internet Research Center, pile poil sur le sujet qui nous occupe : « Teens, Social Media and Mental Health. » Elle est, comme souvent, fondamentale pour bien cerner les enjeux de ce sujet. Et j’en retire les éléments suivants.
D’abord si environ 40% émettent un avis plutôt « neutre » sur l’influence des médias sociaux sur leur santé mentale, les 60% d’adolescents restants (entre 13 et 17 ans) indiquent clairement que les effets négatifs sur leur santé mentale l’emportent sur les effets positifs.
Ensuite là où les parents considèrent que les médias sociaux sont la première cause des problèmes de santé mentale, du côté des adolescents, c’est tout autre chose : 22% des adolescents désignent les médias sociaux, 17% d’entre elles et eux les phénomènes de harcèlement (j’ai bien dit de harcèlement et pas seulement de cyber-harcèlement), et 16% les « pressures and expectations« , c’est à dire les attentes sociales et parentales vécues comme autant de pressions. Là est l’un des noeuds centraux du problème de la santé mentale des adolescentes et adolescents.
Autre point essentiel qui rend encore plus débile toute tentative d’interdiction, plus d’un tiers (34%) des adolescentes et adolescents interrogés indiquent s’informer sur les réseaux sociaux sur les questions de santé mentale. Et parmi ceux-là, plus de la moitié indiquent que c’est une source d’information importante.
Enfin, et c’est là aussi absolument déterminant pour comprendre ce qui se joue et comment le réguler, les adolescentes et adolescents identifient clairement l’impact délétère et toxiques des médias sociaux sur leur travail et leurs études, sur leur santé mentale, sur leur productivité et sur leur sommeil mais dans le même temps ils indiquent tout aussi clairement l’impact très positif sur leurs amitiés et leurs socialisations. Constat qui rejoint en effet tous les travaux universitaires sur ce point : ces espaces numériques de socialisation sont nécessaires et précieux dans la construction des identités (et des intimités) adolescentes à l’abri du regard des adultes. En revanche rien n’oblige à ce qu’ils soient traversés de contenus ne répondant qu’à des logiques commerciales et qui n’ont de considération que pour des dynamiques de viralité garantissant à tout prix des effets de rente attentionnelle. La responsabilité d’y faire le tri et le ménage et d’y injecter la dose minimale de responsabilité déontologique au regard des publics ciblés et des enjeux sociétaux concernés incombe donc entièrement aux plateformes elles-mêmes, et c’est à la puissance publique de le leur rappeler et de les y contraindre. Quoi qu’il en coûte.
One More Thing.
J’ai ensuite demandé à ChatGPT, sur la base de ce (long) texte (celui de mes réponses à la commission), de faire une liste de 10 propositions (ou plus) concrètes dont le législateur pourrait se saisir et de reformuler ces propositions dans un format destiné à une note parlementaire ou à une présentation en commission. Je vous en livre ici le résultat.
Liste de 10 propositions pour une prochaine loi ou cadrage législatif.
[c’est ChatGPT qui parle, enfin qui écrit]
Voici une liste de dix propositions et recommandations concrètes issues du document de contribution à la commission parlementaire, que le législateur pourrait saisir pour élaborer une nouvelle loi sur le numérique et l’accès aux réseaux sociaux :
 Transparence et régulation algorithmique
Transparence et régulation algorithmique
-
Exiger la transparence des algorithmes sur leur dimension éditoriale : rendre publics les critères et pondérations qui déterminent l’affichage des contenus, notamment en lien avec les réactions émotionnelles (likes, colère, etc.).
-
Obliger les plateformes à ralentir les chaînes virales : limiter les fonctionnalités favorisant la viralité (nombre de partages simultanés, forwarding de messages, etc.) pour réduire les effets de masse sur la désinformation et le harcèlement.
-
Supprimer l’affichage public de certaines métriques (likes, vues, dislikes) pour atténuer les effets de conformité sociale et limiter les impacts délétères sur la santé mentale.
 Santé publique et usage responsable
Santé publique et usage responsable
-
Instaurer des mécanismes de contrôle d’accès efficaces pour les mineurs (vérification d’identité, seuils d’âge vérifiés comme sur Blablacar), en évitant les simples déclarations « j’ai plus de 13/18 ans ».
-
Imposer des limites d’usage paramétrables par défaut (temps d’écran, alertes de dépassement, pause obligatoire après un temps de scroll continu) intégrées directement dans les applications.
-
Créer une politique de santé publique numérique : reconnaître les effets psychiques négatifs des réseaux sur les plus jeunes et y répondre par des campagnes nationales et des dispositifs de prévention dans les écoles et les médias.
 Éducation et formation
Éducation et formation
-
Renforcer l’éducation au numérique dès le collège : intégrer des modules spécifiques sur les algorithmes, la captation attentionnelle, les risques informationnels et les logiques économiques des plateformes.
-
Doter chaque collège et lycée d’un(e) professeur(e) documentaliste formé(e) aux enjeux numériques et augmenter leurs heures dédiées à l’éducation aux médias.
 Pouvoirs publics et contrôle
Pouvoirs publics et contrôle
-
Faire appliquer strictement les lois existantes (RGPD, DSA, DMA) : prévoir des sanctions réellement dissuasives en cas de non-conformité et ne pas hésiter à suspendre ou interdire temporairement des services comme cela a été fait ailleurs.
-
Créer un droit d’accès des chercheurs publics aux corpus algorithmiques : obliger les plateformes à ouvrir des API sécurisées permettant à la recherche indépendante d’analyser les effets sociaux, psychologiques et politiques de leurs systèmes.
La note parlementaire (faite par ChatGPT).
[c’est toujours ChatGPT qui parle, enfin qui écrit]
Voici une note parlementaire structurée présentant les propositions issues du document d’Olivier Ertzscheid, à destination d’un(e) député(e) souhaitant nourrir une réflexion législative sur le numérique et les réseaux sociaux.
Objet : Propositions pour une loi sur les usages numériques et l’accès aux réseaux sociaux
Auteur : Synthèse des travaux d’Olivier Ertzscheid, Maître de conférences en Sciences de l’information
Date : [à compléter]
Contexte général
Dans un environnement où les réseaux sociaux sont devenus des médias d’“hyper-masse”, leur impact sur les comportements, la santé mentale, la circulation de l’information et la démocratie est désormais massif, continu et documenté. L’urgence n’est plus de comprendre ces effets, mais de réguler concrètement les modèles qui les produisent. Cette note propose dix axes d’action législatifs concrets.
1. Transparence algorithmique et lutte contre la manipulation attentionnelle
1.1. Transparence des logiques éditoriales des algorithmes
Obligation pour les plateformes de rendre publics les critères et pondérations influençant la hiérarchisation des contenus (types de réactions, temps de visionnage, etc.), en particulier ceux relevant de la manipulation émotionnelle.
1.2. Ralentissement des chaînes virales
Limitation par la loi des mécanismes de partage automatisés ou massifs (groupes WhatsApp, forwardings, etc.) afin de freiner les phénomènes de désinformation, de harcèlement et de polarisation.
1.3. Encadrement des métriques visibles
Obligation pour les plateformes de masquer certains compteurs (likes, vues, partages) aux utilisateurs non-créateurs pour atténuer les effets de conformité sociale et d’addiction à la reconnaissance.
2. Santé publique et encadrement de l’usage
2.1. Vérification d’âge robuste à l’inscription
Mise en œuvre d’un dispositif réel de contrôle d’âge (type pièce d’identité) pour limiter l’accès des mineurs aux plateformes sans médiation.
2.2. Limites d’usage intégrées par défaut
Imposition à toutes les applications sociales d’une fonction de régulation du temps passé : alertes, pauses obligatoires, et tableaux de bord accessibles.
2.3. Lancement d’un plan national de santé publique numérique
Campagnes publiques et programmes éducatifs pour sensibiliser aux impacts psychologiques des réseaux sociaux, en particulier chez les jeunes.
3. Éducation aux médias et renforcement scolaire
3.1. Intégration obligatoire de modules sur les logiques des plateformes
Enseignement dès le collège sur le fonctionnement des algorithmes, la captation attentionnelle et les logiques économiques des contenus.
3.2. Déploiement renforcé de professeurs documentalistes et du CLEMI
Augmentation du nombre de professeurs documentalistes et du budget alloué au CLEMI, pour assurer un accompagnement continu et de qualité dans les établissements.
4. Régulation effective et contrôle public
4.1. Application sans compromis des règlements européens (RGPD, DSA, DMA)
Sanctions systématiques et dissuasives en cas de non-respect des règles ; possibilité d’interdiction temporaire d’un service comme dans d’autres pays (ex. X/Twitter au Brésil).
4.2. Accès aux corpus pour la recherche publique
Obligation légale pour les plateformes d’ouvrir aux chercheurs indépendants l’accès à des jeux de données anonymisés, via API, afin de permettre une évaluation scientifique indépendante des effets des algorithmes.
Conclusion
Ces propositions, réalistes, urgentes et largement documentées, peuvent constituer la base d’un cadre législatif de souveraineté numérique, de protection des jeunes publics et de régulation démocratique des puissances algorithmiques.
Argumentaire synthétique pour une intervention en commission.
Tant que j’y suis je vous livre aussi l’introduction et la conclusion du même ChatGPT lorsque je lui demande un argumentaire synthétique de sa note parlementaire pour une intervention en commission.
Introduction.
Mesdames et Messieurs les membres de la commission,
Nous sommes aujourd’hui face à des outils devenus centraux dans la vie sociale, affective, cognitive de millions de citoyens, notamment les plus jeunes. Ces outils sont à la fois des médias d’hyper-masse, des machines à fabriquer la norme et des systèmes de captation attentionnelle, dont les effets sur la santé mentale, la désinformation et les inégalités sont désormais documentés.
Il ne s’agit plus de produire des rapports ou des constats, mais d’agir, de légiférer, de protéger.
Conclusion : l’exigence du courage politique.
Ce que nous proposons n’est ni technophobe, ni moraliste. C’est une politique de santé publique, d’éducation, et de souveraineté.
Il faut démonétiser l’attention, dépublicitariser l’espace social, et remettre du sens dans nos usages.
L’histoire nous jugera comme elle a jugé ceux qui n’ont rien fait face au tabac ou au réchauffement climatique. Il est encore temps d’agir.
Voilà. Le boulot est fait de mon côté. J’ai transmis à la commission mon texte avec l’intégralité de mes réponses aux questions, et leur ai également adressé les 10 propositions pour une évolution du cadrage législatif (en précisant bien sûr qu’elles étaient formulées par ChatGPT sur la base de l’analyse de mon texte). Le reste appartient maintenant à ce truc formidable qu’on appelle la démocratie.








































{kind=link}