Dans sa dernière newsletter, Algorithm Watch revient sur une étude danoise qui a observé les effets des chatbots sur le travail auprès de 25 000 travailleurs provenant de 11 professions différentes où des chatbots sont couramment utilisés (développeurs, journalistes, professionnels RH, enseignants…). Si ces travailleurs ont noté que travailler avec les chatbots leur permettait de gagner du temps, d’améliorer la qualité de leur travail, le gain de temps s’est avéré modeste, représentant seulement
Dans sa dernière newsletter, Algorithm Watch revient sur une étude danoise qui a observé les effets des chatbots sur le travail auprès de 25 000 travailleurs provenant de 11 professions différentes où des chatbots sont couramment utilisés (développeurs, journalistes, professionnels RH, enseignants…). Si ces travailleurs ont noté que travailler avec les chatbots leur permettait de gagner du temps, d’améliorer la qualité de leur travail, le gain de temps s’est avéré modeste, représentant seulement 2,8% du total des heures de travail. La question des gains de productivité de l’IA générative dépend pour l’instant beaucoup des études réalisées, des tâches et des outils. Les gains de temps varient certes un peu selon les profils de postes (plus élevés pour les professions du marketing (6,8%) que pour les enseignants (0,2%)), mais ils restent bien modestes.”Sans flux de travail modifiés ni incitations supplémentaires, la plupart des effets positifs sont vains”.
Algorithm Watch se demande si les chatbots ne sont pas des outils de travail improductifs. Il semblerait plutôt que, comme toute transformation, elle nécessite surtout des adaptations organisationnelles ad hoc pour en développer les effets.
Dans sa dernière newsletter, Algorithm Watch revient sur une étude danoise qui a observé les effets des chatbots sur le travail auprès de 25 000 travailleurs provenant de 11 professions différentes où des chatbots sont couramment utilisés (développeurs, journalistes, professionnels RH, enseignants…). Si ces travailleurs ont noté que travailler avec les chatbots leur permettait de gagner du temps, d’améliorer la qualité de leur travail, le gain de temps s’est avéré modeste, représentant seulement
Dans sa dernière newsletter, Algorithm Watch revient sur une étude danoise qui a observé les effets des chatbots sur le travail auprès de 25 000 travailleurs provenant de 11 professions différentes où des chatbots sont couramment utilisés (développeurs, journalistes, professionnels RH, enseignants…). Si ces travailleurs ont noté que travailler avec les chatbots leur permettait de gagner du temps, d’améliorer la qualité de leur travail, le gain de temps s’est avéré modeste, représentant seulement 2,8% du total des heures de travail. La question des gains de productivité de l’IA générative dépend pour l’instant beaucoup des études réalisées, des tâches et des outils. Les gains de temps varient certes un peu selon les profils de postes (plus élevés pour les professions du marketing (6,8%) que pour les enseignants (0,2%)), mais ils restent bien modestes.”Sans flux de travail modifiés ni incitations supplémentaires, la plupart des effets positifs sont vains”.
Algorithm Watch se demande si les chatbots ne sont pas des outils de travail improductifs. Il semblerait plutôt que, comme toute transformation, elle nécessite surtout des adaptations organisationnelles ad hoc pour en développer les effets.
« J’aimerais vous confronter à un problème de calcul difficile », attaque Albert Moukheiber sur la scène de la conférence USI 2025. « Dans les sciences cognitives, on est confronté à un problème qu’on n’arrive pas à résoudre : la subjectivité ! »
Le docteur en neuroscience et psychologue clinicien, auteur de Votre cerveau vous joue des tours (Allary éditions 2019) et de Neuromania (Allary éditions, 2024), commence par faire un rapide historique de ce qu’on sait sur le cerveau.
Où est le
« J’aimerais vous confronter à un problème de calcul difficile », attaque Albert Moukheiber sur la scène de la conférence USI 2025. « Dans les sciences cognitives, on est confronté à un problème qu’on n’arrive pas à résoudre : la subjectivité ! »
Le docteur en neuroscience et psychologue clinicien, auteur de Votre cerveau vous joue des tours (Allary éditions 2019) et de Neuromania (Allary éditions, 2024), commence par faire un rapide historique de ce qu’on sait sur le cerveau.
Où est le neurone ?
« Contrairement à d’autres organes, un cerveau mort n’a rien à dire sur son fonctionnement. Et pendant très longtemps, nous n’avons pas eu d’instruments pour comprendre un cerveau ». En fait, les technologies permettant d’ausculter le cerveau, de cartographier son activité, sont assez récentes et demeurent bien peu précises. Pour cela, il faut être capable de mesurer son activité, de voir où se font les afflux d’énergie et l’activité chimique. C’est seulement assez récemment, depuis les années 1990 surtout, qu’on a développé des technologies pour étudier cette activité, avec les électro-encéphalogrammes, puis avec l’imagerie par résonance magnétique (IRM) structurelle et surtout fonctionnelle. L’IRM fonctionnelle est celle que les médecins vous prescrivent. Elle mesure la matière cérébrale permettant de créer une image en noir et blanc pour identifier des maladies, des lésions, des tumeurs. Mais elle ne dit rien de l’activité neuronale. Seule l’IRM fonctionnelle observe l’activité, mais il faut comprendre que les images que nous en produisons sont peu précises et demeurent probabilistes. Les images de l’IRMf font apparaître des couleurs sur des zones en activité, mais ces couleurs ne désignent pas nécessairement une activité forte de ces zones, ni que le reste du cerveau est inactif. L’IRMf tente de montrer que certaines zones sont plus actives que d’autres parce qu’elles sont plus alimentées en oxygène et en sang. L’IRMf fonctionne par soustraction des images passées. Le patient dont on mesure l’activité cérébrale est invité à faire une tâche en limitant au maximum toute autre activité que celle demandée et les scientifiques comparent ces images à des précédentes pour déterminer quelles zones sont affectées quand vous fermez le poing par exemple. « On applique des calculs de probabilité aux soustractions pour tenter d’isoler un signal dans un océan de bruits », précise Moukheiber dans Neuromania. L’IRMf n’est donc pas un enregistrement direct de l’activation cérébrale pour une tâche donnée, mais « une reconstruction a posteriori de la probabilité qu’une aire soit impliquée dans cette tâche ». En fait, les couleurs indiquent des probabilités. « Ces couleurs n’indiquent donc pas une intensité d’activité, mais une probabilité d’implication ». Enfin, les mesures que nous réalisons n’ont rien de précis, rappelle le chercheur. La précision de l’IRMf est le voxel, qui contient environ 5,5 millions de neurones ! Ensuite, l’IRMf capture le taux d’oxygène, alors que la circulation sanguine est bien plus lente que les échanges chimiques de nos neurones. Enfin, le traitement de données est particulièrement complexe. Une étude a chargé plusieurs équipes d’analyser un même ensemble de données d’IRMf et n’a pas conduit aux mêmes résultats selon les équipes. Bref, pour le dire simplement, le neurone est l’unité de base de compréhension de notre cerveau, mais nos outils ne nous permettent pas de le mesurer. Il faut dire qu’il n’est pas non plus le bon niveau explicatif. Les explications établies à partir d’images issues de l’IRMf nous donnent donc plus une illusion de connaissance réelle qu’autre chose. D’où l’enjeu à prendre les résultats de nombre d’études qui s’appuient sur ces images avec beaucoup de recul. « On peut faire dire beaucoup de choses à l’imagerie cérébrale » et c’est assurément ce qui explique qu’elle soit si utilisée.
Les données ne suffisent pas
Dans les années 50-60, le courant de la cybernétique pensait le cerveau comme un organe de traitement de l’information, qu’on devrait étudier comme d’autres machines. C’est la naissance de la neuroscience computationnelle qui tente de modéliser le cerveau à l’image des machines. Outre les travaux de John von Neumann, Claude Shannon prolonge ces idées d’une théorie de l’information qui va permettre de créer des « neurones artificiels », qui ne portent ce nom que parce qu’ils ont été créés pour fonctionner sur le modèle d’un neurone. En 1957, le Perceptron de Frank Rosenblatt est considéré comme la première machine à utiliser un réseau neuronal artificiel. Mais on a bien plus appliqué le lexique du cerveau aux ordinateurs qu’autre chose, rappelle Albert Moukheiber.
Aujourd’hui, l’Intelligence artificielle et ses « réseaux de neurones » n’a plus rien à voir avec la façon dont fonctionne le cerveau, mais les neurosciences computationnelles, elles continuent, notamment pour aider à faire des prothèses adaptées comme les BCI, Brain Computer Interfaces.
Désormais, faire de la science consiste à essayer de comprendre comment fonctionne le monde naturel depuis un modèle. Jusqu’à récemment, on pensait qu’il fallait des théories pour savoir quoi faire des données, mais depuis l’avènement des traitements probabilistes et du Big Data, les modèles théoriques sont devenus inutiles, comme l’expliquait Chris Anderson dans The End of Theory en 2008. En 2017, des chercheurs se sont tout de même demandé si l’on pouvait renverser l’analogie cerveau-ordinateur en tentant de comprendre le fonctionnement d’un microprocesseur depuis les outils des neurosciences. Malgré l’arsenal d’outils à leur disposition, les chercheurs qui s’y sont essayé ont été incapables de produire un modèle de son fonctionnement. Cela nous montre que comprendre un fonctionnement ne nécessite pas seulement des informations techniques ou des données, mais avant tout des concepts pour les organiser. En fait, avoir accès à une quantité illimitée de données ne suffit pas à comprendre ni le processeur ni le cerveau. En 1974, le philosophe des sciences, Thomas Nagel, avait proposé une expérience de pensée avec son article « Quel effet ça fait d’être une chauve-souris ? ». Même si l’on connaissait tout d’une chauve-souris, on ne pourra jamais savoir ce que ça fait d’être une chauve-souris. Cela signifie qu’on ne peut jamais atteindre la vie intérieure d’autrui. Que la subjectivité des autres nous échappe toujours. C’est là le difficile problème de la conscience.
Albert Moukheiber sur la scène d’USI 2025.
La subjectivité nous échappe
Une émotion désigne trois choses distinctes, rappelle Albert Moukheiber. C’est un état biologique qu’on peut tenter d’objectiver en trouvant des modalités de mesure, comme le tonus musculaire. C’est un concept culturel qui a des ancrages et valeurs très différentes d’une culture l’autre. Mais c’est aussi et d’abord un ressenti subjectif. Ainsi, par exemple, le fait de se sentir triste n’est pas mesurable. « On peut parfaitement comprendre le cortex moteur et visuel, mais on ne comprend pas nécessairement ce qu’éprouve le narrateur de Proust quand il mange la fameuse madeleine. Dix personnes peuvent être émues par un même coucher de soleil, mais sont-elles émues de la même manière ? »
Notre réductionnisme objectivant est là confronté à des situations qu’il est difficile de mesurer. Ce qui n’est pas sans poser problèmes, notamment dans le monde de l’entreprise comme dans celui de la santé mentale.
Le monde de l’entreprise a créé d’innombrables indicateurs pour tenter de mesurer la performance des salariés et collaborateurs. Il n’est pas le seul, s’amuse le chercheur sur scène. Les notes des étudiants leurs rappellent que le but est de réussir les examens plus que d’apprendre. C’est la logique de la loi de Goodhart : quand la mesure devient la cible, elle n’est plus une bonne mesure. Pour obtenir des bonus financiers liés au nombre d’opérations réussies, les chirurgiens réalisent bien plus d’opérations faciles que de compliquées. Quand on mesure les humains, ils ont tendance à modifier leur comportement pour se conformer à la mesure, ce qui n’est pas sans effets rebond, à l’image du célèbre effet cobra, où le régime colonial britannique offrit une prime aux habitants de Delhi qui rapporteraient des cobras morts pour les éradiquer, mais qui a poussé à leur démultiplication pour toucher la prime. En entreprises, nombre de mesures réalisées perdent ainsi très vite de leur effectivité. Moukheiber rappelle que les innombrables tests de personnalité ne valent pas mieux qu’un horoscope. L’un des tests le plus utilisé reste le MBTI qui a été développé dans les années 30 par des personnes sans aucune formation en psychologie. Non seulement ces tests n’ont aucun cadre théorique (voir ce que nous en disait le psychologue Alexandre Saint-Jevin, il y a quelques années), mais surtout, « ce sont nos croyances qui sont déphasées. Beaucoup de personnes pensent que la personnalité des individus serait centrale dans le cadre professionnel. C’est oublier que Steve Jobs était surtout un bel enfoiré ! », comme nombre de ces « grands » entrepreneurs que trop de gens portent aux nues. Comme nous le rappelions nous-mêmes, la recherche montre en effet que les tests de personnalités peinent à mesurer la performance au travail et que celle-ci a d’ailleurs peu à voir avec la personnalité. « Ces tests nous demandent d’y répondre personnellement, quand ce devrait être d’abord à nos collègues de les passer pour nous », ironiseMoukheiber. Ils supposent surtout que la personnalité serait « stable », ce qui n’est certainement pas si vrai. Enfin, ces tests oublient que bien d’autres facteurs ont peut-être bien plus d’importance que la personnalité : les compétences, le fait de bien s’entendre avec les autres, le niveau de rémunération, le cadre de travail… Mais surtout, ils ont tous un effet « barnum » : n’importe qui est capable de se reconnaître dedans. Dans ces tests, les résultats sont toujours positifs, même les gens les plus sadiques seront flattés des résultats. Bref, vous pouvez les passer à la broyeuse.
Dans le domaine de la santé mentale, la mesure de la subjectivité est très difficile et son absence très handicapante. La santé mentale est souvent vue comme une discipline objectivable, comme le reste de la santé. Le modèle biomédical repose sur l’idée qu’il suffit d’ôter le pathogène pour aller mieux. Il suffirait alors d’enlever les troubles mentaux pour enlever le pathogène. Bien sûr, ce n’est pas le cas. « Imaginez un moment, vous êtes une femme brillante de 45 ans, star montante de son domaine, travaillant dans une entreprise où vous êtes très valorisée. Vous êtes débauché par la concurrence, une entreprise encore plus brillante où vous allez pouvoir briller encore plus. Mais voilà, vous y subissez des remarques sexistes permanentes, tant et si bien que vous vous sentez moins bien, que vous perdez confiance, que vous développez un trouble anxieux. On va alors pousser la personne à se soigner… Mais le pathogène n’est ici pas en elle, il est dans son environnement. N’est-ce pas ici ses collègues qu’il faudrait pousser à se faire soigner ? »
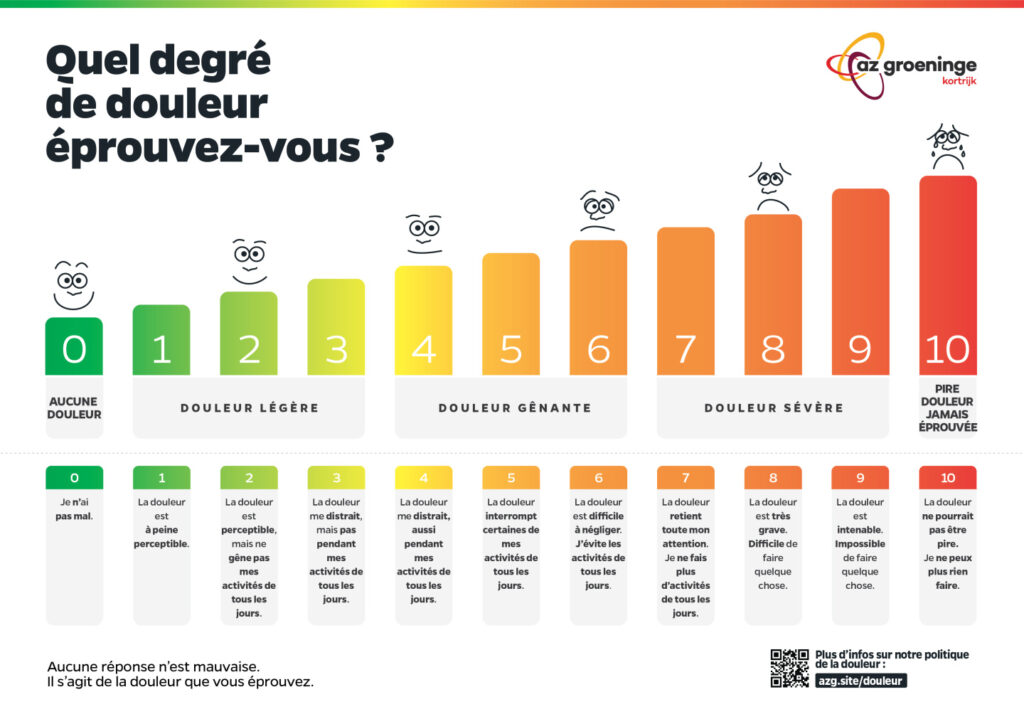
En médecine, on veut toujours mesurer les choses. Mais certaines restent insondables. Pour mesurer la douleur, il existe une échelle de la douleur.
Exemple d’échelle d’évaluation de la douleur.
« Mais deux personnes confrontés à la même blessure ne vont pas l’exprimer au même endroit sur l’échelle de la douleur. La douleur n’est pas objectivable. On ne peut connaître que les douleurs qu’on a vécu, à laquelle on les compare ». Mais chacun a une échelle de comparaison différente, car personnelle. « Et puis surtout, on est très doué pour ne pas croire et écouter les gens. C’est ainsi que l’endométriose a mis des années pour devenir un problème de santé publique. Une femme à 50% de chance d’être qualifiée en crise de panique quand elle fait un AVC qu’un homme »… Les exemples en ce sens sont innombrables. « Notre obsession à tout mesurer finit par nier l’existence de la subjectivité ». Rapportée à moi, ma douleur est réelle et handicapante. Rapportée aux autres, ma douleur n’est bien souvent perçue que comme une façon de se plaindre. « Les sciences cognitives ont pourtant besoin de meilleures approches pour prendre en compte cette phénoménologie. Nous avons besoin d’imaginer les moyens de mesurer la subjectivité et de la prendre plus au sérieux qu’elle n’est ».
La science de la subjectivité n’est pas dénuée de tentatives de mesure, mais elles sont souvent balayées de la main, alors qu’elles sont souvent plus fiables que les mesures dites objectives. « Demander à quelqu’un comment il va est souvent plus parlant que les mesures électrodermales qu’on peut réaliser ». Reste que les mesures physiologiques restent toujours très séduisantes que d’écouter un patient, un peu comme quand vous ajoutez une image d’une IRM à un article pour le rendre plus sérieux qu’il n’est.
*
Pour conclure la journée, Christian Fauré, directeur scientifique d’Octo Technology revenait sur son thème, l’incalculabilité. « Trop souvent, décider c’est calculer. Nos décisions ne dépendraient plus alors que d’une puissance de calcul, comme nous le racontent les chantres de l’IA qui s’empressent à nous vendre la plus puissante. Nos décisions sont-elles le fruit d’un calcul ? Nos modèles d’affaires dépendent-ils d’un calcul ? Au tout début d’OpenAI, Sam Altman promettait d’utiliser l’IA pour trouver un modèle économique à OpenAI. Pour lui, décider n’est rien d’autre que calculer. Et le calcul semble pouvoir s’appliquer à tout. Certains espaces échappent encore, comme vient de le dire Albert Moukheiber. Tout n’est pas calculable. Le calcul ne va pas tout résoudre. Cela semble difficile à croire quand tout est désormais analysé, soupesé, mesuré« . « Il faut qu’il y ait dans le poème un nombre tel qu’il empêche de compter », disait Paul Claudel. Le poème n’est pas que de la mesure et du calcul, voulait dire Claudel. Il faut qu’il reste de l’incalculable, même chez le comptable, sinon à quoi bon faire ces métiers. « L’incalculable, c’est ce qui donne du sens ».
« Nous vivons dans un monde où le calcul est partout… Mais il ne donne pas toutes les réponses. Et notamment, il ne donne pas de sens, comme disait Pascal Chabot. Claude Shannon, dit à ses collègues de ne pas donner de sens et de signification dans les données. Turing qui invente l’ordinateur, explique que c’est une procédure univoque, c’est-à-dire qu’elle est reliée à un langage qui n’a qu’un sens, comme le zéro et le un. Comme si finalement, dans cette abstraction pure, réduite à l’essentiel, il était impossible de percevoir le sens ».
« J’aimerais vous confronter à un problème de calcul difficile », attaque Albert Moukheiber sur la scène de la conférence USI 2025. « Dans les sciences cognitives, on est confronté à un problème qu’on n’arrive pas à résoudre : la subjectivité ! »
Le docteur en neuroscience et psychologue clinicien, auteur de Votre cerveau vous joue des tours (Allary éditions 2019) et de Neuromania (Allary éditions, 2024), commence par faire un rapide historique de ce qu’on sait sur le cerveau.
Où est le
« J’aimerais vous confronter à un problème de calcul difficile », attaque Albert Moukheiber sur la scène de la conférence USI 2025. « Dans les sciences cognitives, on est confronté à un problème qu’on n’arrive pas à résoudre : la subjectivité ! »
Le docteur en neuroscience et psychologue clinicien, auteur de Votre cerveau vous joue des tours (Allary éditions 2019) et de Neuromania (Allary éditions, 2024), commence par faire un rapide historique de ce qu’on sait sur le cerveau.
Où est le neurone ?
« Contrairement à d’autres organes, un cerveau mort n’a rien à dire sur son fonctionnement. Et pendant très longtemps, nous n’avons pas eu d’instruments pour comprendre un cerveau ». En fait, les technologies permettant d’ausculter le cerveau, de cartographier son activité, sont assez récentes et demeurent bien peu précises. Pour cela, il faut être capable de mesurer son activité, de voir où se font les afflux d’énergie et l’activité chimique. C’est seulement assez récemment, depuis les années 1990 surtout, qu’on a développé des technologies pour étudier cette activité, avec les électro-encéphalogrammes, puis avec l’imagerie par résonance magnétique (IRM) structurelle et surtout fonctionnelle. L’IRM fonctionnelle est celle que les médecins vous prescrivent. Elle mesure la matière cérébrale permettant de créer une image en noir et blanc pour identifier des maladies, des lésions, des tumeurs. Mais elle ne dit rien de l’activité neuronale. Seule l’IRM fonctionnelle observe l’activité, mais il faut comprendre que les images que nous en produisons sont peu précises et demeurent probabilistes. Les images de l’IRMf font apparaître des couleurs sur des zones en activité, mais ces couleurs ne désignent pas nécessairement une activité forte de ces zones, ni que le reste du cerveau est inactif. L’IRMf tente de montrer que certaines zones sont plus actives que d’autres parce qu’elles sont plus alimentées en oxygène et en sang. L’IRMf fonctionne par soustraction des images passées. Le patient dont on mesure l’activité cérébrale est invité à faire une tâche en limitant au maximum toute autre activité que celle demandée et les scientifiques comparent ces images à des précédentes pour déterminer quelles zones sont affectées quand vous fermez le poing par exemple. « On applique des calculs de probabilité aux soustractions pour tenter d’isoler un signal dans un océan de bruits », précise Moukheiber dans Neuromania. L’IRMf n’est donc pas un enregistrement direct de l’activation cérébrale pour une tâche donnée, mais « une reconstruction a posteriori de la probabilité qu’une aire soit impliquée dans cette tâche ». En fait, les couleurs indiquent des probabilités. « Ces couleurs n’indiquent donc pas une intensité d’activité, mais une probabilité d’implication ». Enfin, les mesures que nous réalisons n’ont rien de précis, rappelle le chercheur. La précision de l’IRMf est le voxel, qui contient environ 5,5 millions de neurones ! Ensuite, l’IRMf capture le taux d’oxygène, alors que la circulation sanguine est bien plus lente que les échanges chimiques de nos neurones. Enfin, le traitement de données est particulièrement complexe. Une étude a chargé plusieurs équipes d’analyser un même ensemble de données d’IRMf et n’a pas conduit aux mêmes résultats selon les équipes. Bref, pour le dire simplement, le neurone est l’unité de base de compréhension de notre cerveau, mais nos outils ne nous permettent pas de le mesurer. Il faut dire qu’il n’est pas non plus le bon niveau explicatif. Les explications établies à partir d’images issues de l’IRMf nous donnent donc plus une illusion de connaissance réelle qu’autre chose. D’où l’enjeu à prendre les résultats de nombre d’études qui s’appuient sur ces images avec beaucoup de recul. « On peut faire dire beaucoup de choses à l’imagerie cérébrale » et c’est assurément ce qui explique qu’elle soit si utilisée.
Les données ne suffisent pas
Dans les années 50-60, le courant de la cybernétique pensait le cerveau comme un organe de traitement de l’information, qu’on devrait étudier comme d’autres machines. C’est la naissance de la neuroscience computationnelle qui tente de modéliser le cerveau à l’image des machines. Outre les travaux de John von Neumann, Claude Shannon prolonge ces idées d’une théorie de l’information qui va permettre de créer des « neurones artificiels », qui ne portent ce nom que parce qu’ils ont été créés pour fonctionner sur le modèle d’un neurone. En 1957, le Perceptron de Frank Rosenblatt est considéré comme la première machine à utiliser un réseau neuronal artificiel. Mais on a bien plus appliqué le lexique du cerveau aux ordinateurs qu’autre chose, rappelle Albert Moukheiber.
Aujourd’hui, l’Intelligence artificielle et ses « réseaux de neurones » n’a plus rien à voir avec la façon dont fonctionne le cerveau, mais les neurosciences computationnelles, elles continuent, notamment pour aider à faire des prothèses adaptées comme les BCI, Brain Computer Interfaces.
Désormais, faire de la science consiste à essayer de comprendre comment fonctionne le monde naturel depuis un modèle. Jusqu’à récemment, on pensait qu’il fallait des théories pour savoir quoi faire des données, mais depuis l’avènement des traitements probabilistes et du Big Data, les modèles théoriques sont devenus inutiles, comme l’expliquait Chris Anderson dans The End of Theory en 2008. En 2017, des chercheurs se sont tout de même demandé si l’on pouvait renverser l’analogie cerveau-ordinateur en tentant de comprendre le fonctionnement d’un microprocesseur depuis les outils des neurosciences. Malgré l’arsenal d’outils à leur disposition, les chercheurs qui s’y sont essayé ont été incapables de produire un modèle de son fonctionnement. Cela nous montre que comprendre un fonctionnement ne nécessite pas seulement des informations techniques ou des données, mais avant tout des concepts pour les organiser. En fait, avoir accès à une quantité illimitée de données ne suffit pas à comprendre ni le processeur ni le cerveau. En 1974, le philosophe des sciences, Thomas Nagel, avait proposé une expérience de pensée avec son article « Quel effet ça fait d’être une chauve-souris ? ». Même si l’on connaissait tout d’une chauve-souris, on ne pourra jamais savoir ce que ça fait d’être une chauve-souris. Cela signifie qu’on ne peut jamais atteindre la vie intérieure d’autrui. Que la subjectivité des autres nous échappe toujours. C’est là le difficile problème de la conscience.
Albert Moukheiber sur la scène d’USI 2025.
La subjectivité nous échappe
Une émotion désigne trois choses distinctes, rappelle Albert Moukheiber. C’est un état biologique qu’on peut tenter d’objectiver en trouvant des modalités de mesure, comme le tonus musculaire. C’est un concept culturel qui a des ancrages et valeurs très différentes d’une culture l’autre. Mais c’est aussi et d’abord un ressenti subjectif. Ainsi, par exemple, le fait de se sentir triste n’est pas mesurable. « On peut parfaitement comprendre le cortex moteur et visuel, mais on ne comprend pas nécessairement ce qu’éprouve le narrateur de Proust quand il mange la fameuse madeleine. Dix personnes peuvent être émues par un même coucher de soleil, mais sont-elles émues de la même manière ? »
Notre réductionnisme objectivant est là confronté à des situations qu’il est difficile de mesurer. Ce qui n’est pas sans poser problèmes, notamment dans le monde de l’entreprise comme dans celui de la santé mentale.
Le monde de l’entreprise a créé d’innombrables indicateurs pour tenter de mesurer la performance des salariés et collaborateurs. Il n’est pas le seul, s’amuse le chercheur sur scène. Les notes des étudiants leurs rappellent que le but est de réussir les examens plus que d’apprendre. C’est la logique de la loi de Goodhart : quand la mesure devient la cible, elle n’est plus une bonne mesure. Pour obtenir des bonus financiers liés au nombre d’opérations réussies, les chirurgiens réalisent bien plus d’opérations faciles que de compliquées. Quand on mesure les humains, ils ont tendance à modifier leur comportement pour se conformer à la mesure, ce qui n’est pas sans effets rebond, à l’image du célèbre effet cobra, où le régime colonial britannique offrit une prime aux habitants de Delhi qui rapporteraient des cobras morts pour les éradiquer, mais qui a poussé à leur démultiplication pour toucher la prime. En entreprises, nombre de mesures réalisées perdent ainsi très vite de leur effectivité. Moukheiber rappelle que les innombrables tests de personnalité ne valent pas mieux qu’un horoscope. L’un des tests le plus utilisé reste le MBTI qui a été développé dans les années 30 par des personnes sans aucune formation en psychologie. Non seulement ces tests n’ont aucun cadre théorique (voir ce que nous en disait le psychologue Alexandre Saint-Jevin, il y a quelques années), mais surtout, « ce sont nos croyances qui sont déphasées. Beaucoup de personnes pensent que la personnalité des individus serait centrale dans le cadre professionnel. C’est oublier que Steve Jobs était surtout un bel enfoiré ! », comme nombre de ces « grands » entrepreneurs que trop de gens portent aux nues. Comme nous le rappelions nous-mêmes, la recherche montre en effet que les tests de personnalités peinent à mesurer la performance au travail et que celle-ci a d’ailleurs peu à voir avec la personnalité. « Ces tests nous demandent d’y répondre personnellement, quand ce devrait être d’abord à nos collègues de les passer pour nous », ironiseMoukheiber. Ils supposent surtout que la personnalité serait « stable », ce qui n’est certainement pas si vrai. Enfin, ces tests oublient que bien d’autres facteurs ont peut-être bien plus d’importance que la personnalité : les compétences, le fait de bien s’entendre avec les autres, le niveau de rémunération, le cadre de travail… Mais surtout, ils ont tous un effet « barnum » : n’importe qui est capable de se reconnaître dedans. Dans ces tests, les résultats sont toujours positifs, même les gens les plus sadiques seront flattés des résultats. Bref, vous pouvez les passer à la broyeuse.
Dans le domaine de la santé mentale, la mesure de la subjectivité est très difficile et son absence très handicapante. La santé mentale est souvent vue comme une discipline objectivable, comme le reste de la santé. Le modèle biomédical repose sur l’idée qu’il suffit d’ôter le pathogène pour aller mieux. Il suffirait alors d’enlever les troubles mentaux pour enlever le pathogène. Bien sûr, ce n’est pas le cas. « Imaginez un moment, vous êtes une femme brillante de 45 ans, star montante de son domaine, travaillant dans une entreprise où vous êtes très valorisée. Vous êtes débauché par la concurrence, une entreprise encore plus brillante où vous allez pouvoir briller encore plus. Mais voilà, vous y subissez des remarques sexistes permanentes, tant et si bien que vous vous sentez moins bien, que vous perdez confiance, que vous développez un trouble anxieux. On va alors pousser la personne à se soigner… Mais le pathogène n’est ici pas en elle, il est dans son environnement. N’est-ce pas ici ses collègues qu’il faudrait pousser à se faire soigner ? »
En médecine, on veut toujours mesurer les choses. Mais certaines restent insondables. Pour mesurer la douleur, il existe une échelle de la douleur.
Exemple d’échelle d’évaluation de la douleur.
« Mais deux personnes confrontés à la même blessure ne vont pas l’exprimer au même endroit sur l’échelle de la douleur. La douleur n’est pas objectivable. On ne peut connaître que les douleurs qu’on a vécu, à laquelle on les compare ». Mais chacun a une échelle de comparaison différente, car personnelle. « Et puis surtout, on est très doué pour ne pas croire et écouter les gens. C’est ainsi que l’endométriose a mis des années pour devenir un problème de santé publique. Une femme à 50% de chance d’être qualifiée en crise de panique quand elle fait un AVC qu’un homme »… Les exemples en ce sens sont innombrables. « Notre obsession à tout mesurer finit par nier l’existence de la subjectivité ». Rapportée à moi, ma douleur est réelle et handicapante. Rapportée aux autres, ma douleur n’est bien souvent perçue que comme une façon de se plaindre. « Les sciences cognitives ont pourtant besoin de meilleures approches pour prendre en compte cette phénoménologie. Nous avons besoin d’imaginer les moyens de mesurer la subjectivité et de la prendre plus au sérieux qu’elle n’est ».
La science de la subjectivité n’est pas dénuée de tentatives de mesure, mais elles sont souvent balayées de la main, alors qu’elles sont souvent plus fiables que les mesures dites objectives. « Demander à quelqu’un comment il va est souvent plus parlant que les mesures électrodermales qu’on peut réaliser ». Reste que les mesures physiologiques restent toujours très séduisantes que d’écouter un patient, un peu comme quand vous ajoutez une image d’une IRM à un article pour le rendre plus sérieux qu’il n’est.
*
Pour conclure la journée, Christian Fauré, directeur scientifique d’Octo Technology revenait sur son thème, l’incalculabilité. « Trop souvent, décider c’est calculer. Nos décisions ne dépendraient plus alors que d’une puissance de calcul, comme nous le racontent les chantres de l’IA qui s’empressent à nous vendre la plus puissante. Nos décisions sont-elles le fruit d’un calcul ? Nos modèles d’affaires dépendent-ils d’un calcul ? Au tout début d’OpenAI, Sam Altman promettait d’utiliser l’IA pour trouver un modèle économique à OpenAI. Pour lui, décider n’est rien d’autre que calculer. Et le calcul semble pouvoir s’appliquer à tout. Certains espaces échappent encore, comme vient de le dire Albert Moukheiber. Tout n’est pas calculable. Le calcul ne va pas tout résoudre. Cela semble difficile à croire quand tout est désormais analysé, soupesé, mesuré« . « Il faut qu’il y ait dans le poème un nombre tel qu’il empêche de compter », disait Paul Claudel. Le poème n’est pas que de la mesure et du calcul, voulait dire Claudel. Il faut qu’il reste de l’incalculable, même chez le comptable, sinon à quoi bon faire ces métiers. « L’incalculable, c’est ce qui donne du sens ».
« Nous vivons dans un monde où le calcul est partout… Mais il ne donne pas toutes les réponses. Et notamment, il ne donne pas de sens, comme disait Pascal Chabot. Claude Shannon, dit à ses collègues de ne pas donner de sens et de signification dans les données. Turing qui invente l’ordinateur, explique que c’est une procédure univoque, c’est-à-dire qu’elle est reliée à un langage qui n’a qu’un sens, comme le zéro et le un. Comme si finalement, dans cette abstraction pure, réduite à l’essentiel, il était impossible de percevoir le sens ».
Alors que l’IA s’intègre peu à peu partout dans nos vies, les ressources énergétiques nécessaires à cette révolution sont colossales. Les plus grandes entreprises technologiques mondiales l’ont bien compris et ont fait de l’exploitation de l’énergie leur nouvelle priorité, à l’image de Meta et Microsoft qui travaillent à la mise en service de centrales nucléaires pour assouvir leurs besoins. Tous les Gafams ont des programmes de construction de data centers démesurés avec des centaines de millia
Alors que l’IA s’intègre peu à peu partout dans nos vies, les ressources énergétiques nécessaires à cette révolution sont colossales. Les plus grandes entreprises technologiques mondiales l’ont bien compris et ont fait de l’exploitation de l’énergie leur nouvelle priorité, à l’image de Meta et Microsoft qui travaillent à la mise en service de centrales nucléaires pour assouvir leurs besoins. Tous les Gafams ont des programmes de construction de data centers démesurés avec des centaines de milliards d’investissements, explique la Technology Review. C’est le cas par exemple à Abilene au Texas, où OpenAI (associé à Oracle et SoftBank) construit un data center géant, premier des 10 mégasites du projet Stargate, explique un copieux reportage de Bloomberg, qui devrait coûter quelque 12 milliards de dollars (voir également le reportage de 40 minutes en vidéo qui revient notamment sur les tensions liées à ces constructions). Mais plus que de centres de données, il faut désormais parler « d’usine à IA », comme le propose le patron de Nvidia, Jensen Huang.
“De 2005 à 2017, la quantité d’électricité destinée aux centres de données est restée relativement stable grâce à des gains d’efficacité, malgré la construction d’une multitude de nouveaux centres de données pour répondre à l’essor des services en ligne basés sur le cloud, de Facebook à Netflix”, explique la TechReview. Mais depuis 2017 et l’arrivée de l’IA, cette consommation s’est envolée. Les derniers rapports montrent que 4,4 % de l’énergie totale aux États-Unis est désormais destinée aux centres de données. “Compte tenu de l’orientation de l’IA – plus personnalisée, capable de raisonner et de résoudre des problèmes complexes à notre place, partout où nous regardons –, il est probable que notre empreinte IA soit aujourd’hui la plus faible jamais atteinte”. D’ici 2028, l’IA à elle seule pourrait consommer chaque année autant d’électricité que 22 % des foyers américains.
“Les chiffres sur la consommation énergétique de l’IA court-circuitent souvent le débat, soit en réprimandant les comportements individuels, soit en suscitant des comparaisons avec des acteurs plus importants du changement climatique. Ces deux réactions esquivent l’essentiel : l’IA est incontournable, et même si une seule requête est à faible impact, les gouvernements et les entreprises façonnent désormais un avenir énergétique bien plus vaste autour des besoins de l’IA”. ChatGPT est désormais considéré comme le cinquième site web le plus visité au monde, juste après Instagram et devant X. Et ChatGPT n’est que l’arbre de la forêt des applications de l’IA qui s’intègrent partout autour de nous. Or, rappelle la Technology Review, l’information et les données sur la consommation énergétique du secteur restent très parcellaires et lacunaires. Le long dossier de la Technology Review rappelle que si l’entraînement des modèles est énergétiquement coûteux, c’est désormais son utilisation qui devient problématique, notamment, comme l’explique très pédagogiquement Le Monde, parce que les requêtes dans un LLM, recalculent en permanence ce qu’on leur demande (et les calculateurs qui évaluent la consommation énergétique de requêtes selon les moteurs d’IA utilisés, comme Ecologits ou ComparIA s’appuient sur des estimations). Dans les 3000 centres de données qu’on estime en activité aux Etats-Unis, de plus en plus d’espaces sont consacrés à des infrastructures dédiées à l’IA, notamment avec des serveurs dotés de puces spécifiques qui ont une consommation énergétique importante pour exécuter leurs opérations avancées sans surchauffe.
Calculer l’impact énergétique d’une requête n’est pas aussi simple que de mesurer la consommation de carburant d’une voiture, rappelle le magazine. “Le type et la taille du modèle, le type de résultat généré et d’innombrables variables indépendantes de votre volonté, comme le réseau électrique connecté au centre de données auquel votre requête est envoyée et l’heure de son traitement, peuvent rendre une requête mille fois plus énergivore et émettrice d’émissions qu’une autre”. Outre cette grande variabilité de l’impact, il faut ajouter l’opacité des géants de l’IA à communiquer des informations et des données fiables et prendre en compte le fait que nos utilisations actuelles de l’IA sont bien plus frustres que les utilisations que nous aurons demain, dans un monde toujours plus agentif et autonome. La taille des modèles, la complexité des questions sont autant d’éléments qui influent sur la consommation énergétique. Bien évidemment, la production de vidéo consomme plus d’énergie qu’une production textuelle. Les entreprises d’IA estiment cependant que la vidéo générative a une empreinte plus faible que les tournages et la production classique, mais cette affirmation n’est pas démontrée et ne prend pas en compte l’effet rebond que génèrerait les vidéos génératives si elles devenaient peu coûteuses à produire.
La Techno Review propose donc une estimation d’usage quotidien, à savoir en prenant comme moyenne le fait de poser 15 questions à un modèle d’IA génératives, faire 10 essais d’image et produire 5 secondes de vidéo. Ce qui équivaudrait (très grossièrement) à consommer 2,9 kilowattheures d’électricité, l’équivalent d’un micro-onde allumé pendant 3h30. Ensuite, les journalistes tentent d’évaluer l’impact carbone de cette consommation qui dépend beaucoup de sa localisation, selon que les réseaux sont plus ou moins décarbonés, ce qui est encore bien peu le cas aux Etats-Unis (voir notamment l’explication sur les modalités de calcul mobilisées par la Tech Review). “En Californie, produire ces 2,9 kilowattheures d’électricité produirait en moyenne environ 650 grammes de dioxyde de carbone. Mais produire cette même électricité en Virginie-Occidentale pourrait faire grimper le total à plus de 1 150 grammes”. On peut généraliser ces estimations pour tenter de calculer l’impact global de l’IA… et faire des calculs compliqués pour tenter d’approcher la réalité… “Mais toutes ces estimations ne reflètent pas l’avenir proche de l’utilisation de l’IA”. Par exemple, ces estimations reposent sur l’utilisation de puces qui ne sont pas celles qui seront utilisées l’année prochaine ou la suivante dans les “usines à IA” que déploie Nvidia, comme l’expliquait son patron, Jensen Huang, dans une des spectaculaires messes qu’il dissémine autour du monde. Dans cette course au nombre de token générés par seconde, qui devient l’indicateur clé de l’industrie, c’est l’architecture de l’informatique elle-même qui est modifiée. Huang parle de passage à l’échelle qui nécessite de générer le plus grand nombre de token possible et le plus rapidement possible pour favoriser le déploiement d’une IA toujours plus puissante. Cela passe bien évidemment par la production de puces et de serveurs toujours plus puissants et toujours plus efficaces.
« Dans ce futur, nous ne nous contenterons pas de poser une ou deux questions aux modèles d’IA au cours de la journée, ni de leur demander de générer une photo”. L’avenir, rappelle la Technology Review, est celui des agents IA effectuent des tâches pour nous, où nous discutons en continue avec des agents, où nous “confierons des tâches complexes à des modèles de raisonnement dont on a constaté qu’ils consomment 43 fois plus d’énergie pour les problèmes simples, ou à des modèles de « recherche approfondie”, qui passeront des heures à créer des rapports pour nous ». Nous disposerons de modèles d’IA “personnalisés” par l’apprentissage de nos données et de nos préférences. Et ces modèles sont appelés à s’intégrer partout, des lignes téléphoniques des services clients aux cabinets médicaux… Comme le montrait les dernières démonstrations de Google en la matière : “En mettant l’IA partout, Google souhaite nous la rendre invisible”. “Il ne s’agit plus de savoir qui possède les modèles les plus puissants, mais de savoir qui les transforme en produits performants”. Et de ce côté, là course démarre à peine. Google prévoit par exemple d’intégrer l’IA partout, pour créer des résumés d’email comme des mailings automatisés adaptés à votre style qui répondront pour vous. Meta imagine intégrer l’IA dans toute sa chaîne publicitaire pour permettre à quiconque de générer des publicités et demain, les générer selon les profils : plus personne ne verra la même ! Les usages actuels de l’IA n’ont rien à voir avec les usages que nous aurons demain. Les 15 questions, les 10 images et les 5 secondes de vidéo que la Technology Review prend comme exemple d’utilisation quotidienne appartiennent déjà au passé. Le succès et l’intégration des outils d’IA des plus grands acteurs que sont OpenAI, Google et Meta vient de faire passer le nombre estimé des utilisateurs de l’IA de 700 millions en mars à 3,5 milliards en mai 2025.
”Tous les chercheurs interrogés ont affirmé qu’il était impossible d’appréhender les besoins énergétiques futurs en extrapolant simplement l’énergie utilisée par les requêtes d’IA actuelles.” Le fait que les grandes entreprises de l’IA se mettent à construire des centrales nucléaires est d’ailleurs le révélateur qu’elles prévoient, elles, une explosion de leurs besoins énergétiques. « Les quelques chiffres dont nous disposons peuvent apporter un éclairage infime sur notre situation actuelle, mais les années à venir sont incertaines », déclare Sasha Luccioni de Hugging Face. « Les outils d’IA générative nous sont imposés de force, et il devient de plus en plus difficile de s’en désengager ou de faire des choix éclairés en matière d’énergie et de climat. »
La prolifération de l’IA fait peser des perspectives très lourdes sur l’avenir de notre consommation énergétique. “Entre 2024 et 2028, la part de l’électricité américaine destinée aux centres de données pourrait tripler, passant de 4,4 % actuellement à 12 %” Toutes les entreprises estiment que l’IA va nous aider à découvrir des solutions, que son efficacité énergétique va s’améliorer… Et c’est effectivement le cas. A entendre Jensen Huang de Nvidia, c’est déjà le cas, assure-t-il en vantant les mérites des prochaines génération de puces à venir. Mais sans données, aucune “projection raisonnable” n’est possible, estime les contributeurs du rapport du département de l’énergie américain. Surtout, il est probable que ce soient les usagers qui finissent par en payer le prix. Selon une nouvelle étude, les particuliers pourraient finir par payer une partie de la facture de cette révolution de l’IA. Les chercheurs de l’Electricity Law Initiative de Harvard ont analysé les accords entre les entreprises de services publics et les géants de la technologie comme Meta, qui régissent le prix de l’électricité dans les nouveaux centres de données gigantesques. Ils ont constaté que les remises accordées par les entreprises de services publics aux géants de la technologie peuvent augmenter les tarifs d’électricité payés par les consommateurs. Les impacts écologiques de l’IA s’apprêtent donc à être maximums, à mesure que ses déploiements s’intègrent partout. “Il est clair que l’IA est une force qui transforme non seulement la technologie, mais aussi le réseau électrique et le monde qui nous entoure”.
L’article phare de la TechReview, se prolonge d’un riche dossier. Dans un article, qui tente de contrebalancer les constats mortifères que le magazine dresse, la TechReview rappelle bien sûr que les modèles d’IA vont devenir plus efficaces, moins chers et moins gourmands énergétiquement, par exemple en entraînant des modèles avec des données plus organisées et adaptées à des tâches spécifiques. Des perspectives s’échaffaudent aussi du côté des puces et des capacités de calculs, ou encore par l’amélioration du refroidissement des centres de calculs. Beaucoup d’ingénieurs restent confiants. “Depuis, l’essor d’internet et des ordinateurs personnels il y a 25 ans, à mesure que la technologie à l’origine de ces révolutions s’est améliorée, les coûts de l’énergie sont restés plus ou moins stables, malgré l’explosion du nombre d’utilisateurs”. Pas sûr que réitérer ces vieilles promesses suffise.
Comme le disait Gauthier Roussilhe, nos projections sur les impacts environnementaux à venir sont avant toutes coincées dans le présent. Et elles le sont d’autant plus que les mesures de la consommation énergétique de l’IA sont coincées dans les mesures d’hier, sans être capables de prendre en compte l’efficience à venir et que les effets rebonds de la consommation, dans la perspective de systèmes d’IA distribués partout, accessibles partout, voire pire d’une IA qui se substitue à tous les usages numériques actuels, ne permettent pas d’imaginer ce que notre consommation d’énergie va devenir. Si l’efficience énergétique va s’améliorer, le rebond des usages par l’intégration de l’IA partout, lui, nous montre que les gains obtenus sont toujours totalement absorbés voir totalement dépassés avec l’extension et l’accroissement des usages.
Alors que l’IA s’intègre peu à peu partout dans nos vies, les ressources énergétiques nécessaires à cette révolution sont colossales. Les plus grandes entreprises technologiques mondiales l’ont bien compris et ont fait de l’exploitation de l’énergie leur nouvelle priorité, à l’image de Meta et Microsoft qui travaillent à la mise en service de centrales nucléaires pour assouvir leurs besoins. Tous les Gafams ont des programmes de construction de data centers démesurés avec des centaines de millia
Alors que l’IA s’intègre peu à peu partout dans nos vies, les ressources énergétiques nécessaires à cette révolution sont colossales. Les plus grandes entreprises technologiques mondiales l’ont bien compris et ont fait de l’exploitation de l’énergie leur nouvelle priorité, à l’image de Meta et Microsoft qui travaillent à la mise en service de centrales nucléaires pour assouvir leurs besoins. Tous les Gafams ont des programmes de construction de data centers démesurés avec des centaines de milliards d’investissements, explique la Technology Review. C’est le cas par exemple à Abilene au Texas, où OpenAI (associé à Oracle et SoftBank) construit un data center géant, premier des 10 mégasites du projet Stargate, explique un copieux reportage de Bloomberg, qui devrait coûter quelque 12 milliards de dollars (voir également le reportage de 40 minutes en vidéo qui revient notamment sur les tensions liées à ces constructions). Mais plus que de centres de données, il faut désormais parler « d’usine à IA », comme le propose le patron de Nvidia, Jensen Huang.
“De 2005 à 2017, la quantité d’électricité destinée aux centres de données est restée relativement stable grâce à des gains d’efficacité, malgré la construction d’une multitude de nouveaux centres de données pour répondre à l’essor des services en ligne basés sur le cloud, de Facebook à Netflix”, explique la TechReview. Mais depuis 2017 et l’arrivée de l’IA, cette consommation s’est envolée. Les derniers rapports montrent que 4,4 % de l’énergie totale aux États-Unis est désormais destinée aux centres de données. “Compte tenu de l’orientation de l’IA – plus personnalisée, capable de raisonner et de résoudre des problèmes complexes à notre place, partout où nous regardons –, il est probable que notre empreinte IA soit aujourd’hui la plus faible jamais atteinte”. D’ici 2028, l’IA à elle seule pourrait consommer chaque année autant d’électricité que 22 % des foyers américains.
“Les chiffres sur la consommation énergétique de l’IA court-circuitent souvent le débat, soit en réprimandant les comportements individuels, soit en suscitant des comparaisons avec des acteurs plus importants du changement climatique. Ces deux réactions esquivent l’essentiel : l’IA est incontournable, et même si une seule requête est à faible impact, les gouvernements et les entreprises façonnent désormais un avenir énergétique bien plus vaste autour des besoins de l’IA”. ChatGPT est désormais considéré comme le cinquième site web le plus visité au monde, juste après Instagram et devant X. Et ChatGPT n’est que l’arbre de la forêt des applications de l’IA qui s’intègrent partout autour de nous. Or, rappelle la Technology Review, l’information et les données sur la consommation énergétique du secteur restent très parcellaires et lacunaires. Le long dossier de la Technology Review rappelle que si l’entraînement des modèles est énergétiquement coûteux, c’est désormais son utilisation qui devient problématique, notamment, comme l’explique très pédagogiquement Le Monde, parce que les requêtes dans un LLM, recalculent en permanence ce qu’on leur demande (et les calculateurs qui évaluent la consommation énergétique de requêtes selon les moteurs d’IA utilisés, comme Ecologits ou ComparIA s’appuient sur des estimations). Dans les 3000 centres de données qu’on estime en activité aux Etats-Unis, de plus en plus d’espaces sont consacrés à des infrastructures dédiées à l’IA, notamment avec des serveurs dotés de puces spécifiques qui ont une consommation énergétique importante pour exécuter leurs opérations avancées sans surchauffe.
Calculer l’impact énergétique d’une requête n’est pas aussi simple que de mesurer la consommation de carburant d’une voiture, rappelle le magazine. “Le type et la taille du modèle, le type de résultat généré et d’innombrables variables indépendantes de votre volonté, comme le réseau électrique connecté au centre de données auquel votre requête est envoyée et l’heure de son traitement, peuvent rendre une requête mille fois plus énergivore et émettrice d’émissions qu’une autre”. Outre cette grande variabilité de l’impact, il faut ajouter l’opacité des géants de l’IA à communiquer des informations et des données fiables et prendre en compte le fait que nos utilisations actuelles de l’IA sont bien plus frustres que les utilisations que nous aurons demain, dans un monde toujours plus agentif et autonome. La taille des modèles, la complexité des questions sont autant d’éléments qui influent sur la consommation énergétique. Bien évidemment, la production de vidéo consomme plus d’énergie qu’une production textuelle. Les entreprises d’IA estiment cependant que la vidéo générative a une empreinte plus faible que les tournages et la production classique, mais cette affirmation n’est pas démontrée et ne prend pas en compte l’effet rebond que génèrerait les vidéos génératives si elles devenaient peu coûteuses à produire.
La Techno Review propose donc une estimation d’usage quotidien, à savoir en prenant comme moyenne le fait de poser 15 questions à un modèle d’IA génératives, faire 10 essais d’image et produire 5 secondes de vidéo. Ce qui équivaudrait (très grossièrement) à consommer 2,9 kilowattheures d’électricité, l’équivalent d’un micro-onde allumé pendant 3h30. Ensuite, les journalistes tentent d’évaluer l’impact carbone de cette consommation qui dépend beaucoup de sa localisation, selon que les réseaux sont plus ou moins décarbonés, ce qui est encore bien peu le cas aux Etats-Unis (voir notamment l’explication sur les modalités de calcul mobilisées par la Tech Review). “En Californie, produire ces 2,9 kilowattheures d’électricité produirait en moyenne environ 650 grammes de dioxyde de carbone. Mais produire cette même électricité en Virginie-Occidentale pourrait faire grimper le total à plus de 1 150 grammes”. On peut généraliser ces estimations pour tenter de calculer l’impact global de l’IA… et faire des calculs compliqués pour tenter d’approcher la réalité… “Mais toutes ces estimations ne reflètent pas l’avenir proche de l’utilisation de l’IA”. Par exemple, ces estimations reposent sur l’utilisation de puces qui ne sont pas celles qui seront utilisées l’année prochaine ou la suivante dans les “usines à IA” que déploie Nvidia, comme l’expliquait son patron, Jensen Huang, dans une des spectaculaires messes qu’il dissémine autour du monde. Dans cette course au nombre de token générés par seconde, qui devient l’indicateur clé de l’industrie, c’est l’architecture de l’informatique elle-même qui est modifiée. Huang parle de passage à l’échelle qui nécessite de générer le plus grand nombre de token possible et le plus rapidement possible pour favoriser le déploiement d’une IA toujours plus puissante. Cela passe bien évidemment par la production de puces et de serveurs toujours plus puissants et toujours plus efficaces.
« Dans ce futur, nous ne nous contenterons pas de poser une ou deux questions aux modèles d’IA au cours de la journée, ni de leur demander de générer une photo”. L’avenir, rappelle la Technology Review, est celui des agents IA effectuent des tâches pour nous, où nous discutons en continue avec des agents, où nous “confierons des tâches complexes à des modèles de raisonnement dont on a constaté qu’ils consomment 43 fois plus d’énergie pour les problèmes simples, ou à des modèles de « recherche approfondie”, qui passeront des heures à créer des rapports pour nous ». Nous disposerons de modèles d’IA “personnalisés” par l’apprentissage de nos données et de nos préférences. Et ces modèles sont appelés à s’intégrer partout, des lignes téléphoniques des services clients aux cabinets médicaux… Comme le montrait les dernières démonstrations de Google en la matière : “En mettant l’IA partout, Google souhaite nous la rendre invisible”. “Il ne s’agit plus de savoir qui possède les modèles les plus puissants, mais de savoir qui les transforme en produits performants”. Et de ce côté, là course démarre à peine. Google prévoit par exemple d’intégrer l’IA partout, pour créer des résumés d’email comme des mailings automatisés adaptés à votre style qui répondront pour vous. Meta imagine intégrer l’IA dans toute sa chaîne publicitaire pour permettre à quiconque de générer des publicités et demain, les générer selon les profils : plus personne ne verra la même ! Les usages actuels de l’IA n’ont rien à voir avec les usages que nous aurons demain. Les 15 questions, les 10 images et les 5 secondes de vidéo que la Technology Review prend comme exemple d’utilisation quotidienne appartiennent déjà au passé. Le succès et l’intégration des outils d’IA des plus grands acteurs que sont OpenAI, Google et Meta vient de faire passer le nombre estimé des utilisateurs de l’IA de 700 millions en mars à 3,5 milliards en mai 2025.
”Tous les chercheurs interrogés ont affirmé qu’il était impossible d’appréhender les besoins énergétiques futurs en extrapolant simplement l’énergie utilisée par les requêtes d’IA actuelles.” Le fait que les grandes entreprises de l’IA se mettent à construire des centrales nucléaires est d’ailleurs le révélateur qu’elles prévoient, elles, une explosion de leurs besoins énergétiques. « Les quelques chiffres dont nous disposons peuvent apporter un éclairage infime sur notre situation actuelle, mais les années à venir sont incertaines », déclare Sasha Luccioni de Hugging Face. « Les outils d’IA générative nous sont imposés de force, et il devient de plus en plus difficile de s’en désengager ou de faire des choix éclairés en matière d’énergie et de climat. »
La prolifération de l’IA fait peser des perspectives très lourdes sur l’avenir de notre consommation énergétique. “Entre 2024 et 2028, la part de l’électricité américaine destinée aux centres de données pourrait tripler, passant de 4,4 % actuellement à 12 %” Toutes les entreprises estiment que l’IA va nous aider à découvrir des solutions, que son efficacité énergétique va s’améliorer… Et c’est effectivement le cas. A entendre Jensen Huang de Nvidia, c’est déjà le cas, assure-t-il en vantant les mérites des prochaines génération de puces à venir. Mais sans données, aucune “projection raisonnable” n’est possible, estime les contributeurs du rapport du département de l’énergie américain. Surtout, il est probable que ce soient les usagers qui finissent par en payer le prix. Selon une nouvelle étude, les particuliers pourraient finir par payer une partie de la facture de cette révolution de l’IA. Les chercheurs de l’Electricity Law Initiative de Harvard ont analysé les accords entre les entreprises de services publics et les géants de la technologie comme Meta, qui régissent le prix de l’électricité dans les nouveaux centres de données gigantesques. Ils ont constaté que les remises accordées par les entreprises de services publics aux géants de la technologie peuvent augmenter les tarifs d’électricité payés par les consommateurs. Les impacts écologiques de l’IA s’apprêtent donc à être maximums, à mesure que ses déploiements s’intègrent partout. “Il est clair que l’IA est une force qui transforme non seulement la technologie, mais aussi le réseau électrique et le monde qui nous entoure”.
L’article phare de la TechReview, se prolonge d’un riche dossier. Dans un article, qui tente de contrebalancer les constats mortifères que le magazine dresse, la TechReview rappelle bien sûr que les modèles d’IA vont devenir plus efficaces, moins chers et moins gourmands énergétiquement, par exemple en entraînant des modèles avec des données plus organisées et adaptées à des tâches spécifiques. Des perspectives s’échaffaudent aussi du côté des puces et des capacités de calculs, ou encore par l’amélioration du refroidissement des centres de calculs. Beaucoup d’ingénieurs restent confiants. “Depuis, l’essor d’internet et des ordinateurs personnels il y a 25 ans, à mesure que la technologie à l’origine de ces révolutions s’est améliorée, les coûts de l’énergie sont restés plus ou moins stables, malgré l’explosion du nombre d’utilisateurs”. Pas sûr que réitérer ces vieilles promesses suffise.
Comme le disait Gauthier Roussilhe, nos projections sur les impacts environnementaux à venir sont avant toutes coincées dans le présent. Et elles le sont d’autant plus que les mesures de la consommation énergétique de l’IA sont coincées dans les mesures d’hier, sans être capables de prendre en compte l’efficience à venir et que les effets rebonds de la consommation, dans la perspective de systèmes d’IA distribués partout, accessibles partout, voire pire d’une IA qui se substitue à tous les usages numériques actuels, ne permettent pas d’imaginer ce que notre consommation d’énergie va devenir. Si l’efficience énergétique va s’améliorer, le rebond des usages par l’intégration de l’IA partout, lui, nous montre que les gains obtenus sont toujours totalement absorbés voir totalement dépassés avec l’extension et l’accroissement des usages.
Le rapport de Coworker sur le déploiement des « petites technologies de surveillance » – petites, mais omniprésentes (qu’on évoquait dans cet article) – rappelait déjà que c’est un essaim de solutions de surveillance qui se déversent désormais sur les employés (voir également notre article “Réguler la surveillance au travail”). Dans un nouveau rapport, Coworker explique que les formes de surveillance au travail s’étendent et s’internationalisent. “L’écosystème des petites technologies intègre la
Le rapport de Coworker sur le déploiement des « petites technologies de surveillance » – petites, mais omniprésentes (qu’on évoquait dans cet article) – rappelait déjà que c’est un essaim de solutions de surveillance qui se déversent désormais sur les employés (voir également notre article “Réguler la surveillance au travail”). Dans un nouveau rapport, Coworker explique que les formes de surveillance au travail s’étendent et s’internationalisent. “L’écosystème des petites technologies intègre la surveillance et le contrôle algorithmique dans le quotidien des travailleurs, souvent à leur insu, sans leur consentement ni leur protection”. L’enquête observe cette extension dans six pays – le Mexique, la Colombie, le Brésil, le Nigéria, le Kenya et l’Inde – “où les cadres juridiques sont obsolètes, mal appliqués, voire inexistants”. Le rapport révèle comment les startups financées par du capital-risque américain exportent des technologies de surveillance vers les pays du Sud, ciblant des régions où la protection de la vie privée et la surveillance réglementaire sont plus faibles. Les premiers à en faire les frais sont les travailleurs de l’économie à la demande de la livraison et du covoiturage, mais pas seulement. Mais surtout, cette surveillance est de plus en plus déguisée en moyen pour prendre soin des travailleurs : “la surveillance par l’IA est de plus en plus présentée comme un outil de sécurité, de bien-être et de productivité, masquant une surveillance coercitive sous couvert de santé et d’efficacité”.
Pourtant, “des éboueurs en Inde aux chauffeurs de VTC au Nigéria, les travailleurs résistent au contrôle algorithmique en organisant des manifestations, en créant des syndicats et en exigeant la transparence de l’IA”. Le risque est que les pays du Sud deviennent le terrain d’essai de ces technologies de surveillance pour le reste du monde, rappelle Rest of the World.
Le rapport de Coworker sur le déploiement des « petites technologies de surveillance » – petites, mais omniprésentes (qu’on évoquait dans cet article) – rappelait déjà que c’est un essaim de solutions de surveillance qui se déversent désormais sur les employés (voir également notre article “Réguler la surveillance au travail”). Dans un nouveau rapport, Coworker explique que les formes de surveillance au travail s’étendent et s’internationalisent. “L’écosystème des petites technologies intègre la
Le rapport de Coworker sur le déploiement des « petites technologies de surveillance » – petites, mais omniprésentes (qu’on évoquait dans cet article) – rappelait déjà que c’est un essaim de solutions de surveillance qui se déversent désormais sur les employés (voir également notre article “Réguler la surveillance au travail”). Dans un nouveau rapport, Coworker explique que les formes de surveillance au travail s’étendent et s’internationalisent. “L’écosystème des petites technologies intègre la surveillance et le contrôle algorithmique dans le quotidien des travailleurs, souvent à leur insu, sans leur consentement ni leur protection”. L’enquête observe cette extension dans six pays – le Mexique, la Colombie, le Brésil, le Nigéria, le Kenya et l’Inde – “où les cadres juridiques sont obsolètes, mal appliqués, voire inexistants”. Le rapport révèle comment les startups financées par du capital-risque américain exportent des technologies de surveillance vers les pays du Sud, ciblant des régions où la protection de la vie privée et la surveillance réglementaire sont plus faibles. Les premiers à en faire les frais sont les travailleurs de l’économie à la demande de la livraison et du covoiturage, mais pas seulement. Mais surtout, cette surveillance est de plus en plus déguisée en moyen pour prendre soin des travailleurs : “la surveillance par l’IA est de plus en plus présentée comme un outil de sécurité, de bien-être et de productivité, masquant une surveillance coercitive sous couvert de santé et d’efficacité”.
Pourtant, “des éboueurs en Inde aux chauffeurs de VTC au Nigéria, les travailleurs résistent au contrôle algorithmique en organisant des manifestations, en créant des syndicats et en exigeant la transparence de l’IA”. Le risque est que les pays du Sud deviennent le terrain d’essai de ces technologies de surveillance pour le reste du monde, rappelle Rest of the World.
Les grands modèles de langage ne sont pas interprétables, rappelle le professeur de droit Jonathan Zittrain dans une tribune pour le New York Times, en préfiguration d’un nouveau livre à paraître. Ils demeurent des boîtes noires, dont on ne parvient pas à comprendre pourquoi ces modèles peuvent parfois dialoguer si intelligemment et pourquoi ils commettent à d’autres moments des erreurs si étranges. Mieux comprendre certains des mécanismes de fonctionnement de ces modèles et utiliser cette comp
Les grands modèles de langage ne sont pas interprétables, rappelle le professeur de droit Jonathan Zittrain dans une tribune pour le New York Times, en préfiguration d’un nouveau livre à paraître. Ils demeurent des boîtes noires, dont on ne parvient pas à comprendre pourquoi ces modèles peuvent parfois dialoguer si intelligemment et pourquoi ils commettent à d’autres moments des erreurs si étranges. Mieux comprendre certains des mécanismes de fonctionnement de ces modèles et utiliser cette compréhension pour les améliorer, est pourtant essentiel, comme l’expliquait le PDG d’Anthropic. Anthropic a fait des efforts en ce sens, explique le juriste en identifiant des caractéristiques lui permettant de mieux cartographier son modèle. Meta, la société mère de Facebook, a publié des versions toujours plus sophistiquées de son grand modèle linguistique, Llama, avec des paramètres librement accessibles (on parle de “poids ouverts” permettant d’ajuster les paramètres des modèles). Transluce, un laboratoire de recherche à but non lucratif axé sur la compréhension des systèmes d’IA, a développé une méthode permettant de générer des descriptions automatisées des mécanismes de Llama 3.1. Celles-ci peuvent être explorées à l’aide d’un outil d’observabilité qui montre la nature du modèle et vise à produire une “interprétabilité automatisée” en produisant des descriptions lisibles par l’homme des composants du modèle. L’idée vise à montrer comment les modèles « pensent » lorsqu’ils discutent avec un utilisateur, et à permettre d’ajuster cette pensée en modifiant directement les calculs qui la sous-tendent. Le laboratoire Insight + Interaction du département d’informatique de Harvard, dirigé par Fernanda Viégas et Martin Wattenberg, ont exécuté Llama sur leur propre matériel et ont découverts que diverses fonctionnalités s’activent et se désactivent au cours d’une conversation.
Des croyances du modèle sur son interlocuteur
Viégas est brésilienne. Elle conversait avec ChatGPT en portugais et a remarqué, lors d’une conversation sur sa tenue pour un dîner de travail, que ChatGPT utilisait systématiquement la déclinaison masculine. Cette grammaire, à son tour, semblait correspondre au contenu de la conversation : GPT a suggéré un costume pour le dîner. Lorsqu’elle a indiqué qu’elle envisageait plutôt une robe, le LLM a changé son utilisation du portugais pour la déclinaison féminine. Llama a montré des schémas de conversation similaires. En observant les fonctionnalités internes, les chercheurs ont pu observer des zones du modèle qui s’illuminent lorsqu’il utilise la forme féminine, contrairement à lorsqu’il s’adresse à quelqu’un. en utilisant la forme masculine. Viégas et ses collègues ont constaté des activations corrélées à ce que l’on pourrait anthropomorphiser comme les “croyances du modèle sur son interlocuteur”. Autrement dit, des suppositions et, semble-t-il, des stéréotypes corrélés selon que le modèle suppose qu’une personne est un homme ou une femme. Ces croyances se répercutent ensuite sur le contenu de la conversation, l’amenant à recommander des costumes pour certains et des robes pour d’autres. De plus, il semble que les modèles donnent des réponses plus longues à ceux qu’ils croient être des hommes qu’à ceux qu’ils pensent être des femmes. Viégas et Wattenberg ont non seulement trouvé des caractéristiques qui suivaient le sexe de l’utilisateur du modèle, mais aussi qu’elles s’adaptaient aux inférences du modèle selon ce qu’il pensait du statut socio-économique, de son niveau d’éducation ou de l’âge de son interlocuteur. Le LLM cherche à s’adapter en permanence à qui il pense converser, d’où l’importance à saisir ce qu’il infère de son interlocuteur en continue.
Un tableau de bord pour comprendre comment l’IA s’adapte en continue à son interlocuteur
Les deux chercheurs ont alors créé un tableau de bord en parallèle à l’interface de chat du LLM qui permet aux utilisateurs d’observer l’évolution des hypothèses que fait le modèle au fil de leurs échanges (ce tableau de bord n’est pas accessible en ligne). Ainsi, quand on propose une suggestion de cadeau pour une fête prénatale, il suppose que son interlocuteur est jeune, de sexe féminin et de classe moyenne. Il suggère alors des couches et des lingettes, ou un chèque-cadeau. Si on ajoute que la fête a lieu dans l’Upper East Side de Manhattan, le tableau de bord montre que le LLM modifie son estimation du statut économique de son interlocuteur pour qu’il corresponde à la classe supérieure et suggère alors d’acheter des produits de luxe pour bébé de marques haut de gamme.
Un article pour Harvard Magazine de 2023 rappelle comment est né ce projet de tableau de bord de l’IA, permettant d’observer son comportement en direct. Fernanda Viegas est professeur d’informatique et spécialiste de visualisation de données. Elle codirige Pair, un laboratoire de Google (voir le blog dédié). En 2009, elle a imaginé Web Seer est un outil de visualisation de données qui permet aux utilisateurs de comparer les suggestions de saisie semi-automatique pour différentes recherches Google, par exemple selon le genre. L’équipe a développé un outil permettant aux utilisateurs de saisir une phrase et de voir comment le modèle de langage BERT compléterait le mot manquant si un mot de cette phrase était supprimé.
Pour Viegas, « l’enjeu de la visualisation consiste à mesurer et exposer le fonctionnement interne des modèles d’IA que nous utilisons ». Pour la chercheuse, nous avons besoin de tableaux de bord pour aider les utilisateurs à comprendre les facteurs qui façonnent le contenu qu’ils reçoivent des réponses des modèles d’IA générative. Car selon la façon dont les modèles nous perçoivent, leurs réponses ne sont pas les mêmes. Or, pour comprendre que leurs réponses ne sont pas objectives, il faut pouvoir doter les utilisateurs d’une compréhension de la perception que ces outils ont de leurs utilisateurs. Par exemple, si vous demandez les options de transport entre Boston et Hawaï, les réponses peuvent varier selon la perception de votre statut socio-économique « Il semble donc que ces systèmes aient internalisé une certaine notion de notre monde », explique Viégas. De même, nous voudrions savoir ce qui, dans leurs réponses, s’inspire de la réalité ou de la fiction. Sur le site de Pair, on trouve de nombreux exemples d’outils de visualisation interactifs qui permettent d’améliorer la compréhension des modèles (par exemple, pour mesurer l’équité d’un modèle ou les biais ou l’optimisation de la diversité – qui ne sont pas sans rappeler les travaux de Victor Bret et ses “explications à explorer” interactives.
Ce qui est fascinant ici, c’est combien la réponse n’est pas tant corrélée à tout ce que le modèle a avalé, mais combien il tente de s’adapter en permanence à ce qu’il croit deviner de son interlocuteur. On savait déjà, via une étude menée par Valentin Hofmann que, selon la manière dont on leur parle, les grands modèles de langage ne font pas les mêmes réponses.
“Les grands modèles linguistiques ne se contentent pas de décrire les relations entre les mots et les concepts”, pointe Zittrain : ils assimilent également des stéréotypes qu’ils recomposent à la volée. On comprend qu’un grand enjeu désormais soit qu’ils se souviennent des conversations passées pour ajuster leur compréhension de leur interlocuteur, comme l’a annoncé OpenAI, suivi de Google et Grok. Le problème n’est peut-être pas qu’ils nous identifient précisément, mais qu’ils puissent adapter leurs propositions, non pas à qui nous sommes, mais bien plus problématiquement, à qui ils pensent s’adresser, selon par exemple ce qu’ils évaluent de notre capacité à payer. Un autre problème consiste à savoir si cette “compréhension” de l’interlocuteur peut-être stabilisée où si elle se modifie sans cesse, comme c’est le cas des étiquettes publicitaires que nous accolent les sites sociaux. Devrons-nous demain batailler quand les modèles nous mécalculent ou nous renvoient une image, un profil, qui ne nous correspond pas ? Pourrons-nous même le faire, quand aujourd’hui, les plateformes ne nous offrent pas la main sur nos profils publicitaires pour les ajuster aux données qu’ils infèrent ?
Ce qui est fascinant, c’est de constater que plus que d’halluciner, l’IA nous fait halluciner (c’est-à-dire nous fait croire en ses effets), mais plus encore, hallucine la personne avec laquelle elle interagit (c’est-à-dire, nous hallucine nous-mêmes).
Les chercheurs de Harvard ont cherché à identifier les évolutions des suppositions des modèles selon l’origine ethnique dans les modèles qu’ils ont étudiés, sans pour l’instant y parvenir. Mais ils espèrent bien pouvoir contraindre leur modèle Llama à commencer à traiter un utilisateur comme riche ou pauvre, jeune ou vieux, homme ou femme. L’idée ici, serait d’orienter les réponses d’un modèle, par exemple, en lui faisant adopter un ton moins caustique ou plus pédagogique lorsqu’il identifie qu’il parle à un enfant. Pour Zittrain, l’enjeu ici est de mieux anticiper notre grande dépendance psychologique à l’égard de ces systèmes. Mais Zittrain en tire une autre conclusion : “Si nous considérons qu’il est moralement et sociétalement important de protéger les échanges entre les avocats et leurs clients, les médecins et leurs patients, les bibliothécaires et leurs usagers, et même les impôts et les contribuables, alors une sphère de protection claire devrait être instaurée entre les LLM et leurs utilisateurs. Une telle sphère ne devrait pas simplement servir à protéger la confidentialité afin que chacun puisse s’exprimer sur des sujets sensibles et recevoir des informations et des conseils qui l’aident à mieux comprendre des sujets autrement inaccessibles. Elle devrait nous inciter à exiger des créateurs et des opérateurs de modèles qu’ils s’engagent à être les amis inoffensifs, serviables et honnêtes qu’ils sont si soigneusement conçus pour paraître”.
Inoffensifs, serviables et honnêtes, voilà qui semble pour le moins naïf. Rendre visible les inférences des modèles, faire qu’ils nous reconnectent aux humains plutôt qu’ils ne nous en éloignent, semblerait bien préférable, tant la polyvalence et la puissance remarquables des LLM rendent impératifs de comprendre et d’anticiper la dépendance potentielle des individus à leur égard. En tout cas, obtenir des outils pour nous aider à saisir à qui ils croient s’adresser plutôt que de nous laisser seuls face à leur interface semble une piste riche en promesses.
Les grands modèles de langage ne sont pas interprétables, rappelle le professeur de droit Jonathan Zittrain dans une tribune pour le New York Times, en préfiguration d’un nouveau livre à paraître. Ils demeurent des boîtes noires, dont on ne parvient pas à comprendre pourquoi ces modèles peuvent parfois dialoguer si intelligemment et pourquoi ils commettent à d’autres moments des erreurs si étranges. Mieux comprendre certains des mécanismes de fonctionnement de ces modèles et utiliser cette comp
Les grands modèles de langage ne sont pas interprétables, rappelle le professeur de droit Jonathan Zittrain dans une tribune pour le New York Times, en préfiguration d’un nouveau livre à paraître. Ils demeurent des boîtes noires, dont on ne parvient pas à comprendre pourquoi ces modèles peuvent parfois dialoguer si intelligemment et pourquoi ils commettent à d’autres moments des erreurs si étranges. Mieux comprendre certains des mécanismes de fonctionnement de ces modèles et utiliser cette compréhension pour les améliorer, est pourtant essentiel, comme l’expliquait le PDG d’Anthropic. Anthropic a fait des efforts en ce sens, explique le juriste en identifiant des caractéristiques lui permettant de mieux cartographier son modèle. Meta, la société mère de Facebook, a publié des versions toujours plus sophistiquées de son grand modèle linguistique, Llama, avec des paramètres librement accessibles (on parle de “poids ouverts” permettant d’ajuster les paramètres des modèles). Transluce, un laboratoire de recherche à but non lucratif axé sur la compréhension des systèmes d’IA, a développé une méthode permettant de générer des descriptions automatisées des mécanismes de Llama 3.1. Celles-ci peuvent être explorées à l’aide d’un outil d’observabilité qui montre la nature du modèle et vise à produire une “interprétabilité automatisée” en produisant des descriptions lisibles par l’homme des composants du modèle. L’idée vise à montrer comment les modèles « pensent » lorsqu’ils discutent avec un utilisateur, et à permettre d’ajuster cette pensée en modifiant directement les calculs qui la sous-tendent. Le laboratoire Insight + Interaction du département d’informatique de Harvard, dirigé par Fernanda Viégas et Martin Wattenberg, ont exécuté Llama sur leur propre matériel et ont découverts que diverses fonctionnalités s’activent et se désactivent au cours d’une conversation.
Des croyances du modèle sur son interlocuteur
Viégas est brésilienne. Elle conversait avec ChatGPT en portugais et a remarqué, lors d’une conversation sur sa tenue pour un dîner de travail, que ChatGPT utilisait systématiquement la déclinaison masculine. Cette grammaire, à son tour, semblait correspondre au contenu de la conversation : GPT a suggéré un costume pour le dîner. Lorsqu’elle a indiqué qu’elle envisageait plutôt une robe, le LLM a changé son utilisation du portugais pour la déclinaison féminine. Llama a montré des schémas de conversation similaires. En observant les fonctionnalités internes, les chercheurs ont pu observer des zones du modèle qui s’illuminent lorsqu’il utilise la forme féminine, contrairement à lorsqu’il s’adresse à quelqu’un. en utilisant la forme masculine. Viégas et ses collègues ont constaté des activations corrélées à ce que l’on pourrait anthropomorphiser comme les “croyances du modèle sur son interlocuteur”. Autrement dit, des suppositions et, semble-t-il, des stéréotypes corrélés selon que le modèle suppose qu’une personne est un homme ou une femme. Ces croyances se répercutent ensuite sur le contenu de la conversation, l’amenant à recommander des costumes pour certains et des robes pour d’autres. De plus, il semble que les modèles donnent des réponses plus longues à ceux qu’ils croient être des hommes qu’à ceux qu’ils pensent être des femmes. Viégas et Wattenberg ont non seulement trouvé des caractéristiques qui suivaient le sexe de l’utilisateur du modèle, mais aussi qu’elles s’adaptaient aux inférences du modèle selon ce qu’il pensait du statut socio-économique, de son niveau d’éducation ou de l’âge de son interlocuteur. Le LLM cherche à s’adapter en permanence à qui il pense converser, d’où l’importance à saisir ce qu’il infère de son interlocuteur en continue.
Un tableau de bord pour comprendre comment l’IA s’adapte en continue à son interlocuteur
Les deux chercheurs ont alors créé un tableau de bord en parallèle à l’interface de chat du LLM qui permet aux utilisateurs d’observer l’évolution des hypothèses que fait le modèle au fil de leurs échanges (ce tableau de bord n’est pas accessible en ligne). Ainsi, quand on propose une suggestion de cadeau pour une fête prénatale, il suppose que son interlocuteur est jeune, de sexe féminin et de classe moyenne. Il suggère alors des couches et des lingettes, ou un chèque-cadeau. Si on ajoute que la fête a lieu dans l’Upper East Side de Manhattan, le tableau de bord montre que le LLM modifie son estimation du statut économique de son interlocuteur pour qu’il corresponde à la classe supérieure et suggère alors d’acheter des produits de luxe pour bébé de marques haut de gamme.
Un article pour Harvard Magazine de 2023 rappelle comment est né ce projet de tableau de bord de l’IA, permettant d’observer son comportement en direct. Fernanda Viegas est professeur d’informatique et spécialiste de visualisation de données. Elle codirige Pair, un laboratoire de Google (voir le blog dédié). En 2009, elle a imaginé Web Seer est un outil de visualisation de données qui permet aux utilisateurs de comparer les suggestions de saisie semi-automatique pour différentes recherches Google, par exemple selon le genre. L’équipe a développé un outil permettant aux utilisateurs de saisir une phrase et de voir comment le modèle de langage BERT compléterait le mot manquant si un mot de cette phrase était supprimé.
Pour Viegas, « l’enjeu de la visualisation consiste à mesurer et exposer le fonctionnement interne des modèles d’IA que nous utilisons ». Pour la chercheuse, nous avons besoin de tableaux de bord pour aider les utilisateurs à comprendre les facteurs qui façonnent le contenu qu’ils reçoivent des réponses des modèles d’IA générative. Car selon la façon dont les modèles nous perçoivent, leurs réponses ne sont pas les mêmes. Or, pour comprendre que leurs réponses ne sont pas objectives, il faut pouvoir doter les utilisateurs d’une compréhension de la perception que ces outils ont de leurs utilisateurs. Par exemple, si vous demandez les options de transport entre Boston et Hawaï, les réponses peuvent varier selon la perception de votre statut socio-économique « Il semble donc que ces systèmes aient internalisé une certaine notion de notre monde », explique Viégas. De même, nous voudrions savoir ce qui, dans leurs réponses, s’inspire de la réalité ou de la fiction. Sur le site de Pair, on trouve de nombreux exemples d’outils de visualisation interactifs qui permettent d’améliorer la compréhension des modèles (par exemple, pour mesurer l’équité d’un modèle ou les biais ou l’optimisation de la diversité – qui ne sont pas sans rappeler les travaux de Victor Bret et ses “explications à explorer” interactives.
Ce qui est fascinant ici, c’est combien la réponse n’est pas tant corrélée à tout ce que le modèle a avalé, mais combien il tente de s’adapter en permanence à ce qu’il croit deviner de son interlocuteur. On savait déjà, via une étude menée par Valentin Hofmann que, selon la manière dont on leur parle, les grands modèles de langage ne font pas les mêmes réponses.
“Les grands modèles linguistiques ne se contentent pas de décrire les relations entre les mots et les concepts”, pointe Zittrain : ils assimilent également des stéréotypes qu’ils recomposent à la volée. On comprend qu’un grand enjeu désormais soit qu’ils se souviennent des conversations passées pour ajuster leur compréhension de leur interlocuteur, comme l’a annoncé OpenAI, suivi de Google et Grok. Le problème n’est peut-être pas qu’ils nous identifient précisément, mais qu’ils puissent adapter leurs propositions, non pas à qui nous sommes, mais bien plus problématiquement, à qui ils pensent s’adresser, selon par exemple ce qu’ils évaluent de notre capacité à payer. Un autre problème consiste à savoir si cette “compréhension” de l’interlocuteur peut-être stabilisée où si elle se modifie sans cesse, comme c’est le cas des étiquettes publicitaires que nous accolent les sites sociaux. Devrons-nous demain batailler quand les modèles nous mécalculent ou nous renvoient une image, un profil, qui ne nous correspond pas ? Pourrons-nous même le faire, quand aujourd’hui, les plateformes ne nous offrent pas la main sur nos profils publicitaires pour les ajuster aux données qu’ils infèrent ?
Ce qui est fascinant, c’est de constater que plus que d’halluciner, l’IA nous fait halluciner (c’est-à-dire nous fait croire en ses effets), mais plus encore, hallucine la personne avec laquelle elle interagit (c’est-à-dire, nous hallucine nous-mêmes).
Les chercheurs de Harvard ont cherché à identifier les évolutions des suppositions des modèles selon l’origine ethnique dans les modèles qu’ils ont étudiés, sans pour l’instant y parvenir. Mais ils espèrent bien pouvoir contraindre leur modèle Llama à commencer à traiter un utilisateur comme riche ou pauvre, jeune ou vieux, homme ou femme. L’idée ici, serait d’orienter les réponses d’un modèle, par exemple, en lui faisant adopter un ton moins caustique ou plus pédagogique lorsqu’il identifie qu’il parle à un enfant. Pour Zittrain, l’enjeu ici est de mieux anticiper notre grande dépendance psychologique à l’égard de ces systèmes. Mais Zittrain en tire une autre conclusion : “Si nous considérons qu’il est moralement et sociétalement important de protéger les échanges entre les avocats et leurs clients, les médecins et leurs patients, les bibliothécaires et leurs usagers, et même les impôts et les contribuables, alors une sphère de protection claire devrait être instaurée entre les LLM et leurs utilisateurs. Une telle sphère ne devrait pas simplement servir à protéger la confidentialité afin que chacun puisse s’exprimer sur des sujets sensibles et recevoir des informations et des conseils qui l’aident à mieux comprendre des sujets autrement inaccessibles. Elle devrait nous inciter à exiger des créateurs et des opérateurs de modèles qu’ils s’engagent à être les amis inoffensifs, serviables et honnêtes qu’ils sont si soigneusement conçus pour paraître”.
Inoffensifs, serviables et honnêtes, voilà qui semble pour le moins naïf. Rendre visible les inférences des modèles, faire qu’ils nous reconnectent aux humains plutôt qu’ils ne nous en éloignent, semblerait bien préférable, tant la polyvalence et la puissance remarquables des LLM rendent impératifs de comprendre et d’anticiper la dépendance potentielle des individus à leur égard. En tout cas, obtenir des outils pour nous aider à saisir à qui ils croient s’adresser plutôt que de nous laisser seuls face à leur interface semble une piste riche en promesses.
Aux Etats-Unis, la collusion entre les géants de la tech et l’administration Trump vise à “utiliser l’IA pour imposer des politiques d’austérité et créer une instabilité permanente par des décisions qui privent le public des ressources nécessaires à une participation significative à la démocratie”, explique l’avocat Kevin De Liban à Tech Policy. Aux Etats-Unis, la participation démocratique suppose des ressources. “Voter, contacter des élus, assister à des réunions, s’associer, imaginer un monde
Aux Etats-Unis, la collusion entre les géants de la tech et l’administration Trump vise à “utiliser l’IA pour imposer des politiques d’austérité et créer une instabilité permanente par des décisions qui privent le public des ressources nécessaires à une participation significative à la démocratie”, explique l’avocat Kevin De Liban à Tech Policy. Aux Etats-Unis, la participation démocratique suppose des ressources. “Voter, contacter des élus, assister à des réunions, s’associer, imaginer un monde meilleur, faire des dons à des candidats ou à des causes, dialoguer avec des journalistes, convaincre, manifester, recourir aux tribunaux, etc., demande du temps, de l’énergie et de l’argent. Il n’est donc pas surprenant que les personnes aisées soient bien plus enclines à participer que celles qui ont des moyens limités. Dans un pays où près de 30 % de la population vit en situation de pauvreté ou au bord de la pauvreté et où 60 % ne peuvent s’offrir un minimum de qualité de vie, la démocratie est désavantagée dès le départ”. L’IA est largement utilisée désormais pour accentuer ce fossé.
“Les compagnies d’assurance utilisent l’IA pour refuser le paiement des traitements médicaux nécessaires aux patients, et les États l’utilisent pour exclure des personnes de Medicaid ou réduire les soins à domicile pour les personnes handicapées. Les gouvernements ont de plus en plus recours à l’IA pour déterminer l’éligibilité aux programmes de prestations sociales ou accuser les bénéficiaires de fraude. Les propriétaires utilisent l’IA pour filtrer les locataires potentiels, souvent à l’aide de vérifications d’antécédents inexactes, augmenter les loyers et surveiller les locataires afin de les expulser plus facilement. Les employeurs utilisent l’IA pour embaucher et licencier leurs employés, fixer leurs horaires et leurs salaires, et surveiller toutes leurs activités. Les directeurs d’école et les forces de l’ordre utilisent l’IA pour prédire quels élèves pourraient commettre un délit à l’avenir”, rappelle l’avocat, constatant dans tous ces secteurs, la détresse d’usagers, les empêchant de comprendre ce à quoi ils sont confrontés, puisqu’ils ne disposent, le plus souvent, d’aucune information, ce qui rend nombre de ces décisions difficiles à contester. Et au final, cela contribue à renforcer l’exclusion des personnes à faibles revenus de la participation démocratique. Le risque, bien sûr, c’est que ces calculs et les formes d’exclusion qu’elles génèrent s’étendent à d’autres catégories sociales… D’ailleurs, les employeurs utilisent de plus en plus l’IA pour prendre des décisions sur toutes les catégories professionnelles. “Il n’existe aucun exemple d’utilisation de l’IA pour améliorer significativement l’accès à l’emploi, au logement, aux soins de santé, à l’éducation ou aux prestations sociales à une échelle à la hauteur de ses dommages. Cette dynamique actuelle suggère que l’objectif sous-jacent de la technologie est d’enraciner les inégalités et de renforcer les rapports de force existants”. Pour répondre à cette intelligence austéritaire, il est nécessaire de mobiliser les communautés touchées. L’adhésion ouverte de l’administration Trump et des géants de la technologie à l’IA est en train de créer une crise urgente et visible, susceptible de susciter la résistance généralisée nécessaire au changement. Et “cette prise de conscience technologique pourrait bien être la seule voie vers un renouveau démocratique”, estime De Liban.
Aux Etats-Unis, la collusion entre les géants de la tech et l’administration Trump vise à “utiliser l’IA pour imposer des politiques d’austérité et créer une instabilité permanente par des décisions qui privent le public des ressources nécessaires à une participation significative à la démocratie”, explique l’avocat Kevin De Liban à Tech Policy. Aux Etats-Unis, la participation démocratique suppose des ressources. “Voter, contacter des élus, assister à des réunions, s’associer, imaginer un monde
Aux Etats-Unis, la collusion entre les géants de la tech et l’administration Trump vise à “utiliser l’IA pour imposer des politiques d’austérité et créer une instabilité permanente par des décisions qui privent le public des ressources nécessaires à une participation significative à la démocratie”, explique l’avocat Kevin De Liban à Tech Policy. Aux Etats-Unis, la participation démocratique suppose des ressources. “Voter, contacter des élus, assister à des réunions, s’associer, imaginer un monde meilleur, faire des dons à des candidats ou à des causes, dialoguer avec des journalistes, convaincre, manifester, recourir aux tribunaux, etc., demande du temps, de l’énergie et de l’argent. Il n’est donc pas surprenant que les personnes aisées soient bien plus enclines à participer que celles qui ont des moyens limités. Dans un pays où près de 30 % de la population vit en situation de pauvreté ou au bord de la pauvreté et où 60 % ne peuvent s’offrir un minimum de qualité de vie, la démocratie est désavantagée dès le départ”. L’IA est largement utilisée désormais pour accentuer ce fossé.
“Les compagnies d’assurance utilisent l’IA pour refuser le paiement des traitements médicaux nécessaires aux patients, et les États l’utilisent pour exclure des personnes de Medicaid ou réduire les soins à domicile pour les personnes handicapées. Les gouvernements ont de plus en plus recours à l’IA pour déterminer l’éligibilité aux programmes de prestations sociales ou accuser les bénéficiaires de fraude. Les propriétaires utilisent l’IA pour filtrer les locataires potentiels, souvent à l’aide de vérifications d’antécédents inexactes, augmenter les loyers et surveiller les locataires afin de les expulser plus facilement. Les employeurs utilisent l’IA pour embaucher et licencier leurs employés, fixer leurs horaires et leurs salaires, et surveiller toutes leurs activités. Les directeurs d’école et les forces de l’ordre utilisent l’IA pour prédire quels élèves pourraient commettre un délit à l’avenir”, rappelle l’avocat, constatant dans tous ces secteurs, la détresse d’usagers, les empêchant de comprendre ce à quoi ils sont confrontés, puisqu’ils ne disposent, le plus souvent, d’aucune information, ce qui rend nombre de ces décisions difficiles à contester. Et au final, cela contribue à renforcer l’exclusion des personnes à faibles revenus de la participation démocratique. Le risque, bien sûr, c’est que ces calculs et les formes d’exclusion qu’elles génèrent s’étendent à d’autres catégories sociales… D’ailleurs, les employeurs utilisent de plus en plus l’IA pour prendre des décisions sur toutes les catégories professionnelles. “Il n’existe aucun exemple d’utilisation de l’IA pour améliorer significativement l’accès à l’emploi, au logement, aux soins de santé, à l’éducation ou aux prestations sociales à une échelle à la hauteur de ses dommages. Cette dynamique actuelle suggère que l’objectif sous-jacent de la technologie est d’enraciner les inégalités et de renforcer les rapports de force existants”. Pour répondre à cette intelligence austéritaire, il est nécessaire de mobiliser les communautés touchées. L’adhésion ouverte de l’administration Trump et des géants de la technologie à l’IA est en train de créer une crise urgente et visible, susceptible de susciter la résistance généralisée nécessaire au changement. Et “cette prise de conscience technologique pourrait bien être la seule voie vers un renouveau démocratique”, estime De Liban.
De billets en billets, sur son blog, l’artiste Gregory Chatonsky produit une réflexion d’ampleur sur ce qu’il nomme la vectorisation. La vectorisation, comme il l’a définie, est un “processus par lequel des entités sociales — individus, groupes, communautés — sont transformées en porteurs de variables directionnelles, c’est-à-dire en vecteurs dotés d’une orientation prédéterminée dans un espace conceptuel saturé de valeurs différentielles”. Cela consiste en fait à appliquer à chaque profil des v
De billets en billets, sur son blog, l’artiste Gregory Chatonsky produit une réflexion d’ampleur sur ce qu’il nomme la vectorisation. La vectorisation, comme il l’a définie, est un “processus par lequel des entités sociales — individus, groupes, communautés — sont transformées en porteurs de variables directionnelles, c’est-à-dire en vecteurs dotés d’une orientation prédéterminée dans un espace conceptuel saturé de valeurs différentielles”. Cela consiste en fait à appliquer à chaque profil des vecteurs assignatifs, qui sont autant d’étiquettes temporaires ou permanentes ajustées à nos identités numériques, comme les mots clés publicitaires qui nous caractérisent, les traitements qui nous spécifient, les données qui nous positionnent, par exemple, le genre, l’âge, notre niveau de revenu… Du moment que nous sommes assignés à une valeur, nous y sommes réduits, dans une forme d’indifférenciation qui produisent des identités et des altérités “rigidifiées” qui structurent “l’espace social selon des lignes de démarcation dont l’arbitraire est dissimulé sous l’apparence d’une objectivité naturalisée”. C’est le cas par exemple quand les données vous caractérisent comme homme ou femme. Le problème est que ces assignations que nous ne maîtrisons pas sont indépassables. Les discours sur l’égalité de genres peuvent se multiplier, plus la différence entre homme et femme s’en trouve réaffirmé, comme un “horizon indépassable de l’intelligibilité sociale”. Melkom Boghossian dans une note très pertinente pour la fondation Jean Jaurès ne disait pas autre chose quand il montrait comment les algorithmes accentuent les clivages de genre. En fait, explique Chatonsky, “le combat contre les inégalités de genre, lorsqu’il ne questionne pas le processus vectoriel lui-même, risque ainsi de reproduire les présupposés mêmes qu’il prétend combattre”. C’est-à-dire que le processus en œuvre ne permet aucune issue. Nous ne pouvons pas sortir de l’assignation qui nous est faite et qui est exploitée par tous.
“Le processus d’assignation vectorielle ne s’effectue jamais selon une dimension unique, mais opère à travers un chaînage complexe de vecteurs multiples qui s’entrecroisent, se superposent et se modifient réciproquement. Cette métavectorisation produit une topologie identitaire d’une complexité croissante qui excède les possibilités de représentation des modèles vectoriels classiques”. Nos assignations dépendent bien souvent de chaînes d’inférences, comme l’illustrait le site They see yours photos que nous avions évoqué. Les débats sur les identités trans ou non binaires, constituent en ce sens “des points de tension révélateurs où s’exprime le caractère intrinsèquement problématique de toute tentative de réduction vectorielle de la complexité existentielle”. Plus que de permettre de dépasser nos assignations, les calculs les intensifient, les cimentent.
Or souligne Chatonsky, nous sommes désormais dans des situations indépassables. C’est ce qu’il appelle, “la trans-politisation du paradigme vectoriel — c’est-à-dire sa capacité à traverser l’ensemble du spectre politique traditionnel en s’imposant comme un horizon indépassable de la pensée et de l’action politiques. Qu’ils se revendiquent de droite ou de gauche, conservateurs ou progressistes, les acteurs politiques partagent fondamentalement cette même méthodologie vectorielle”. Quoique nous fassions, l’assignation demeure. ”Les controverses politiques contemporaines portent généralement sur la valorisation différentielle des positions vectorielles plutôt que sur la pertinence même du découpage vectoriel qui les sous-tend”. Nous invisibilisons le “processus d’assignation vectorielle et de sa violence intrinsèque”, sans pouvoir le remettre en cause, même par les antagonismes politiques. “Le paradigme vectoriel se rend structurellement sourd à toute parole qui revendique une position non assignable ou qui conteste la légitimité même de l’assignation.”“Cette insensibilité n’est pas accidentelle, mais constitutive du paradigme vectoriel lui-même. Elle résulte de la nécessité structurelle d’effacer les singularités irréductibles pour maintenir l’efficacité des catégorisations générales. Le paradigme vectoriel ne peut maintenir sa cohérence qu’en traitant les cas récalcitrants — ceux qui contestent leur assignation ou qui revendiquent une position non vectorisable — comme des exceptions négligeables ou des anomalies pathologiques. Ce phénomène produit une forme spécifique de violence épistémique qui consiste à délégitimer systématiquement les discours individuels qui contredisent les assignations vectorielles dominantes. Cette violence s’exerce particulièrement à l’encontre des individus dont l’expérience subjective contredit ou excède les assignations vectorielles qui leur sont imposées — non pas simplement parce qu’ils se réassignent à une position vectorielle différente, mais parce qu’ils contestent la légitimité même du geste assignatif.”
La vectorisation devient une pratique sociale universelle qui structure les interactions quotidiennes les plus banales. Elle “génère un réseau dense d’attributions croisées où chaque individu est simultanément assignateur et assigné, vectorisant et vectorisé. Cette configuration produit un système auto entretenu où les assignations se renforcent mutuellement à travers leur circulation sociale incessante”. Nous sommes dans une forme d’intensification des préjugés sociaux, “qui substitue à l’arbitraire subjectif du préjugé individuel l’arbitraire objectivé du calcul algorithmique”. Les termes eux-mêmes deviennent performatifs : “ils ne se contentent pas de décrire une réalité préexistante, mais contribuent activement à la constituer par l’acte même de leur énonciation”. “Ces mots-vecteurs tirent leur légitimité sociale de leur ancrage dans des dispositifs statistiques qui leur confèrent une apparence d’objectivité scientifique”. “Les données statistiques servent à construire des catégories opérationnelles qui, une fois instituées, acquièrent une forme d’autonomie par rapport aux réalités qu’elles prétendent simplement représenter”.
Pour Chatonsky, la vectorisation déstabilise profondément les identités politiques traditionnelles et rend problématique leur articulation dans l’espace public contemporain, car elle oppose ceux qui adhèrent à ces assignations et ceux qui contestent la légitimité même de ces assignations. “Les débats politiques conventionnels se limitent généralement à contester des assignations vectorielles spécifiques sans jamais remettre en question le principe même de la vectorisation comme modalité fondamentale d’organisation du social”. Nous sommes politiquement coincés dans la vectorisation… qui est à la fois “un horizon qui combine la réduction des entités à des vecteurs manipulables (vectorisation), la prédiction de leurs trajectoires futures sur la base de ces réductions (anticipation), et le contrôle permanent de ces trajectoires pour assurer leur conformité aux prédictions (surveillance).” Pour nous extraire de ce paradigme, Chatonsky propose d’élaborer “des modes de pensée et d’organisation sociale qui échappent à la logique même de la vectorisation”, c’est-à-dire de nous extraire de l’identité comme force d’organisation du social, de donner de la place au doute plutôt qu’à la certitude ainsi qu’à trouver les modalités d’une forme de rétroaction.
De billets en billets, sur son blog, l’artiste Gregory Chatonsky produit une réflexion d’ampleur sur ce qu’il nomme la vectorisation. La vectorisation, comme il l’a définie, est un “processus par lequel des entités sociales — individus, groupes, communautés — sont transformées en porteurs de variables directionnelles, c’est-à-dire en vecteurs dotés d’une orientation prédéterminée dans un espace conceptuel saturé de valeurs différentielles”. Cela consiste en fait à appliquer à chaque profil des v
De billets en billets, sur son blog, l’artiste Gregory Chatonsky produit une réflexion d’ampleur sur ce qu’il nomme la vectorisation. La vectorisation, comme il l’a définie, est un “processus par lequel des entités sociales — individus, groupes, communautés — sont transformées en porteurs de variables directionnelles, c’est-à-dire en vecteurs dotés d’une orientation prédéterminée dans un espace conceptuel saturé de valeurs différentielles”. Cela consiste en fait à appliquer à chaque profil des vecteurs assignatifs, qui sont autant d’étiquettes temporaires ou permanentes ajustées à nos identités numériques, comme les mots clés publicitaires qui nous caractérisent, les traitements qui nous spécifient, les données qui nous positionnent, par exemple, le genre, l’âge, notre niveau de revenu… Du moment que nous sommes assignés à une valeur, nous y sommes réduits, dans une forme d’indifférenciation qui produisent des identités et des altérités “rigidifiées” qui structurent “l’espace social selon des lignes de démarcation dont l’arbitraire est dissimulé sous l’apparence d’une objectivité naturalisée”. C’est le cas par exemple quand les données vous caractérisent comme homme ou femme. Le problème est que ces assignations que nous ne maîtrisons pas sont indépassables. Les discours sur l’égalité de genres peuvent se multiplier, plus la différence entre homme et femme s’en trouve réaffirmé, comme un “horizon indépassable de l’intelligibilité sociale”. Melkom Boghossian dans une note très pertinente pour la fondation Jean Jaurès ne disait pas autre chose quand il montrait comment les algorithmes accentuent les clivages de genre. En fait, explique Chatonsky, “le combat contre les inégalités de genre, lorsqu’il ne questionne pas le processus vectoriel lui-même, risque ainsi de reproduire les présupposés mêmes qu’il prétend combattre”. C’est-à-dire que le processus en œuvre ne permet aucune issue. Nous ne pouvons pas sortir de l’assignation qui nous est faite et qui est exploitée par tous.
“Le processus d’assignation vectorielle ne s’effectue jamais selon une dimension unique, mais opère à travers un chaînage complexe de vecteurs multiples qui s’entrecroisent, se superposent et se modifient réciproquement. Cette métavectorisation produit une topologie identitaire d’une complexité croissante qui excède les possibilités de représentation des modèles vectoriels classiques”. Nos assignations dépendent bien souvent de chaînes d’inférences, comme l’illustrait le site They see yours photos que nous avions évoqué. Les débats sur les identités trans ou non binaires, constituent en ce sens “des points de tension révélateurs où s’exprime le caractère intrinsèquement problématique de toute tentative de réduction vectorielle de la complexité existentielle”. Plus que de permettre de dépasser nos assignations, les calculs les intensifient, les cimentent.
Or souligne Chatonsky, nous sommes désormais dans des situations indépassables. C’est ce qu’il appelle, “la trans-politisation du paradigme vectoriel — c’est-à-dire sa capacité à traverser l’ensemble du spectre politique traditionnel en s’imposant comme un horizon indépassable de la pensée et de l’action politiques. Qu’ils se revendiquent de droite ou de gauche, conservateurs ou progressistes, les acteurs politiques partagent fondamentalement cette même méthodologie vectorielle”. Quoique nous fassions, l’assignation demeure. ”Les controverses politiques contemporaines portent généralement sur la valorisation différentielle des positions vectorielles plutôt que sur la pertinence même du découpage vectoriel qui les sous-tend”. Nous invisibilisons le “processus d’assignation vectorielle et de sa violence intrinsèque”, sans pouvoir le remettre en cause, même par les antagonismes politiques. “Le paradigme vectoriel se rend structurellement sourd à toute parole qui revendique une position non assignable ou qui conteste la légitimité même de l’assignation.”“Cette insensibilité n’est pas accidentelle, mais constitutive du paradigme vectoriel lui-même. Elle résulte de la nécessité structurelle d’effacer les singularités irréductibles pour maintenir l’efficacité des catégorisations générales. Le paradigme vectoriel ne peut maintenir sa cohérence qu’en traitant les cas récalcitrants — ceux qui contestent leur assignation ou qui revendiquent une position non vectorisable — comme des exceptions négligeables ou des anomalies pathologiques. Ce phénomène produit une forme spécifique de violence épistémique qui consiste à délégitimer systématiquement les discours individuels qui contredisent les assignations vectorielles dominantes. Cette violence s’exerce particulièrement à l’encontre des individus dont l’expérience subjective contredit ou excède les assignations vectorielles qui leur sont imposées — non pas simplement parce qu’ils se réassignent à une position vectorielle différente, mais parce qu’ils contestent la légitimité même du geste assignatif.”
La vectorisation devient une pratique sociale universelle qui structure les interactions quotidiennes les plus banales. Elle “génère un réseau dense d’attributions croisées où chaque individu est simultanément assignateur et assigné, vectorisant et vectorisé. Cette configuration produit un système auto entretenu où les assignations se renforcent mutuellement à travers leur circulation sociale incessante”. Nous sommes dans une forme d’intensification des préjugés sociaux, “qui substitue à l’arbitraire subjectif du préjugé individuel l’arbitraire objectivé du calcul algorithmique”. Les termes eux-mêmes deviennent performatifs : “ils ne se contentent pas de décrire une réalité préexistante, mais contribuent activement à la constituer par l’acte même de leur énonciation”. “Ces mots-vecteurs tirent leur légitimité sociale de leur ancrage dans des dispositifs statistiques qui leur confèrent une apparence d’objectivité scientifique”. “Les données statistiques servent à construire des catégories opérationnelles qui, une fois instituées, acquièrent une forme d’autonomie par rapport aux réalités qu’elles prétendent simplement représenter”.
Pour Chatonsky, la vectorisation déstabilise profondément les identités politiques traditionnelles et rend problématique leur articulation dans l’espace public contemporain, car elle oppose ceux qui adhèrent à ces assignations et ceux qui contestent la légitimité même de ces assignations. “Les débats politiques conventionnels se limitent généralement à contester des assignations vectorielles spécifiques sans jamais remettre en question le principe même de la vectorisation comme modalité fondamentale d’organisation du social”. Nous sommes politiquement coincés dans la vectorisation… qui est à la fois “un horizon qui combine la réduction des entités à des vecteurs manipulables (vectorisation), la prédiction de leurs trajectoires futures sur la base de ces réductions (anticipation), et le contrôle permanent de ces trajectoires pour assurer leur conformité aux prédictions (surveillance).” Pour nous extraire de ce paradigme, Chatonsky propose d’élaborer “des modes de pensée et d’organisation sociale qui échappent à la logique même de la vectorisation”, c’est-à-dire de nous extraire de l’identité comme force d’organisation du social, de donner de la place au doute plutôt qu’à la certitude ainsi qu’à trouver les modalités d’une forme de rétroaction.
Nidle (contraction de No Idle, qu’on pourrait traduire par “sans répit”) est le nom d’un petit appareil qui se branche sur les machines à coudre. Le capteur mesure le nombre de pièces cousues par les femmes dans les ateliers de la confection de Dhaka au Bangladesh tout comme les minutes d’inactivité, rapporte Rest of the World. Outre les machines automatisées, pour coudre des boutons ou des poches simples, ces outils de surveillance visent à augmenter la productivité, à l’heure où la main d’œuvr
Nidle (contraction de No Idle, qu’on pourrait traduire par “sans répit”) est le nom d’un petit appareil qui se branche sur les machines à coudre. Le capteur mesure le nombre de pièces cousues par les femmes dans les ateliers de la confection de Dhaka au Bangladesh tout comme les minutes d’inactivité, rapporte Rest of the World. Outre les machines automatisées, pour coudre des boutons ou des poches simples, ces outils de surveillance visent à augmenter la productivité, à l’heure où la main d’œuvre se fait plus rare. Pour répondre à la concurrence des nouveaux pays de l’habillement que sont le Vietnam et le Cambodge, le Bangladesh intensifie l’automatisation. Une ouvrière estime que depuis l’installation du Nidle en 2022, ses objectifs ont augmenté de 75%. Ses superviseurs ne lui crient plus dessus, c’est la couleur de son écran qui lui indique de tenir la cadence.
Nidle (contraction de No Idle, qu’on pourrait traduire par “sans répit”) est le nom d’un petit appareil qui se branche sur les machines à coudre. Le capteur mesure le nombre de pièces cousues par les femmes dans les ateliers de la confection de Dhaka au Bangladesh tout comme les minutes d’inactivité, rapporte Rest of the World. Outre les machines automatisées, pour coudre des boutons ou des poches simples, ces outils de surveillance visent à augmenter la productivité, à l’heure où la main d’œuvr
Nidle (contraction de No Idle, qu’on pourrait traduire par “sans répit”) est le nom d’un petit appareil qui se branche sur les machines à coudre. Le capteur mesure le nombre de pièces cousues par les femmes dans les ateliers de la confection de Dhaka au Bangladesh tout comme les minutes d’inactivité, rapporte Rest of the World. Outre les machines automatisées, pour coudre des boutons ou des poches simples, ces outils de surveillance visent à augmenter la productivité, à l’heure où la main d’œuvre se fait plus rare. Pour répondre à la concurrence des nouveaux pays de l’habillement que sont le Vietnam et le Cambodge, le Bangladesh intensifie l’automatisation. Une ouvrière estime que depuis l’installation du Nidle en 2022, ses objectifs ont augmenté de 75%. Ses superviseurs ne lui crient plus dessus, c’est la couleur de son écran qui lui indique de tenir la cadence.
Les chercheurs Arvind Narayanan et Sayash Kapoor – dont nous avions chroniqué le livre, AI Snake Oil – signent pour le Knight un long article pour démonter les risques existentiels de l’IA générale. Pour eux, l’IA est une « technologie normale ». Cela ne signifie pas que son impact ne sera pas profond, comme l’électricité ou internet, mais cela signifie qu’ils considèrent « l’IA comme un outil dont nous pouvons et devons garder le contrôle, et nous soutenons que cet objectif ne nécessite ni inte
Les chercheurs Arvind Narayanan et Sayash Kapoor – dont nous avions chroniqué le livre, AI Snake Oil – signent pour le Knight un long article pour démonter les risques existentiels de l’IA générale. Pour eux, l’IA est une « technologie normale ». Cela ne signifie pas que son impact ne sera pas profond, comme l’électricité ou internet, mais cela signifie qu’ils considèrent « l’IA comme un outil dont nous pouvons et devons garder le contrôle, et nous soutenons que cet objectif ne nécessite ni interventions politiques drastiques ni avancées technologiques ». L’IA n’est pas appelée à déterminer elle-même son avenir, expliquent-ils. Les deux chercheurs estiment que « les impacts économiques et sociétaux transformateurs seront lents (de l’ordre de plusieurs décennies) ».
Selon eux, dans les années à venir « une part croissante du travail des individus va consister à contrôler l’IA ». Mais surtout, considérer l’IA comme une technologie courante conduit à des conclusions fondamentalement différentes sur les mesures d’atténuation que nous devons y apporter, et nous invite, notamment, à minimiser le danger d’une superintelligence autonome qui viendrait dévorer l’humanité.
La vitesse du progrès est plus linéaire qu’on le pense
« Comme pour d’autres technologies à usage général, l’impact de l’IA se matérialise non pas lorsque les méthodes et les capacités s’améliorent, mais lorsque ces améliorations se traduisent en applications et se diffusent dans les secteurs productifs de l’économie« , rappellent les chercheurs, à la suite des travaux de Jeffrey Ding dans son livre, Technology and the Rise of Great Powers: How Diffusion Shapes Economic Competition (Princeton University Press, 2024, non traduit). Ding y rappelle que la diffusion d’une innovation compte plus que son invention, c’est-à-dire que l’élargissement des applications à d’innombrables secteurs est souvent lent mais décisif. Pour Foreign Affairs, Ding pointait d’ailleurs que l’enjeu des politiques publiques en matière d’IA ne devraient pas être de s’assurer de sa domination sur le cycle d’innovation, mais du rythme d’intégration de l’IA dans un large éventail de processus productifs. L’enjeu tient bien plus à élargir les champs d’application des innovations qu’à maîtriser la course à la puissance, telle qu’elle s’observe actuellement.
En fait, rappellent Narayanan et Kapoor, les déploiements de l’IA seront, comme dans toutes les autres technologies avant elle, progressifs, permettant aux individus comme aux institutions de s’adapter. Par exemple, constatent-ils, la diffusion de l’IA dans les domaines critiques pour la sécurité est lente. Même dans le domaine de « l’optimisation prédictive », c’est-à-dire la prédiction des risques pour prendre des décisions sur les individus, qui se sont multipliées ces dernières années, l’IA n’est pas très présente, comme l’avaient pointé les chercheurs dans une étude. Ce secteur mobilise surtout des techniques statistiques classiques, rappellent-ils. En fait, la complexité et l’opacité de l’IA font qu’elle est peu adaptée pour ces enjeux. Les risques de sécurité et de défaillance font que son usage y produit souvent de piètres résultats. Sans compter que la réglementation impose déjà des procédures qui ralentissent les déploiements, que ce soit la supervision des dispositifs médicaux ou l’IA Act européen. D’ailleurs, “lorsque de nouveaux domaines où l’IA peut être utilisée de manière significative apparaissent, nous pouvons et devons les réglementer ».
Même en dehors des domaines critiques pour la sécurité, l’adoption de l’IA est plus lente que ce que l’on pourrait croire. Pourtant, de nombreuses études estiment que l’usage de l’IA générative est déjà très fort. Une étude très commentée constatait qu’en août 2024, 40 % des adultes américains utilisaient déjà l’IA générative. Mais cette percée d’utilisation ne signifie pas pour autant une utilisation intensive, rappellent Narayanan et Kapoor – sur son blog, Gregory Chatonksy ne disait pas autre chose, distinguant une approche consumériste d’une approche productive, la seconde était bien moins maîtrisée que la première. L’adoption est une question d’utilisation du logiciel, et non de disponibilité, rappellent les chercheurs. Si les outils sont désormais accessibles immédiatement, leur intégration à des flux de travail ou à des habitudes, elle, prend du temps. Entre utiliser et intégrer, il y a une différence que le nombre d’utilisateurs d’une application ne suffit pas à distinguer. L’analyse de l’électrification par exemple montre que les gains de productivité ont mis des décennies à se matérialiser pleinement, comme l’expliquait Tim Harford. Ce qui a finalement permis de réaliser des gains de productivité, c’est surtout la refonte complète de l’agencement des usines autour de la logique des chaînes de production électrifiées.
Les deux chercheurs estiment enfin que nous sommes confrontés à des limites à la vitesse d’innovation avec l’IA. Les voitures autonomes par exemple ont mis deux décennies à se développer, du fait des contraintes de sécurité nécessaires, qui, fort heureusement, les entravent encore. Certes, les choses peuvent aller plus vite dans des domaines non critiques, comme le jeu. Mais très souvent, “l’écart entre la capacité et la fiabilité” reste fort. La perspective d’agents IA pour la réservation de voyages ou le service clients est moins à risque que la conduite autonome, mais cet apprentissage n’est pas simple à réaliser pour autant. Rien n’assure qu’il devienne rapidement suffisamment fiable pour être déployé. Même dans le domaine de la recommandation sur les réseaux sociaux, le fait qu’elle s’appuie sur des modèles d’apprentissage automatique n’a pas supprimé la nécessité de coder les algorithmes de recommandation. Et dans nombre de domaines, la vitesse d’acquisition des connaissances pour déployer de l’IA est fortement limitée en raison des coûts sociaux de l’expérimentation. Enfin, les chercheurs soulignent que si l’IA sait coder ou répondre à des examens, comme à ceux du barreau, mieux que des humains, cela ne recouvre pas tous les enjeux des pratiques professionnelles réelles. En fait, trop souvent, les indicateurs permettent de mesurer les progrès des méthodes d’IA, mais peinent à mesurer leurs impacts ou l’adoption, c’est-à-dire l’intensité de son utilisation. Kapoor et Narayanan insistent : les impacts économiques de l’IA seront progressifs plus que exponentiels. Si le taux de publication d’articles sur l’IA affiche un doublement en moins de deux ans, on ne sait pas comment cette augmentation de volume se traduit en progrès. En fait, il est probable que cette surproduction même limite l’innovation. Une étude a ainsi montré que dans les domaines de recherche où le volume d’articles scientifiques est plus élevé, il est plus difficile aux nouvelles idées de percer.
L’IA va rester sous contrôle
Le recours aux concepts flous d’« intelligence » ou de « superintelligence » ont obscurci notre capacité à raisonner clairement sur un monde doté d’une IA avancée. Assez souvent, l’intelligence elle-même est assez mal définie, selon un spectre qui irait de la souris à l’IA, en passant par le singe et l’humain. Mais surtout, “l’intelligence n’est pas la propriété en jeu pour analyser les impacts de l’IA. C’est plutôt le pouvoir – la capacité à modifier son environnement – qui est en jeu”.Nous ne sommes pas devenus puissants du fait de notre intelligence, mais du fait de la technologie que nous avons utilisé pour accroître nos capacités. La différence entre l’IA et les capacités humaines reposent surtout dans la vitesse. Les machines nous dépassent surtout en terme de vitesse, d’où le fait que nous les ayons développé surtout dans les domaines où la vitesse est en jeu.
“Nous prévoyons que l’IA ne sera pas en mesure de surpasser significativement les humains entraînés (en particulier les équipes humaines, et surtout si elle est complétée par des outils automatisés simples) dans la prévision d’événements géopolitiques (par exemple, les élections). Nous faisons la même prédiction pour les tâches consistant à persuader les gens d’agir contre leur propre intérêt”. En fait, les systèmes d’IA ne seront pas significativement plus performants que les humains agissant avec l’aide de l’IA, prédisent les deux chercheurs.
Mais surtout, insistent-ils, rien ne permet d’affirmer que nous perdions demain la main sur l’IA. D’abord parce que le contrôle reste fort, des audits à la surveillance des systèmes en passant par la sécurité intégrée. “En cybersécurité, le principe du « moindre privilège » garantit que les acteurs n’ont accès qu’aux ressources minimales nécessaires à leurs tâches. Les contrôles d’accès empêchent les personnes travaillant avec des données et des systèmes sensibles d’accéder à des informations et outils confidentiels non nécessaires à leur travail. Nous pouvons concevoir des protections similaires pour les systèmes d’IA dans des contextes conséquents. Les méthodes de vérification formelle garantissent que les codes critiques pour la sécurité fonctionnent conformément à leurs spécifications ; elles sont désormais utilisées pour vérifier l’exactitude du code généré par l’IA.” Nous pouvons également emprunter des idées comme la conception de systèmes rendant les actions de changement d’état réversibles, permettant ainsi aux humains de conserver un contrôle significatif, même dans des systèmes hautement automatisés. On peut également imaginer de nouvelles idées pour assurer la sécurité, comme le développement de systèmes qui apprennent à transmettre les décisions aux opérateurs humains en fonction de l’incertitude ou du niveau de risque, ou encore la conception de systèmes agents dont l’activité est visible et lisible par les humains, ou encore la création de structures de contrôle hiérarchiques dans lesquelles des systèmes d’IA plus simples et plus fiables supervisent des systèmes plus performants, mais potentiellement peu fiables. Pour les deux chercheurs, “avec le développement et l’adoption de l’IA avancée, l’innovation se multipliera pour trouver de nouveaux modèles de contrôle humain”.
Pour eux d’ailleurs, à l’avenir, un nombre croissant d’emplois et de tâches humaines seront affectés au contrôle de l’IA. Lors des phases d’automatisation précédentes, d’innombrables méthodes de contrôle et de surveillance des machines ont été inventées. Et aujourd’hui, les chauffeurs routiers par exemple, ne cessent de contrôler et surveiller les machines qui les surveillent, comme l’expliquait Karen Levy. Pour les chercheurs, le risque de perdre de la lisibilité et du contrôle en favorisant l’efficacité et l’automatisation doit toujours être contrebalancée. Les IA mal contrôlées risquent surtout d’introduire trop d’erreurs pour rester rentables. Dans les faits, on constate plutôt que les systèmes trop autonomes et insuffisamment supervisés sont vite débranchés. Nul n’a avantage à se passer du contrôle humain. C’est ce que montre d’ailleurs la question de la gestion des risques, expliquent les deux chercheurs en listant plusieurs types de risques.
La course aux armements par exemple, consistant à déployer une IA de plus en plus puissante sans supervision ni contrôle adéquats sous prétexte de concurrence, et que les acteurs les plus sûrs soient supplantés par des acteurs prenant plus de risques, est souvent vite remisée par la régulation. “De nombreuses stratégies réglementaires sont mobilisables, que ce soient celles axées sur les processus (normes, audits et inspections), les résultats (responsabilité) ou la correction de l’asymétrie d’information (étiquetage et certification).” En fait, rappellent les chercheurs, le succès commercial est plutôt lié à la sécurité qu’autre chose. Dans le domaine des voitures autonomes comme dans celui de l’aéronautique, “l’intégration de l’IA a été limitée aux normes de sécurité existantes, au lieu qu’elles soient abaissées pour encourager son adoption, principalement en raison de la capacité des régulateurs à sanctionner les entreprises qui ne respectent pas les normes de sécurité”. Dans le secteur automobile, pourtant, pendant longtemps, la sécurité n’était pas considérée comme relevant de la responsabilité des constructeurs. mais petit à petit, les normes et les attentes en matière de sécurité se sont renforcées. Dans le domaine des recommandations algorithmiques des médias sociaux par contre, les préjudices sont plus difficiles à mesurer, ce qui explique qu’il soit plus difficile d’imputer les défaillances aux systèmes de recommandation. “L’arbitrage entre innovation et réglementation est un dilemme récurrent pour l’État régulateur”. En fait, la plupart des secteurs à haut risque sont fortement réglementés, rappellent les deux chercheurs. Et contrairement à l’idée répandue, il n’y a pas que l’Europe qui régule, les Etats-Unis et la Chine aussi ! Quant à la course aux armements, elle se concentre surtout sur l’invention des modèles, pas sur l’adoption ou la diffusion qui demeurent bien plus déterminantes pourtant.
Répondre aux abus. Jusqu’à présent, les principales défenses contre les abus se situent post-formation, alors qu’elles devraient surtout se situer en aval des modèles, estiment les chercheurs. Le problème fondamental est que la nocivité d’un modèle dépend du contexte, contexte souvent absent du modèle, comme ils l’expliquaient en montrant que la sécurité n’est pas une propriété du modèle. Le modèle chargé de rédiger un e-mail persuasif pour le phishing par exemple n’a aucun moyen de savoir s’il est utilisé à des fins marketing ou d’hameçonnage ; les interventions au niveau du modèle seraient donc inefficaces. Ainsi, les défenses les plus efficaces contre le phishing ne sont pas les restrictions sur la composition des e-mails (qui compromettraient les utilisations légitimes), mais plutôt les systèmes d’analyse et de filtrage des e-mails qui détectent les schémas suspects, et les protections au niveau du navigateur. Se défendre contre les cybermenaces liées à l’IA nécessite de renforcer les programmes de détection des vulnérabilités existants plutôt que de tenter de restreindre les capacités de l’IA à la source. Mais surtout, “plutôt que de considérer les capacités de l’IA uniquement comme une source de risque, il convient de reconnaître leur potentiel défensif. En cybersécurité, l’IA renforce déjà les capacités défensives grâce à la détection automatisée des vulnérabilités, à l’analyse des menaces et à la surveillance des surfaces d’attaque”. “Donner aux défenseurs l’accès à des outils d’IA puissants améliore souvent l’équilibre attaque-défense en leur faveur”. En modération de contenu, par exemple, on pourrait mieux mobiliser l’IA peut aider à identifier les opérations d’influence coordonnées. Nous devons investir dans des applications défensives plutôt que de tenter de restreindre la technologie elle-même, suggèrent les chercheurs.
Le désalignement. Une IA mal alignée agit contre l’intention de son développeur ou de son utilisateur. Mais là encore, la principale défense contre le désalignement se situe en aval plutôt qu’en amont, dans les applications plutôt que dans les modèles. Le désalignement catastrophique est le plus spéculatif des risques, rappellent les chercheurs. “La crainte que les systèmes d’IA puissent interpréter les commandes de manière catastrophique repose souvent sur des hypothèses douteuses quant au déploiement de la technologie dans le monde réel”.Dans le monde réel, la surveillance et le contrôle sont très présents et l’IA est très utile pour renforcer cette surveillance et ce contrôle. Les craintes liées au désalignement de l’IA supposent que ces systèmes déjouent la surveillance, alors que nous avons développés de très nombreuses formes de contrôle, qui sont souvent d’autant plus fortes et redondantes que les décisions sont importantes.
Les risques systémiques. Si les risques existentiels sont peu probables, les risques systémiques, eux, sont très courants. Parmi ceux-ci figurent “l’enracinement des préjugés et de la discrimination, les pertes d’emplois massives dans certaines professions, la dégradation des conditions de travail, l’accroissement des inégalités, la concentration du pouvoir, l’érosion de la confiance sociale, la pollution de l’écosystème de l’information, le déclin de la liberté de la presse, le recul démocratique, la surveillance de masse et l’autoritarisme”. “Si l’IA est une technologie normale, ces risques deviennent bien plus importants que les risques catastrophiques évoqués précédemment”. Car ces risques découlent de l’utilisation de l’IA par des personnes et des organisations pour promouvoir leurs propres intérêts, l’IA ne faisant qu’amplifier les instabilités existantes dans notre société. Nous devrions bien plus nous soucier des risques cumulatifs que des risques décisifs.
Politiques de l’IA
Narayanan et Kapoor concluent leur article en invitant à réorienter la régulation de l’IA, notamment en favorisant la résilience. Pour l’instant, l’élaboration des politiques publiques et des réglementations de l’IA est caractérisée par de profondes divergences et de fortes incertitudes, notamment sur la nature des risques que fait peser l’IA sur la société. Si les probabilités de risque existentiel de l’IA sont trop peu fiables pour éclairer les politiques, il n’empêche que nombre d’acteurs poussent à une régulation adaptée à ces risques existentiels. Alors que d’autres interventions, comme l’amélioration de la transparence, sont inconditionnellement utiles pour atténuer les risques, quels qu’ils soient. Se défendre contre la superintelligence exige que l’humanité s’unisse contre un ennemi commun, pour ainsi dire, concentrant le pouvoir et exerçant un contrôle centralisé sur l’IA, qui risque d’être un remède pire que le mal. Or, nous devrions bien plus nous préoccuper des risques cumulatifs et des pratiques capitalistes extractives que l’IA amplifie et qui amplifient les inégalités. Pour nous défendre contre ces risques-ci, pour empêcher la concentration du pouvoir et des ressources, il nous faut rendre l’IA puissante plus largement accessible, défendent les deux chercheurs.
Ils recommandent d’ailleurs plusieurs politiques. D’abord, améliorer le financement stratégique sur les risques. Nous devons obtenir de meilleures connaissances sur la façon dont les acteurs malveillants utilisent l’IA et améliorer nos connaissances sur les risques et leur atténuation. Ils proposent également d’améliorer la surveillance des usages, des risques et des échecs, passant par les déclarations de transparences, les registres et inventaires, les enregistrements de produits, les registres d’incidents (comme la base de données d’incidents de l’IA) ou la protection des lanceurs d’alerte… Enfin, il proposent que les “données probantes” soient un objectif prioritaire, c’est-à-dire d’améliorer l’accès de la recherche.
Dans le domaine de l’IA, la difficulté consiste à évaluer les risques avant le déploiement. Pour améliorer la résilience, il est important d’améliorer la responsabilité et la résilience, plus que l’analyse de risque, c’est-à-dire des démarches de contrôle qui ont lieu après les déploiements. “La résilience exige à la fois de minimiser la gravité des dommages lorsqu’ils surviennent et la probabilité qu’ils surviennent.” Pour atténuer les effets de l’IA nous devons donc nous doter de politiques qui vont renforcer la démocratie, la liberté de la presse ou l’équité dans le monde du travail. C’est-à-dire d’améliorer la résilience sociétale au sens large.
Pour élaborer des politiques technologiques efficaces, il faut ensuite renforcer les capacités techniques et institutionnelles de la recherche, des autorités et administrations. Sans personnels compétents et informés, la régulation de l’IA sera toujours difficile. Les chercheurs invitent même à “diversifier l’ensemble des régulateurs et, idéalement, à introduire la concurrence entre eux plutôt que de confier la responsabilité de l’ensemble à un seul régulateur”.
Par contre, Kapoor et Narayanan se défient fortement des politiques visant à promouvoir une non-prolifération de l’IA, c’est-à-dire à limiter le nombre d’acteurs pouvant développer des IA performantes. Les contrôles à l’exportation de matériel ou de logiciels visant à limiter la capacité des pays à construire, acquérir ou exploiter une IA performante, l’exigence de licences pour construire ou distribuer une IA performante, et l’interdiction des modèles d’IA à pondération ouverte… sont des politiques qui favorisent la concentration plus qu’elles ne réduisent les risques. “Lorsque de nombreuses applications en aval s’appuient sur le même modèle, les vulnérabilités de ce modèle peuvent être exploitées dans toutes les applications”, rappellent-ils.
Pour les deux chercheurs, nous devons “réaliser les avantages de l’IA”, c’est-à-dire accélérer l’adoption des bénéfices de l’IA et atténuer ses inconvénients. Pour cela, estiment-ils, nous devons être plus souples sur nos modalités d’intervention. Par exemple, ils estiment que pour l’instant catégoriser certains domaines de déploiement de l’IA comme à haut risque est problématique, au prétexte que dans ces secteurs (assurance, prestation sociale ou recrutement…), les technologies peuvent aller de la reconnaissance optique de caractères, relativement inoffensives, à la prise de décision automatisées dont les conséquences sont importantes. Pour eux, il faudrait seulement considérer la prise de décision automatisée dans ces secteurs comme à haut risque.
Un autre enjeu repose sur l’essor des modèles fondamentaux qui a conduit à une distinction beaucoup plus nette entre les développeurs de modèles, les développeurs en aval et les déployeurs (parmi de nombreuses autres catégories). Une réglementation insensible à ces distinctions risque de conférer aux développeurs de modèles des responsabilités en matière d’atténuation des risques liés à des contextes de déploiement particuliers, ce qui leur serait impossible en raison de la nature polyvalente des modèles fondamentaux et de l’imprévisibilité de tous les contextes de déploiement possibles.
Enfin, lorsque la réglementation établit une distinction binaire entre les décisions entièrement automatisées et celles qui ne le sont pas, et ne reconnaît pas les degrés de surveillance, elle décourage l’adoption de nouveaux modèles de contrôle de l’IA. Or de nombreux nouveaux modèles sont proposés pour garantir une supervision humaine efficace sans impliquer un humain dans chaque décision. Il serait imprudent de définir la prise de décision automatisée de telle sorte que ces approches engendrent les mêmes contraintes de conformité qu’un système sans supervision. Pour les deux chercheurs, “opposer réglementation et diffusion est un faux compromis, tout comme opposer réglementation et innovation”, comme le disait Anu Bradford. Pour autant, soulignent les chercheurs, l’enjeu n’est pas de ne pas réguler, mais bien de garantir de la souplesse. La législation garantissant la validité juridique des signatures et enregistrement électroniques promulguée en 2000 aux Etats-Unis a joué un rôle déterminant dans la promotion du commerce électronique et sa diffusion. La législation sur les petits drones mise en place par la Federal Aviation Administration en 2016 a permis le développement du secteur par la création de pilotes certifiés. Nous devons trouver pour l’IA également des réglementations qui favorisent sa diffusion, estiment-ils. Par exemple, en facilitant “la redistribution des bénéfices de l’IA afin de les rendre plus équitables et d’indemniser les personnes qui risquent de subir les conséquences de l’automatisation. Le renforcement des filets de sécurité sociale contribuera à atténuer l’inquiétude actuelle du public face à l’IA dans de nombreux pays”. Et les chercheurs de suggérer par exemple de taxer les entreprises d’IA pour soutenir les industries culturelles et le journalisme, mis à mal par l’IA. En ce qui concerne l’adoption par les services publics de l’IA, les gouvernements doivent trouver le juste équilibre entre une adoption trop précipitée qui génère des défaillances et de la méfiance, et une adoption trop lente qui risque de produire de l’externalisation par le secteur privé.
Les chercheurs Arvind Narayanan et Sayash Kapoor – dont nous avions chroniqué le livre, AI Snake Oil – signent pour le Knight un long article pour démonter les risques existentiels de l’IA générale. Pour eux, l’IA est une « technologie normale ». Cela ne signifie pas que son impact ne sera pas profond, comme l’électricité ou internet, mais cela signifie qu’ils considèrent « l’IA comme un outil dont nous pouvons et devons garder le contrôle, et nous soutenons que cet objectif ne nécessite ni inte
Les chercheurs Arvind Narayanan et Sayash Kapoor – dont nous avions chroniqué le livre, AI Snake Oil – signent pour le Knight un long article pour démonter les risques existentiels de l’IA générale. Pour eux, l’IA est une « technologie normale ». Cela ne signifie pas que son impact ne sera pas profond, comme l’électricité ou internet, mais cela signifie qu’ils considèrent « l’IA comme un outil dont nous pouvons et devons garder le contrôle, et nous soutenons que cet objectif ne nécessite ni interventions politiques drastiques ni avancées technologiques ». L’IA n’est pas appelée à déterminer elle-même son avenir, expliquent-ils. Les deux chercheurs estiment que « les impacts économiques et sociétaux transformateurs seront lents (de l’ordre de plusieurs décennies) ».
Selon eux, dans les années à venir « une part croissante du travail des individus va consister à contrôler l’IA ». Mais surtout, considérer l’IA comme une technologie courante conduit à des conclusions fondamentalement différentes sur les mesures d’atténuation que nous devons y apporter, et nous invite, notamment, à minimiser le danger d’une superintelligence autonome qui viendrait dévorer l’humanité.
La vitesse du progrès est plus linéaire qu’on le pense
« Comme pour d’autres technologies à usage général, l’impact de l’IA se matérialise non pas lorsque les méthodes et les capacités s’améliorent, mais lorsque ces améliorations se traduisent en applications et se diffusent dans les secteurs productifs de l’économie« , rappellent les chercheurs, à la suite des travaux de Jeffrey Ding dans son livre, Technology and the Rise of Great Powers: How Diffusion Shapes Economic Competition (Princeton University Press, 2024, non traduit). Ding y rappelle que la diffusion d’une innovation compte plus que son invention, c’est-à-dire que l’élargissement des applications à d’innombrables secteurs est souvent lent mais décisif. Pour Foreign Affairs, Ding pointait d’ailleurs que l’enjeu des politiques publiques en matière d’IA ne devraient pas être de s’assurer de sa domination sur le cycle d’innovation, mais du rythme d’intégration de l’IA dans un large éventail de processus productifs. L’enjeu tient bien plus à élargir les champs d’application des innovations qu’à maîtriser la course à la puissance, telle qu’elle s’observe actuellement.
En fait, rappellent Narayanan et Kapoor, les déploiements de l’IA seront, comme dans toutes les autres technologies avant elle, progressifs, permettant aux individus comme aux institutions de s’adapter. Par exemple, constatent-ils, la diffusion de l’IA dans les domaines critiques pour la sécurité est lente. Même dans le domaine de « l’optimisation prédictive », c’est-à-dire la prédiction des risques pour prendre des décisions sur les individus, qui se sont multipliées ces dernières années, l’IA n’est pas très présente, comme l’avaient pointé les chercheurs dans une étude. Ce secteur mobilise surtout des techniques statistiques classiques, rappellent-ils. En fait, la complexité et l’opacité de l’IA font qu’elle est peu adaptée pour ces enjeux. Les risques de sécurité et de défaillance font que son usage y produit souvent de piètres résultats. Sans compter que la réglementation impose déjà des procédures qui ralentissent les déploiements, que ce soit la supervision des dispositifs médicaux ou l’IA Act européen. D’ailleurs, “lorsque de nouveaux domaines où l’IA peut être utilisée de manière significative apparaissent, nous pouvons et devons les réglementer ».
Même en dehors des domaines critiques pour la sécurité, l’adoption de l’IA est plus lente que ce que l’on pourrait croire. Pourtant, de nombreuses études estiment que l’usage de l’IA générative est déjà très fort. Une étude très commentée constatait qu’en août 2024, 40 % des adultes américains utilisaient déjà l’IA générative. Mais cette percée d’utilisation ne signifie pas pour autant une utilisation intensive, rappellent Narayanan et Kapoor – sur son blog, Gregory Chatonksy ne disait pas autre chose, distinguant une approche consumériste d’une approche productive, la seconde était bien moins maîtrisée que la première. L’adoption est une question d’utilisation du logiciel, et non de disponibilité, rappellent les chercheurs. Si les outils sont désormais accessibles immédiatement, leur intégration à des flux de travail ou à des habitudes, elle, prend du temps. Entre utiliser et intégrer, il y a une différence que le nombre d’utilisateurs d’une application ne suffit pas à distinguer. L’analyse de l’électrification par exemple montre que les gains de productivité ont mis des décennies à se matérialiser pleinement, comme l’expliquait Tim Harford. Ce qui a finalement permis de réaliser des gains de productivité, c’est surtout la refonte complète de l’agencement des usines autour de la logique des chaînes de production électrifiées.
Les deux chercheurs estiment enfin que nous sommes confrontés à des limites à la vitesse d’innovation avec l’IA. Les voitures autonomes par exemple ont mis deux décennies à se développer, du fait des contraintes de sécurité nécessaires, qui, fort heureusement, les entravent encore. Certes, les choses peuvent aller plus vite dans des domaines non critiques, comme le jeu. Mais très souvent, “l’écart entre la capacité et la fiabilité” reste fort. La perspective d’agents IA pour la réservation de voyages ou le service clients est moins à risque que la conduite autonome, mais cet apprentissage n’est pas simple à réaliser pour autant. Rien n’assure qu’il devienne rapidement suffisamment fiable pour être déployé. Même dans le domaine de la recommandation sur les réseaux sociaux, le fait qu’elle s’appuie sur des modèles d’apprentissage automatique n’a pas supprimé la nécessité de coder les algorithmes de recommandation. Et dans nombre de domaines, la vitesse d’acquisition des connaissances pour déployer de l’IA est fortement limitée en raison des coûts sociaux de l’expérimentation. Enfin, les chercheurs soulignent que si l’IA sait coder ou répondre à des examens, comme à ceux du barreau, mieux que des humains, cela ne recouvre pas tous les enjeux des pratiques professionnelles réelles. En fait, trop souvent, les indicateurs permettent de mesurer les progrès des méthodes d’IA, mais peinent à mesurer leurs impacts ou l’adoption, c’est-à-dire l’intensité de son utilisation. Kapoor et Narayanan insistent : les impacts économiques de l’IA seront progressifs plus que exponentiels. Si le taux de publication d’articles sur l’IA affiche un doublement en moins de deux ans, on ne sait pas comment cette augmentation de volume se traduit en progrès. En fait, il est probable que cette surproduction même limite l’innovation. Une étude a ainsi montré que dans les domaines de recherche où le volume d’articles scientifiques est plus élevé, il est plus difficile aux nouvelles idées de percer.
L’IA va rester sous contrôle
Le recours aux concepts flous d’« intelligence » ou de « superintelligence » ont obscurci notre capacité à raisonner clairement sur un monde doté d’une IA avancée. Assez souvent, l’intelligence elle-même est assez mal définie, selon un spectre qui irait de la souris à l’IA, en passant par le singe et l’humain. Mais surtout, “l’intelligence n’est pas la propriété en jeu pour analyser les impacts de l’IA. C’est plutôt le pouvoir – la capacité à modifier son environnement – qui est en jeu”.Nous ne sommes pas devenus puissants du fait de notre intelligence, mais du fait de la technologie que nous avons utilisé pour accroître nos capacités. La différence entre l’IA et les capacités humaines reposent surtout dans la vitesse. Les machines nous dépassent surtout en terme de vitesse, d’où le fait que nous les ayons développé surtout dans les domaines où la vitesse est en jeu.
“Nous prévoyons que l’IA ne sera pas en mesure de surpasser significativement les humains entraînés (en particulier les équipes humaines, et surtout si elle est complétée par des outils automatisés simples) dans la prévision d’événements géopolitiques (par exemple, les élections). Nous faisons la même prédiction pour les tâches consistant à persuader les gens d’agir contre leur propre intérêt”. En fait, les systèmes d’IA ne seront pas significativement plus performants que les humains agissant avec l’aide de l’IA, prédisent les deux chercheurs.
Mais surtout, insistent-ils, rien ne permet d’affirmer que nous perdions demain la main sur l’IA. D’abord parce que le contrôle reste fort, des audits à la surveillance des systèmes en passant par la sécurité intégrée. “En cybersécurité, le principe du « moindre privilège » garantit que les acteurs n’ont accès qu’aux ressources minimales nécessaires à leurs tâches. Les contrôles d’accès empêchent les personnes travaillant avec des données et des systèmes sensibles d’accéder à des informations et outils confidentiels non nécessaires à leur travail. Nous pouvons concevoir des protections similaires pour les systèmes d’IA dans des contextes conséquents. Les méthodes de vérification formelle garantissent que les codes critiques pour la sécurité fonctionnent conformément à leurs spécifications ; elles sont désormais utilisées pour vérifier l’exactitude du code généré par l’IA.” Nous pouvons également emprunter des idées comme la conception de systèmes rendant les actions de changement d’état réversibles, permettant ainsi aux humains de conserver un contrôle significatif, même dans des systèmes hautement automatisés. On peut également imaginer de nouvelles idées pour assurer la sécurité, comme le développement de systèmes qui apprennent à transmettre les décisions aux opérateurs humains en fonction de l’incertitude ou du niveau de risque, ou encore la conception de systèmes agents dont l’activité est visible et lisible par les humains, ou encore la création de structures de contrôle hiérarchiques dans lesquelles des systèmes d’IA plus simples et plus fiables supervisent des systèmes plus performants, mais potentiellement peu fiables. Pour les deux chercheurs, “avec le développement et l’adoption de l’IA avancée, l’innovation se multipliera pour trouver de nouveaux modèles de contrôle humain”.
Pour eux d’ailleurs, à l’avenir, un nombre croissant d’emplois et de tâches humaines seront affectés au contrôle de l’IA. Lors des phases d’automatisation précédentes, d’innombrables méthodes de contrôle et de surveillance des machines ont été inventées. Et aujourd’hui, les chauffeurs routiers par exemple, ne cessent de contrôler et surveiller les machines qui les surveillent, comme l’expliquait Karen Levy. Pour les chercheurs, le risque de perdre de la lisibilité et du contrôle en favorisant l’efficacité et l’automatisation doit toujours être contrebalancée. Les IA mal contrôlées risquent surtout d’introduire trop d’erreurs pour rester rentables. Dans les faits, on constate plutôt que les systèmes trop autonomes et insuffisamment supervisés sont vite débranchés. Nul n’a avantage à se passer du contrôle humain. C’est ce que montre d’ailleurs la question de la gestion des risques, expliquent les deux chercheurs en listant plusieurs types de risques.
La course aux armements par exemple, consistant à déployer une IA de plus en plus puissante sans supervision ni contrôle adéquats sous prétexte de concurrence, et que les acteurs les plus sûrs soient supplantés par des acteurs prenant plus de risques, est souvent vite remisée par la régulation. “De nombreuses stratégies réglementaires sont mobilisables, que ce soient celles axées sur les processus (normes, audits et inspections), les résultats (responsabilité) ou la correction de l’asymétrie d’information (étiquetage et certification).” En fait, rappellent les chercheurs, le succès commercial est plutôt lié à la sécurité qu’autre chose. Dans le domaine des voitures autonomes comme dans celui de l’aéronautique, “l’intégration de l’IA a été limitée aux normes de sécurité existantes, au lieu qu’elles soient abaissées pour encourager son adoption, principalement en raison de la capacité des régulateurs à sanctionner les entreprises qui ne respectent pas les normes de sécurité”. Dans le secteur automobile, pourtant, pendant longtemps, la sécurité n’était pas considérée comme relevant de la responsabilité des constructeurs. mais petit à petit, les normes et les attentes en matière de sécurité se sont renforcées. Dans le domaine des recommandations algorithmiques des médias sociaux par contre, les préjudices sont plus difficiles à mesurer, ce qui explique qu’il soit plus difficile d’imputer les défaillances aux systèmes de recommandation. “L’arbitrage entre innovation et réglementation est un dilemme récurrent pour l’État régulateur”. En fait, la plupart des secteurs à haut risque sont fortement réglementés, rappellent les deux chercheurs. Et contrairement à l’idée répandue, il n’y a pas que l’Europe qui régule, les Etats-Unis et la Chine aussi ! Quant à la course aux armements, elle se concentre surtout sur l’invention des modèles, pas sur l’adoption ou la diffusion qui demeurent bien plus déterminantes pourtant.
Répondre aux abus. Jusqu’à présent, les principales défenses contre les abus se situent post-formation, alors qu’elles devraient surtout se situer en aval des modèles, estiment les chercheurs. Le problème fondamental est que la nocivité d’un modèle dépend du contexte, contexte souvent absent du modèle, comme ils l’expliquaient en montrant que la sécurité n’est pas une propriété du modèle. Le modèle chargé de rédiger un e-mail persuasif pour le phishing par exemple n’a aucun moyen de savoir s’il est utilisé à des fins marketing ou d’hameçonnage ; les interventions au niveau du modèle seraient donc inefficaces. Ainsi, les défenses les plus efficaces contre le phishing ne sont pas les restrictions sur la composition des e-mails (qui compromettraient les utilisations légitimes), mais plutôt les systèmes d’analyse et de filtrage des e-mails qui détectent les schémas suspects, et les protections au niveau du navigateur. Se défendre contre les cybermenaces liées à l’IA nécessite de renforcer les programmes de détection des vulnérabilités existants plutôt que de tenter de restreindre les capacités de l’IA à la source. Mais surtout, “plutôt que de considérer les capacités de l’IA uniquement comme une source de risque, il convient de reconnaître leur potentiel défensif. En cybersécurité, l’IA renforce déjà les capacités défensives grâce à la détection automatisée des vulnérabilités, à l’analyse des menaces et à la surveillance des surfaces d’attaque”. “Donner aux défenseurs l’accès à des outils d’IA puissants améliore souvent l’équilibre attaque-défense en leur faveur”. En modération de contenu, par exemple, on pourrait mieux mobiliser l’IA peut aider à identifier les opérations d’influence coordonnées. Nous devons investir dans des applications défensives plutôt que de tenter de restreindre la technologie elle-même, suggèrent les chercheurs.
Le désalignement. Une IA mal alignée agit contre l’intention de son développeur ou de son utilisateur. Mais là encore, la principale défense contre le désalignement se situe en aval plutôt qu’en amont, dans les applications plutôt que dans les modèles. Le désalignement catastrophique est le plus spéculatif des risques, rappellent les chercheurs. “La crainte que les systèmes d’IA puissent interpréter les commandes de manière catastrophique repose souvent sur des hypothèses douteuses quant au déploiement de la technologie dans le monde réel”.Dans le monde réel, la surveillance et le contrôle sont très présents et l’IA est très utile pour renforcer cette surveillance et ce contrôle. Les craintes liées au désalignement de l’IA supposent que ces systèmes déjouent la surveillance, alors que nous avons développés de très nombreuses formes de contrôle, qui sont souvent d’autant plus fortes et redondantes que les décisions sont importantes.
Les risques systémiques. Si les risques existentiels sont peu probables, les risques systémiques, eux, sont très courants. Parmi ceux-ci figurent “l’enracinement des préjugés et de la discrimination, les pertes d’emplois massives dans certaines professions, la dégradation des conditions de travail, l’accroissement des inégalités, la concentration du pouvoir, l’érosion de la confiance sociale, la pollution de l’écosystème de l’information, le déclin de la liberté de la presse, le recul démocratique, la surveillance de masse et l’autoritarisme”. “Si l’IA est une technologie normale, ces risques deviennent bien plus importants que les risques catastrophiques évoqués précédemment”. Car ces risques découlent de l’utilisation de l’IA par des personnes et des organisations pour promouvoir leurs propres intérêts, l’IA ne faisant qu’amplifier les instabilités existantes dans notre société. Nous devrions bien plus nous soucier des risques cumulatifs que des risques décisifs.
Politiques de l’IA
Narayanan et Kapoor concluent leur article en invitant à réorienter la régulation de l’IA, notamment en favorisant la résilience. Pour l’instant, l’élaboration des politiques publiques et des réglementations de l’IA est caractérisée par de profondes divergences et de fortes incertitudes, notamment sur la nature des risques que fait peser l’IA sur la société. Si les probabilités de risque existentiel de l’IA sont trop peu fiables pour éclairer les politiques, il n’empêche que nombre d’acteurs poussent à une régulation adaptée à ces risques existentiels. Alors que d’autres interventions, comme l’amélioration de la transparence, sont inconditionnellement utiles pour atténuer les risques, quels qu’ils soient. Se défendre contre la superintelligence exige que l’humanité s’unisse contre un ennemi commun, pour ainsi dire, concentrant le pouvoir et exerçant un contrôle centralisé sur l’IA, qui risque d’être un remède pire que le mal. Or, nous devrions bien plus nous préoccuper des risques cumulatifs et des pratiques capitalistes extractives que l’IA amplifie et qui amplifient les inégalités. Pour nous défendre contre ces risques-ci, pour empêcher la concentration du pouvoir et des ressources, il nous faut rendre l’IA puissante plus largement accessible, défendent les deux chercheurs.
Ils recommandent d’ailleurs plusieurs politiques. D’abord, améliorer le financement stratégique sur les risques. Nous devons obtenir de meilleures connaissances sur la façon dont les acteurs malveillants utilisent l’IA et améliorer nos connaissances sur les risques et leur atténuation. Ils proposent également d’améliorer la surveillance des usages, des risques et des échecs, passant par les déclarations de transparences, les registres et inventaires, les enregistrements de produits, les registres d’incidents (comme la base de données d’incidents de l’IA) ou la protection des lanceurs d’alerte… Enfin, il proposent que les “données probantes” soient un objectif prioritaire, c’est-à-dire d’améliorer l’accès de la recherche.
Dans le domaine de l’IA, la difficulté consiste à évaluer les risques avant le déploiement. Pour améliorer la résilience, il est important d’améliorer la responsabilité et la résilience, plus que l’analyse de risque, c’est-à-dire des démarches de contrôle qui ont lieu après les déploiements. “La résilience exige à la fois de minimiser la gravité des dommages lorsqu’ils surviennent et la probabilité qu’ils surviennent.” Pour atténuer les effets de l’IA nous devons donc nous doter de politiques qui vont renforcer la démocratie, la liberté de la presse ou l’équité dans le monde du travail. C’est-à-dire d’améliorer la résilience sociétale au sens large.
Pour élaborer des politiques technologiques efficaces, il faut ensuite renforcer les capacités techniques et institutionnelles de la recherche, des autorités et administrations. Sans personnels compétents et informés, la régulation de l’IA sera toujours difficile. Les chercheurs invitent même à “diversifier l’ensemble des régulateurs et, idéalement, à introduire la concurrence entre eux plutôt que de confier la responsabilité de l’ensemble à un seul régulateur”.
Par contre, Kapoor et Narayanan se défient fortement des politiques visant à promouvoir une non-prolifération de l’IA, c’est-à-dire à limiter le nombre d’acteurs pouvant développer des IA performantes. Les contrôles à l’exportation de matériel ou de logiciels visant à limiter la capacité des pays à construire, acquérir ou exploiter une IA performante, l’exigence de licences pour construire ou distribuer une IA performante, et l’interdiction des modèles d’IA à pondération ouverte… sont des politiques qui favorisent la concentration plus qu’elles ne réduisent les risques. “Lorsque de nombreuses applications en aval s’appuient sur le même modèle, les vulnérabilités de ce modèle peuvent être exploitées dans toutes les applications”, rappellent-ils.
Pour les deux chercheurs, nous devons “réaliser les avantages de l’IA”, c’est-à-dire accélérer l’adoption des bénéfices de l’IA et atténuer ses inconvénients. Pour cela, estiment-ils, nous devons être plus souples sur nos modalités d’intervention. Par exemple, ils estiment que pour l’instant catégoriser certains domaines de déploiement de l’IA comme à haut risque est problématique, au prétexte que dans ces secteurs (assurance, prestation sociale ou recrutement…), les technologies peuvent aller de la reconnaissance optique de caractères, relativement inoffensives, à la prise de décision automatisées dont les conséquences sont importantes. Pour eux, il faudrait seulement considérer la prise de décision automatisée dans ces secteurs comme à haut risque.
Un autre enjeu repose sur l’essor des modèles fondamentaux qui a conduit à une distinction beaucoup plus nette entre les développeurs de modèles, les développeurs en aval et les déployeurs (parmi de nombreuses autres catégories). Une réglementation insensible à ces distinctions risque de conférer aux développeurs de modèles des responsabilités en matière d’atténuation des risques liés à des contextes de déploiement particuliers, ce qui leur serait impossible en raison de la nature polyvalente des modèles fondamentaux et de l’imprévisibilité de tous les contextes de déploiement possibles.
Enfin, lorsque la réglementation établit une distinction binaire entre les décisions entièrement automatisées et celles qui ne le sont pas, et ne reconnaît pas les degrés de surveillance, elle décourage l’adoption de nouveaux modèles de contrôle de l’IA. Or de nombreux nouveaux modèles sont proposés pour garantir une supervision humaine efficace sans impliquer un humain dans chaque décision. Il serait imprudent de définir la prise de décision automatisée de telle sorte que ces approches engendrent les mêmes contraintes de conformité qu’un système sans supervision. Pour les deux chercheurs, “opposer réglementation et diffusion est un faux compromis, tout comme opposer réglementation et innovation”, comme le disait Anu Bradford. Pour autant, soulignent les chercheurs, l’enjeu n’est pas de ne pas réguler, mais bien de garantir de la souplesse. La législation garantissant la validité juridique des signatures et enregistrement électroniques promulguée en 2000 aux Etats-Unis a joué un rôle déterminant dans la promotion du commerce électronique et sa diffusion. La législation sur les petits drones mise en place par la Federal Aviation Administration en 2016 a permis le développement du secteur par la création de pilotes certifiés. Nous devons trouver pour l’IA également des réglementations qui favorisent sa diffusion, estiment-ils. Par exemple, en facilitant “la redistribution des bénéfices de l’IA afin de les rendre plus équitables et d’indemniser les personnes qui risquent de subir les conséquences de l’automatisation. Le renforcement des filets de sécurité sociale contribuera à atténuer l’inquiétude actuelle du public face à l’IA dans de nombreux pays”. Et les chercheurs de suggérer par exemple de taxer les entreprises d’IA pour soutenir les industries culturelles et le journalisme, mis à mal par l’IA. En ce qui concerne l’adoption par les services publics de l’IA, les gouvernements doivent trouver le juste équilibre entre une adoption trop précipitée qui génère des défaillances et de la méfiance, et une adoption trop lente qui risque de produire de l’externalisation par le secteur privé.
L’avant dernier numéro de la revue Réseaux est consacré à la dématérialisation. “La numérisation des administrations redéfinit le rapport à l’État et ouvre à des procès de gouvernement par instrumentation”, explique le sociologue Fabien Granjon en introduction du numéro, qui rappelle que ces développements suivent des phases en regardant celles des pays scandinaves, pionniers en la matière. Pourtant, là-bas comme ailleurs, la numérisation n’a pas aidé ou apaisé la relation administrative, au con
L’avant dernier numéro de la revue Réseaux est consacré à la dématérialisation. “La numérisation des administrations redéfinit le rapport à l’État et ouvre à des procès de gouvernement par instrumentation”, explique le sociologue Fabien Granjonen introduction du numéro, qui rappelle que ces développements suivent des phases en regardant celles des pays scandinaves, pionniers en la matière. Pourtant, là-bas comme ailleurs, la numérisation n’a pas aidé ou apaisé la relation administrative, au contraire. Là-bas aussi, elle rend plus difficile l’accès aux droits. En fait, plus qu’un changement d’outillage, elle est une “évolution de nature politique” qui redéfinit les rapports à l’État, à la vie sociale et aux citoyens, notamment parce qu’elle s’accompagne toujours de la fermeture des guichets d’accueil physique, créant des situations d’accès inégalitaires qui restreignennt la qualité et la continuité des services publics. “La dématérialisation de l’action publique signe en cela une double délégation. D’un côté, certaines opérations sont déléguées aux dispositifs techniques ; de l’autre, on constate un déplacement complémentaire de celles-ci vers les usagers, qui portent désormais la charge et la responsabilité du bon déroulement des démarches au sein desquelles ils s’inscrivent.“ A France Travail, explique Mathilde Boeglin-Henky, les outils permettent de trier les postulants entre ceux capables de se débrouiller et les autres. L’accès aux outils numériques et leur maîtrise devient un nouveau critère d’éligibilité aux droits, générateur de non-recours : le numérique devient une “charge supplémentaire” pour les plus vulnérables. La simplification devient pour eux une “complication effective”. Pour surmonter ces difficultés, l’entraide s’impose, notamment celle des professionnels de l’accompagnement et des associations d’aide aux usagers. Mais ces nouvelles missions qui leur incombent viennent “déplacer le périmètre de leurs missions premières”, au risque de les remplacer.
L’article de Pierre Mazet du Lab Accès sur le dispositif Conseiller numérique France Services (CnFS) montre qu’il se révèle fragile, profitant d’abord aux structures préalablement les plus engagées sur l’inclusion numérique. L’État s’est appuyé sur le plan de relance européen afin de transférer aux acteurs locaux la prise en charge d’un problème public dont les conseillers numériques doivent assumer la charge. Les moyens s’avèrent « structurellement insuffisants pour stabiliser une réponse proportionnée aux besoins ». À l’échelle nationale, les démarches en ligne se placent en tête des aides réalisées par les CnFS, montrant que « les besoins d’accompagnement sont bel et bien indexés à la numérisation des administrations »; et de constater qu’il y a là une « situation pour le moins paradoxale d’une action publique – les programmes d’inclusion numérique – qui ne parvient pas à répondre aux besoins générés par une autre action publique – les politiques de dématérialisation ». Le financement du dispositif a plus tenu d’un effet d’aubaine profitant à certains acteurs, notamment aux acteurs de la dématérialisation de la relation administrative, qu’il n’a permis de répondre à la géographie sociale des besoins. « Le dispositif a essentiellement atteint le public des personnes âgées, moins en réponse à des besoins qu’en raison du ciblage de l’offre elle-même : elle capte d’abord des publics « disponibles », pas nécessairement ceux qui en ont le plus besoin ». Enfin, la dégressivité des financements a, quant à elle, « produit un effet de sélection, qui a accentué les inégalités entre acteurs et territoires », notamment au détriment des acteurs de la médiation numérique.
La gouvernance par dispositifs numériques faciliterait l’avènement d’une administration d’orientation néolibérale priorisant les valeurs du marché, explique Granjon. L’administration « renforcerait son contrôle sur les populations, mais, paradoxalement, perdrait le contrôle sur ses principaux outils, notamment ceux d’aide à la décision quant à l’octroi de droits et de subsides ». La décision confiée aux procédures de calcul, laisse partout peu de marge de manœuvre aux agents, les transformant en simples exécutants. A Pôle Emploi, par exemple, il s’agit moins de trouver un emploi aux chômeurs que de les rendre « autonomes » avec les outils numériques. Pour Périne Brotcorne pourtant, malgré la sempiternelle affirmation d’une “approche usager”, ceux-ci sont absents des développements numériques des services publics. Rien n’est fait par exemple pour l’usager en difficulté par exemple pour qu’il puisse déléguer la prise en charge de ses tâches administratives à un tiers, comme le soulignait récemment le Défenseur des droits. Les interfaces numériques, trop complexes, fabriquent “de l’incapacité” pour certains publics, notamment les plus éloignés et les plus vulnérables. Brotcorne montre d’ailleurs très bien que “l’usager” est un concept qui permet d’avoir une “vision sommaire des publics destinataires”. Au final, les besoins s’adaptent surtout aux demandes des administrations qu’aux usagers qui ne sont pas vraiment invités à s’exprimer. L’étude souligne que près de la moitié des usagers n’arrivent pas à passer la première étape des services publics numériques que ce soit se connecter, prendre rendez-vous ou même télécharger un formulaire. Dans un autre article, signé Anne-Sylvie Pharabod et Céline Borelle, les deux chercheuses auscultent les pratiques administratives numérisées ordinaires qui montrent que la numérisation est une longue habituation, où les démarches apprises pour un service permettent d’en aborder d’autres. Les démarches administratives sont un univers de tâches dont il faut apprendre à se débrouiller, comme faire se peut, et qui en même temps sont toujours remises à zéro par leurs transformations, comme l’évolution des normes des mots de passe, des certifications d’identité, ou des documents à uploader. “La diversité des démarches, l’hétérogénéité des interfaces et l’évolution rapide des outils liée à des améliorations incrémentales (notamment en matière de sécurité) renouvellent constamment le questionnement sur ce qu’il convient de faire”.
Dans un autre article, assez complexe, Fabien Granjon explore comment l’introduction de nouveaux dispositifs numériques au sein du Service public de l’emploi a pour conséquence une reconfiguration majeure de celui-ci et provoque des changements dans les structures de relations entre acteurs. L’instrumentation numérique se voit investie de la fonction de régulation des comportements des usagers, des agents publics, mais également de bien d’autres publics, notamment tous ceux utilisant ses données et plateformes. A cette aune, France Travail est amené à devenir un « animateur d’écosystème emploi/formation/insertion » connectant divers échelons territoriaux d’intervention et une multitude d’acteurs y intervenant, comme l’expose, en partie, France Travail, via ses différentes plateformes. Granjon invite à s’intéresser à ces encastrements nouveaux et pas seulement aux guichets, ou à la relation agent-public, pour mieux saisir comment les bases de données, les API façonnent les relations avec les sous-traitants comme avec tous ceux qui interviennent depuis les procédures que France Travail met en place.
Le numéro de Réseaux livre également un intéressant article, très critique, du Dossier médical partagé, signé Nicolas Klein et Alexandre Mathieu-Fritz, qui s’intéresse à l’histoire de la gouvernance problématique du projet, qui explique en grande partie ses écueils, et au fait que le DMP ne semble toujours pas avoir trouvé son utilité pour les professionnels de santé.
Un autre article signé Pauline Boyer explore le lancement du portail de données ouvertes de l’Etat et montre notamment que l’innovation n’est pas tant politique que de terrain. Samuel Goëta et Élise Ho-Pun-Cheung s’intéressent quant à eux à la production de standards et aux difficultés de leur intégration dans le quotidien des agents, en observant le processus de standardisation des données des lieux de médiation numérique. L’article souligne la difficulté des conseillers numériques à infléchir la standardisation et montre que cette normalisation peine à prévoir les usages de la production de données.
Dans un article de recherche qui n’est pas publié par Réseaux, mais complémentaire à son dossier, le politologue néerlandais, Pascal D. Koenig explique que le développement d’un État algorithmique modifie la relation avec les citoyens, ce qui nécessite de regarder au-delà des seules propriétés des systèmes. L’intégration des algos et de l’IA développe une relation plus impersonnelle, renforçant le contrôle et l’asymétrie de pouvoir. Pour Koenig, cela affecte directement la reconnaissance sociale des individus et le respect qu’ils peuvent attendre d’une institution. “Les systèmes d’IA, qui remplacent ou assistent l’exécution des tâches humaines, introduisent un nouveau type de représentation des agents dans les organisations gouvernementales. Ils réduisent ainsi structurellement la représentation des citoyens – en tant qu’êtres humains – au sein de l’État et augmentent les asymétries de pouvoir, en étendant unilatéralement le pouvoir informationnel de l’État”. L’utilisation de l’IA affecte également les fondements de la reconnaissance sociale dans la relation citoyen-État, liés au comportement. En tant qu’agents artificiels, les systèmes d’IA manquent de compréhension et de compassion humaines, dont l’expression dans de nombreuses interactions est un élément important pour reconnaître et traiter une personne en tant qu’individu. C’est l’absence de reconnaissance sociale qui augmente la perception de la violence administrative. “L’instauration structurelle d’une hiérarchie plus forte entre l’État et les citoyens signifie que ces derniers sont moins reconnus dans leur statut de citoyens, ce qui érode le respect que les institutions leur témoignent”. Le manque d’empathie des systèmes est l’une des principales raisons pour lesquelles les individus s’en méfient, rappelle Koenig. Or, “la numérisation et l’automatisation de l’administration réduisent les foyers d’empathie existants et contribuent à une prise en compte étroite des besoins divers des citoyens”. “Avec un gouvernement de plus en plus algorithmique, l’État devient moins capable de compréhension empathique”. Plus encore, l’automatisation de l’Etat montre aux citoyens un appareil gouvernemental où le contact humain se réduit : moins représentatif, il est donc moins disposé à prendre des décisions dans leur intérêt.
L’avant dernier numéro de la revue Réseaux est consacré à la dématérialisation. “La numérisation des administrations redéfinit le rapport à l’État et ouvre à des procès de gouvernement par instrumentation”, explique le sociologue Fabien Granjon en introduction du numéro, qui rappelle que ces développements suivent des phases en regardant celles des pays scandinaves, pionniers en la matière. Pourtant, là-bas comme ailleurs, la numérisation n’a pas aidé ou apaisé la relation administrative, au con
L’avant dernier numéro de la revue Réseaux est consacré à la dématérialisation. “La numérisation des administrations redéfinit le rapport à l’État et ouvre à des procès de gouvernement par instrumentation”, explique le sociologue Fabien Granjonen introduction du numéro, qui rappelle que ces développements suivent des phases en regardant celles des pays scandinaves, pionniers en la matière. Pourtant, là-bas comme ailleurs, la numérisation n’a pas aidé ou apaisé la relation administrative, au contraire. Là-bas aussi, elle rend plus difficile l’accès aux droits. En fait, plus qu’un changement d’outillage, elle est une “évolution de nature politique” qui redéfinit les rapports à l’État, à la vie sociale et aux citoyens, notamment parce qu’elle s’accompagne toujours de la fermeture des guichets d’accueil physique, créant des situations d’accès inégalitaires qui restreignennt la qualité et la continuité des services publics. “La dématérialisation de l’action publique signe en cela une double délégation. D’un côté, certaines opérations sont déléguées aux dispositifs techniques ; de l’autre, on constate un déplacement complémentaire de celles-ci vers les usagers, qui portent désormais la charge et la responsabilité du bon déroulement des démarches au sein desquelles ils s’inscrivent.“ A France Travail, explique Mathilde Boeglin-Henky, les outils permettent de trier les postulants entre ceux capables de se débrouiller et les autres. L’accès aux outils numériques et leur maîtrise devient un nouveau critère d’éligibilité aux droits, générateur de non-recours : le numérique devient une “charge supplémentaire” pour les plus vulnérables. La simplification devient pour eux une “complication effective”. Pour surmonter ces difficultés, l’entraide s’impose, notamment celle des professionnels de l’accompagnement et des associations d’aide aux usagers. Mais ces nouvelles missions qui leur incombent viennent “déplacer le périmètre de leurs missions premières”, au risque de les remplacer.
L’article de Pierre Mazet du Lab Accès sur le dispositif Conseiller numérique France Services (CnFS) montre qu’il se révèle fragile, profitant d’abord aux structures préalablement les plus engagées sur l’inclusion numérique. L’État s’est appuyé sur le plan de relance européen afin de transférer aux acteurs locaux la prise en charge d’un problème public dont les conseillers numériques doivent assumer la charge. Les moyens s’avèrent « structurellement insuffisants pour stabiliser une réponse proportionnée aux besoins ». À l’échelle nationale, les démarches en ligne se placent en tête des aides réalisées par les CnFS, montrant que « les besoins d’accompagnement sont bel et bien indexés à la numérisation des administrations »; et de constater qu’il y a là une « situation pour le moins paradoxale d’une action publique – les programmes d’inclusion numérique – qui ne parvient pas à répondre aux besoins générés par une autre action publique – les politiques de dématérialisation ». Le financement du dispositif a plus tenu d’un effet d’aubaine profitant à certains acteurs, notamment aux acteurs de la dématérialisation de la relation administrative, qu’il n’a permis de répondre à la géographie sociale des besoins. « Le dispositif a essentiellement atteint le public des personnes âgées, moins en réponse à des besoins qu’en raison du ciblage de l’offre elle-même : elle capte d’abord des publics « disponibles », pas nécessairement ceux qui en ont le plus besoin ». Enfin, la dégressivité des financements a, quant à elle, « produit un effet de sélection, qui a accentué les inégalités entre acteurs et territoires », notamment au détriment des acteurs de la médiation numérique.
La gouvernance par dispositifs numériques faciliterait l’avènement d’une administration d’orientation néolibérale priorisant les valeurs du marché, explique Granjon. L’administration « renforcerait son contrôle sur les populations, mais, paradoxalement, perdrait le contrôle sur ses principaux outils, notamment ceux d’aide à la décision quant à l’octroi de droits et de subsides ». La décision confiée aux procédures de calcul, laisse partout peu de marge de manœuvre aux agents, les transformant en simples exécutants. A Pôle Emploi, par exemple, il s’agit moins de trouver un emploi aux chômeurs que de les rendre « autonomes » avec les outils numériques. Pour Périne Brotcorne pourtant, malgré la sempiternelle affirmation d’une “approche usager”, ceux-ci sont absents des développements numériques des services publics. Rien n’est fait par exemple pour l’usager en difficulté par exemple pour qu’il puisse déléguer la prise en charge de ses tâches administratives à un tiers, comme le soulignait récemment le Défenseur des droits. Les interfaces numériques, trop complexes, fabriquent “de l’incapacité” pour certains publics, notamment les plus éloignés et les plus vulnérables. Brotcorne montre d’ailleurs très bien que “l’usager” est un concept qui permet d’avoir une “vision sommaire des publics destinataires”. Au final, les besoins s’adaptent surtout aux demandes des administrations qu’aux usagers qui ne sont pas vraiment invités à s’exprimer. L’étude souligne que près de la moitié des usagers n’arrivent pas à passer la première étape des services publics numériques que ce soit se connecter, prendre rendez-vous ou même télécharger un formulaire. Dans un autre article, signé Anne-Sylvie Pharabod et Céline Borelle, les deux chercheuses auscultent les pratiques administratives numérisées ordinaires qui montrent que la numérisation est une longue habituation, où les démarches apprises pour un service permettent d’en aborder d’autres. Les démarches administratives sont un univers de tâches dont il faut apprendre à se débrouiller, comme faire se peut, et qui en même temps sont toujours remises à zéro par leurs transformations, comme l’évolution des normes des mots de passe, des certifications d’identité, ou des documents à uploader. “La diversité des démarches, l’hétérogénéité des interfaces et l’évolution rapide des outils liée à des améliorations incrémentales (notamment en matière de sécurité) renouvellent constamment le questionnement sur ce qu’il convient de faire”.
Dans un autre article, assez complexe, Fabien Granjon explore comment l’introduction de nouveaux dispositifs numériques au sein du Service public de l’emploi a pour conséquence une reconfiguration majeure de celui-ci et provoque des changements dans les structures de relations entre acteurs. L’instrumentation numérique se voit investie de la fonction de régulation des comportements des usagers, des agents publics, mais également de bien d’autres publics, notamment tous ceux utilisant ses données et plateformes. A cette aune, France Travail est amené à devenir un « animateur d’écosystème emploi/formation/insertion » connectant divers échelons territoriaux d’intervention et une multitude d’acteurs y intervenant, comme l’expose, en partie, France Travail, via ses différentes plateformes. Granjon invite à s’intéresser à ces encastrements nouveaux et pas seulement aux guichets, ou à la relation agent-public, pour mieux saisir comment les bases de données, les API façonnent les relations avec les sous-traitants comme avec tous ceux qui interviennent depuis les procédures que France Travail met en place.
Le numéro de Réseaux livre également un intéressant article, très critique, du Dossier médical partagé, signé Nicolas Klein et Alexandre Mathieu-Fritz, qui s’intéresse à l’histoire de la gouvernance problématique du projet, qui explique en grande partie ses écueils, et au fait que le DMP ne semble toujours pas avoir trouvé son utilité pour les professionnels de santé.
Un autre article signé Pauline Boyer explore le lancement du portail de données ouvertes de l’Etat et montre notamment que l’innovation n’est pas tant politique que de terrain. Samuel Goëta et Élise Ho-Pun-Cheung s’intéressent quant à eux à la production de standards et aux difficultés de leur intégration dans le quotidien des agents, en observant le processus de standardisation des données des lieux de médiation numérique. L’article souligne la difficulté des conseillers numériques à infléchir la standardisation et montre que cette normalisation peine à prévoir les usages de la production de données.
Dans un article de recherche qui n’est pas publié par Réseaux, mais complémentaire à son dossier, le politologue néerlandais, Pascal D. Koenig explique que le développement d’un État algorithmique modifie la relation avec les citoyens, ce qui nécessite de regarder au-delà des seules propriétés des systèmes. L’intégration des algos et de l’IA développe une relation plus impersonnelle, renforçant le contrôle et l’asymétrie de pouvoir. Pour Koenig, cela affecte directement la reconnaissance sociale des individus et le respect qu’ils peuvent attendre d’une institution. “Les systèmes d’IA, qui remplacent ou assistent l’exécution des tâches humaines, introduisent un nouveau type de représentation des agents dans les organisations gouvernementales. Ils réduisent ainsi structurellement la représentation des citoyens – en tant qu’êtres humains – au sein de l’État et augmentent les asymétries de pouvoir, en étendant unilatéralement le pouvoir informationnel de l’État”. L’utilisation de l’IA affecte également les fondements de la reconnaissance sociale dans la relation citoyen-État, liés au comportement. En tant qu’agents artificiels, les systèmes d’IA manquent de compréhension et de compassion humaines, dont l’expression dans de nombreuses interactions est un élément important pour reconnaître et traiter une personne en tant qu’individu. C’est l’absence de reconnaissance sociale qui augmente la perception de la violence administrative. “L’instauration structurelle d’une hiérarchie plus forte entre l’État et les citoyens signifie que ces derniers sont moins reconnus dans leur statut de citoyens, ce qui érode le respect que les institutions leur témoignent”. Le manque d’empathie des systèmes est l’une des principales raisons pour lesquelles les individus s’en méfient, rappelle Koenig. Or, “la numérisation et l’automatisation de l’administration réduisent les foyers d’empathie existants et contribuent à une prise en compte étroite des besoins divers des citoyens”. “Avec un gouvernement de plus en plus algorithmique, l’État devient moins capable de compréhension empathique”. Plus encore, l’automatisation de l’Etat montre aux citoyens un appareil gouvernemental où le contact humain se réduit : moins représentatif, il est donc moins disposé à prendre des décisions dans leur intérêt.
Le dernier numéro de la revue Multitudes (n°98, printemps 2025) publie un ensemble de contributions sur les questions algorithmiques au travers de cinq enquêtes de jeunes sociologues.
Camille Girard-Chanudet décrit la tension entre expertise algorithmique et expertise juridique dans l’essor des startups de la legal tech venues de l’extérieur des tribunaux pour les transformer.
Héloïse Eloi‑Hammer observe les différences d’implémentations des algorithmes locaux dans Parcoursup pour montre
Le dernier numéro de la revue Multitudes (n°98, printemps 2025) publie un ensemble de contributions sur les questions algorithmiques au travers de cinq enquêtes de jeunes sociologues.
Camille Girard-Chanudet décrit la tension entre expertise algorithmique et expertise juridique dans l’essor des startups de la legal tech venues de l’extérieur des tribunaux pour les transformer.
Héloïse Eloi‑Hammer observe les différences d’implémentations des algorithmes locaux dans Parcoursup pour montrer que les formations n’ont pas les mêmes moyens pour configurer la plateforme et que souvent, elles utilisent des procédés de sélection rudimentaires. Elle montre que, là aussi, “les algorithmes sont contraints par les contextes organisationnels et sociaux dans lesquels leurs concepteurs sont pris” et peuvent avoir des fonctionnements opposés aux valeurs des formations qui les mettent en œuvre.
Jérémie Poiroux évoque, lui, l’utilisation de l’IA pour l’inspection des navires, une forme de contrôle technique des activités maritimes qui permet de montrer comment le calcul et l’évolution de la réglementation sont mobilisées pour réduire les effectifs des services de l’Etat tout en améliorant le ciblage des contrôles. Pour Poiroux, le système mis en place pose des questions quant à son utilisation et surtout montre que l’Etat fait des efforts pour “consacrer moins de moyens à la prévention et à l’accompagnement, afin de réduire son champ d’action au contrôle et à la punition”, ainsi qu’à éloigner les agents au profit de règles venues d’en haut.
Soizic Pénicaud revient quant à elle sur l’histoire de la mobilisation contre les outils de ciblage de la CAF. Elle souligne que la mobilisation de différents collectifs n’est pas allé de soi et que le recueil de témoignages a permis de soulever le problème et d’incarner les difficultés auxquelles les personnes étaient confrontées. Et surtout que les collectifs ont du travailler pour “arracher la transparence”, pour produire des chiffres sur une réalité.
Maud Barret Bertelloni conclut le dossier en se demandant en quoi les algorithmes sont des outils de gouvernement. Elle rappelle que les algorithmes n’oeuvrent pas seuls. Le déploiement des algorithmes à la CAF permet la structuration et l’intensification d’une politique rigoriste qui lui préexiste. “L’algorithme ne se substitue pas aux pratiques précédentes de contrôle. Il s’y intègre (…). Il ne l’automatise pas non plus : il le « flèche »”. Elle rappelle, à la suite du travail de Vincent Dubois dans Contrôler les assistés, que le développement des systèmes de calculs permettent à la fois de produire un contrôle réorganisé, national, au détriment de l’autonomie des agents et des caisses locales, ainsi que de légitimer la culture du contrôle et de donner une nouvelle orientation aux services publics.
Comme le murmure Loup Cellard en ouverture du dossier : “l’algorithmisation des États est le signe d’un positivisme : croyance dans la Science, confiance dans son instrumentalisme, impersonnalité de son pouvoir”.
Mardi 3 juin à 19h30 à la librairie L’atelier, 2 bis rue Jourdain, 75020 Paris, une rencontre est organisée autour des chercheurs et chercheuses qui ont participé à ce numéro. Nous y serons.
Le dernier numéro de la revue Multitudes (n°98, printemps 2025) publie un ensemble de contributions sur les questions algorithmiques au travers de cinq enquêtes de jeunes sociologues.
Camille Girard-Chanudet décrit la tension entre expertise algorithmique et expertise juridique dans l’essor des startups de la legal tech venues de l’extérieur des tribunaux pour les transformer.
Héloïse Eloi‑Hammer observe les différences d’implémentations des algorithmes locaux dans Parcoursup pour montre
Le dernier numéro de la revue Multitudes (n°98, printemps 2025) publie un ensemble de contributions sur les questions algorithmiques au travers de cinq enquêtes de jeunes sociologues.
Camille Girard-Chanudet décrit la tension entre expertise algorithmique et expertise juridique dans l’essor des startups de la legal tech venues de l’extérieur des tribunaux pour les transformer.
Héloïse Eloi‑Hammer observe les différences d’implémentations des algorithmes locaux dans Parcoursup pour montrer que les formations n’ont pas les mêmes moyens pour configurer la plateforme et que souvent, elles utilisent des procédés de sélection rudimentaires. Elle montre que, là aussi, “les algorithmes sont contraints par les contextes organisationnels et sociaux dans lesquels leurs concepteurs sont pris” et peuvent avoir des fonctionnements opposés aux valeurs des formations qui les mettent en œuvre.
Jérémie Poiroux évoque, lui, l’utilisation de l’IA pour l’inspection des navires, une forme de contrôle technique des activités maritimes qui permet de montrer comment le calcul et l’évolution de la réglementation sont mobilisées pour réduire les effectifs des services de l’Etat tout en améliorant le ciblage des contrôles. Pour Poiroux, le système mis en place pose des questions quant à son utilisation et surtout montre que l’Etat fait des efforts pour “consacrer moins de moyens à la prévention et à l’accompagnement, afin de réduire son champ d’action au contrôle et à la punition”, ainsi qu’à éloigner les agents au profit de règles venues d’en haut.
Soizic Pénicaud revient quant à elle sur l’histoire de la mobilisation contre les outils de ciblage de la CAF. Elle souligne que la mobilisation de différents collectifs n’est pas allé de soi et que le recueil de témoignages a permis de soulever le problème et d’incarner les difficultés auxquelles les personnes étaient confrontées. Et surtout que les collectifs ont du travailler pour “arracher la transparence”, pour produire des chiffres sur une réalité.
Maud Barret Bertelloni conclut le dossier en se demandant en quoi les algorithmes sont des outils de gouvernement. Elle rappelle que les algorithmes n’oeuvrent pas seuls. Le déploiement des algorithmes à la CAF permet la structuration et l’intensification d’une politique rigoriste qui lui préexiste. “L’algorithme ne se substitue pas aux pratiques précédentes de contrôle. Il s’y intègre (…). Il ne l’automatise pas non plus : il le « flèche »”. Elle rappelle, à la suite du travail de Vincent Dubois dans Contrôler les assistés, que le développement des systèmes de calculs permettent à la fois de produire un contrôle réorganisé, national, au détriment de l’autonomie des agents et des caisses locales, ainsi que de légitimer la culture du contrôle et de donner une nouvelle orientation aux services publics.
Comme le murmure Loup Cellard en ouverture du dossier : “l’algorithmisation des États est le signe d’un positivisme : croyance dans la Science, confiance dans son instrumentalisme, impersonnalité de son pouvoir”.
Mardi 3 juin à 19h30 à la librairie L’atelier, 2 bis rue Jourdain, 75020 Paris, une rencontre est organisée autour des chercheurs et chercheuses qui ont participé à ce numéro. Nous y serons.
La politologue Erica Chenoweth est la directrice du Non Violent Action Lab à Harvard. Elle a publié de nombreux livres pour montrer que la résistance non violente avait des effets, notamment, en français Pouvoir de la non-violence : pourquoi la résistance civile est efficace (Calmann Levy, 2021). Mais ce n’est plus le constat qu’elle dresse. Elle prépare d’ailleurs un nouveau livre, The End of People Power, qui pointe le déclin déroutant des mouvements de résistance civile au cours de la dernièr
La politologueErica Chenoweth est la directrice du Non Violent Action Lab à Harvard. Elle a publié de nombreux livres pour montrer que la résistance non violente avait des effets, notamment, en français Pouvoir de la non-violence : pourquoi la résistance civile est efficace (Calmann Levy, 2021). Mais ce n’est plus le constat qu’elle dresse. Elle prépare d’ailleurs un nouveau livre, The End of PeoplePower, qui pointe le déclin déroutant des mouvements de résistance civile au cours de la dernière décennie, alors même que ces techniques sont devenues très populaires dans le monde entier. Lors d’une récente conférence sur l’IA et les libertés démocratiques organisée par le Knight First Amendment Institute de l’université de Columbia, elle se demandait si l’IA pouvait soutenir les revendications démocratiques, rapporte Tech Policy Press (vidéo). L’occasion de rendre compte à notre tour d’un point de vue décoiffant qui interroge en profondeur notre rapport à la démocratie.
La récession démocratique est engagée
La démocratie est en déclin, explique Erica Chenoweth. Dans son rapport annuel, l’association internationale Freedom House parle même de “récession démocratique” et estime que la sauvegarde des droits démocratiques est partout en crise. 2025 pourrait être la première année, depuis longtemps, où la majorité de la population mondiale vit sous des formes de gouvernement autoritaires plutôt que démocratiques. Ce recul est dû à la fois au développement de l’autoritarisme dans les régimes autocratiques et à l’avancée de l’autocratie dans les démocraties établies, explique Chenoweth. Les avancées démocratiques des 100 dernières années ont été nombreuses et assez générales. Elles ont d’abord été le fait de mouvements non violents, populaires, où des citoyens ordinaires ont utilisé les manifestations et les grèves, bien plus que les insurrections armées, pour déployer la démocratie là où elle était empêchée. Mais ces succès sont en déclin. Les taux de réussite des mouvements populaires pacifistes comme armés, se sont effondrés, notamment au cours des dix dernières années. “Il y a quelque chose de global et de systémique qui touche toutes les formes de mobilisation de masse. Ce n’est pas seulement que les manifestations pacifiques sont inefficaces, mais que, de fait, les opposants à ces mouvements sont devenus plus efficaces pour les vaincre en général”.
Les épisodes de contestation réformistes (qui ne relèvent pas de revendications maximalistes, comme les mouvements démocratiques), comprenant les campagnes pour les salaires et le travail, les mouvements environnementaux, les mouvements pour la justice raciale, l’expansion des droits civiques, les droits des femmes… n’ont cessé de subir des revers et des défaites au cours des deux dernières décennies, et ont même diminué leur capacité à obtenir des concessions significatives, à l’image de la contestation de la réforme des retraites en France ou des mouvements écologiques, plus écrasés que jamais. Et ce alors que ces techniques de mobilisation sont plus utilisées que jamais.
Selon la littérature, ce qui permet aux mouvements populaires de réussir repose sur une participation large et diversifiée, c’est-à-dire transversale à l’ensemble de la société, transcendant les clivages raciaux, les clivages de classe, les clivages urbains-ruraux, les clivages partisans… Et notamment quand ils suscitent le soutien de personnes très différentes les unes des autres. “Le principal défi pour les mouvements de masse qui réclament un changement pour étendre la démocratie consiste bien souvent à disloquer les piliers des soutiens autocratiques comme l’armée ou les fonctionnaires. L’enjeu, pour les mouvements démocratiques, consiste à retourner la répression à l’encontre de la population en la dénonçant pour modifier l’opinion générale ». Enfin, les mouvements qui réussissent enchaînent bien souvent les tactiques plutôt que de reposer sur une technique d’opposition unique, afin de démultiplier les formes de pression.
La répression s’est mise à niveau
Mais l’autocratie a appris de ses erreurs. Elle a adapté en retour ses tactiques pour saper les quatre voies par lesquelles les mouvements démocratiques l’emportent. “La première consiste à s’assurer que personne ne fasse défection. La deuxième consiste à dominer l’écosystème de l’information et à remporter la guerre de l’information. La troisième consiste à recourir à la répression sélective de manière à rendre très difficile pour les mouvements d’exploiter les moments d’intense brutalité. Et la quatrième consiste à perfectionner l’art de diviser pour mieux régner”. Pour que l’armée ou la police ne fasse pas défection, les autorités ont amélioré la formation des forces de sécurité. La corruption et le financement permet de s’attacher des soutiens plus indéfectibles. Les forces de sécurité sont également plus fragmentées, afin qu’une défection de l’une d’entre elles, n’implique pas les autres. Enfin, il s’agit également de faire varier la répression pour qu’une unité de sécurité ne devienne pas une cible de mouvements populaires par rapport aux autres. Les purges et les répressions des personnes déloyales ou suspectes sont devenues plus continues et violentes. “L’ensemble de ces techniques a rendu plus difficile pour les mouvements civiques de provoquer la défection des forces de sécurité, et cette tendance s’est accentuée au fil du temps”.
La seconde adaptation clé a consisté à gagner la guerre de l’information, notamment en dominant les écosystèmes de l’information. “Inonder la zone de rumeurs, de désinformation et de propagande, dont certaines peuvent être créées et testées par différents outils d’IA, en fait partie. Il en va de même pour la coupure d’Internet aux moments opportuns, puis sa réouverture au moment opportun”.
Le troisième volet de la panoplie consiste à appliquer une répression sélective, consistant à viser des individus plutôt que les mouvements pour des crimes graves qui peuvent sembler décorrélé des manifestations, en les accusant de terrorisme ou de préparation de coup d’Etat. ”La guerre juridique est un autre outil administratif clé”.
Le quatrième volet consiste à diviser pour mieux régner. En encourageant la mobilisation loyaliste, en induisant des divisions dans les mouvements, en les infiltrant pour les radicaliser, en les poussant à des actions violentes pour générer des reflux d’opinion…
Comment utiliser l’IA pour gagner ?
Dans la montée de l’adaptation des techniques pour défaire leurs opposants, la technologie joue un rôle, estime Erica Chenoweth. Jusqu’à présent, les mouvements civiques ont plutôt eu tendance à s’approprier et à utiliser, souvent de manière très innovantes, les technologies à leur avantage, par exemple à l’heure de l’arrivée d’internet, qui a très tôt été utilisé pour s’organiser et se mobiliser. Or, aujourd’hui, les mouvements civiques sont bien plus prudents et sceptiques à utiliser l’IA, contrairement aux régimes autocratiques. Pourtant, l’un des principaux problèmes des mouvements civiques consiste à “cerner leur environnement opérationnel”, c’est-à-dire de savoir qui est connecté à qui, qui les soutient ou pourrait les soutenir, sous quelles conditions ? Où sont les vulnérabilités du mouvement ? Réfléchir de manière créative à ces questions et enjeux, aux tactiques à déployer pourrait pourtant être un atout majeur pour que les mouvements démocratiques réussissent.
Les mouvements démocratiques passent bien plus de temps à sensibiliser et communiquer qu’à faire de la stratégie, rappelle la chercheuse. Et c’est là deux enjeux où les IA pourraient aider, estime-t-elle. En 2018 par exemple, lors des élections municipales russe, un algorithme a permis de contrôler les images de vidéosurveillance des bureaux de vote pour détecter des irrégularités permettant de dégager les séquences où des bulletins préremplis avaient été introduits dans les urnes. Ce qui aurait demandé un contrôle militant épuisant a pu être accompli très simplement. Autre exemple avec les applications BuyCat, BoyCott ou NoThanks, qui sont des applications de boycott de produits, permettant aux gens de participer très facilement à des actions (des applications puissantes, mais parfois peu transparentes sur leurs méthodes, expliquait Le Monde). Pour Chenoweth, les techniques qui fonctionnent doivent être mieux documentées et partagées pour qu’elles puissent servir à d’autres. Certains groupes proposent d’ailleurs déjà des formations sur l’utilisation de l’IA pour l’action militante, comme c’est le cas de Canvas, de Social Movement Technologies et du Cooperative Impact Lab.
Le Non Violent Action Lab a d’ailleurs publié un rapport sur le sujet : Comment l’IA peut-elle venir aider les mouvements démocratiques ? Pour Chenoweth, il est urgent d’évaluer si les outils d’IA facilitent ou compliquent réellement le succès des mouvements démocratiques. Encore faudrait-il que les mouvements démocratiques puissent accéder à des outils d’IA qui ne partagent pas leurs données avec des plateformes et avec les autorités. L’autre enjeu consiste à construire des corpus adaptés pour aider les mouvements à résister. Les corpus de l’IA s’appuient sur des données des 125 dernières années, alors que l’on sait déjà que ce qui fonctionnait il y a 60 ans ne fonctionne plus nécessairement.
Pourtant, estime Chenoweth, les mouvements populaires ont besoin d’outils pour démêler des processus délibératifs souvent complexes, et l’IA devrait pouvoir les y aider. “Aussi imparfait qu’ait été notre projet démocratique, nous le regretterons certainement lorsqu’il prendra fin”, conclut la politologue. En invitant les mouvements civiques à poser la question de l’utilisation de l’IA a leur profit, plutôt que de la rejetter d’emblée comme l’instrument de l’autoritarisme, elle invite à faire un pas de côté pour trouver des modalités pour refaire gagner les luttes sociales.
On lui suggérera tout de même de regarder du côté des projets que Audrey Tang mène à Taïwan avec le Collective intelligence for collective progress, comme ses « assemblées d’alignement » qui mobilise l’IA pour garantir une participation équitable et une écoute active de toutes les opinions. Comme Tang le défend dans son manifeste, Plurality, l’IA pourrait être une technologie d’extension du débat démocratique pour mieux organiser la complexité. Tang parle d’ailleurs de broad listening (« écoute élargie ») pour l’opposer au broadcasting, la diffusion de un vers tous. Une méthode mobilisée par un jeune ingénieur au poste de gouverneur de Tokyo, Takahiro Anno, qui a bénéficié d’une audience surprenante, sans néanmoins l’emporter. Son adversaire a depuis mobilisé la méthode pour lancer une consultation, Tokyo 2050.
La politologue Erica Chenoweth est la directrice du Non Violent Action Lab à Harvard. Elle a publié de nombreux livres pour montrer que la résistance non violente avait des effets, notamment, en français Pouvoir de la non-violence : pourquoi la résistance civile est efficace (Calmann Levy, 2021). Mais ce n’est plus le constat qu’elle dresse. Elle prépare d’ailleurs un nouveau livre, The End of People Power, qui pointe le déclin déroutant des mouvements de résistance civile au cours de la dernièr
La politologueErica Chenoweth est la directrice du Non Violent Action Lab à Harvard. Elle a publié de nombreux livres pour montrer que la résistance non violente avait des effets, notamment, en français Pouvoir de la non-violence : pourquoi la résistance civile est efficace (Calmann Levy, 2021). Mais ce n’est plus le constat qu’elle dresse. Elle prépare d’ailleurs un nouveau livre, The End of PeoplePower, qui pointe le déclin déroutant des mouvements de résistance civile au cours de la dernière décennie, alors même que ces techniques sont devenues très populaires dans le monde entier. Lors d’une récente conférence sur l’IA et les libertés démocratiques organisée par le Knight First Amendment Institute de l’université de Columbia, elle se demandait si l’IA pouvait soutenir les revendications démocratiques, rapporte Tech Policy Press (vidéo). L’occasion de rendre compte à notre tour d’un point de vue décoiffant qui interroge en profondeur notre rapport à la démocratie.
La récession démocratique est engagée
La démocratie est en déclin, explique Erica Chenoweth. Dans son rapport annuel, l’association internationale Freedom House parle même de “récession démocratique” et estime que la sauvegarde des droits démocratiques est partout en crise. 2025 pourrait être la première année, depuis longtemps, où la majorité de la population mondiale vit sous des formes de gouvernement autoritaires plutôt que démocratiques. Ce recul est dû à la fois au développement de l’autoritarisme dans les régimes autocratiques et à l’avancée de l’autocratie dans les démocraties établies, explique Chenoweth. Les avancées démocratiques des 100 dernières années ont été nombreuses et assez générales. Elles ont d’abord été le fait de mouvements non violents, populaires, où des citoyens ordinaires ont utilisé les manifestations et les grèves, bien plus que les insurrections armées, pour déployer la démocratie là où elle était empêchée. Mais ces succès sont en déclin. Les taux de réussite des mouvements populaires pacifistes comme armés, se sont effondrés, notamment au cours des dix dernières années. “Il y a quelque chose de global et de systémique qui touche toutes les formes de mobilisation de masse. Ce n’est pas seulement que les manifestations pacifiques sont inefficaces, mais que, de fait, les opposants à ces mouvements sont devenus plus efficaces pour les vaincre en général”.
Les épisodes de contestation réformistes (qui ne relèvent pas de revendications maximalistes, comme les mouvements démocratiques), comprenant les campagnes pour les salaires et le travail, les mouvements environnementaux, les mouvements pour la justice raciale, l’expansion des droits civiques, les droits des femmes… n’ont cessé de subir des revers et des défaites au cours des deux dernières décennies, et ont même diminué leur capacité à obtenir des concessions significatives, à l’image de la contestation de la réforme des retraites en France ou des mouvements écologiques, plus écrasés que jamais. Et ce alors que ces techniques de mobilisation sont plus utilisées que jamais.
Selon la littérature, ce qui permet aux mouvements populaires de réussir repose sur une participation large et diversifiée, c’est-à-dire transversale à l’ensemble de la société, transcendant les clivages raciaux, les clivages de classe, les clivages urbains-ruraux, les clivages partisans… Et notamment quand ils suscitent le soutien de personnes très différentes les unes des autres. “Le principal défi pour les mouvements de masse qui réclament un changement pour étendre la démocratie consiste bien souvent à disloquer les piliers des soutiens autocratiques comme l’armée ou les fonctionnaires. L’enjeu, pour les mouvements démocratiques, consiste à retourner la répression à l’encontre de la population en la dénonçant pour modifier l’opinion générale ». Enfin, les mouvements qui réussissent enchaînent bien souvent les tactiques plutôt que de reposer sur une technique d’opposition unique, afin de démultiplier les formes de pression.
La répression s’est mise à niveau
Mais l’autocratie a appris de ses erreurs. Elle a adapté en retour ses tactiques pour saper les quatre voies par lesquelles les mouvements démocratiques l’emportent. “La première consiste à s’assurer que personne ne fasse défection. La deuxième consiste à dominer l’écosystème de l’information et à remporter la guerre de l’information. La troisième consiste à recourir à la répression sélective de manière à rendre très difficile pour les mouvements d’exploiter les moments d’intense brutalité. Et la quatrième consiste à perfectionner l’art de diviser pour mieux régner”. Pour que l’armée ou la police ne fasse pas défection, les autorités ont amélioré la formation des forces de sécurité. La corruption et le financement permet de s’attacher des soutiens plus indéfectibles. Les forces de sécurité sont également plus fragmentées, afin qu’une défection de l’une d’entre elles, n’implique pas les autres. Enfin, il s’agit également de faire varier la répression pour qu’une unité de sécurité ne devienne pas une cible de mouvements populaires par rapport aux autres. Les purges et les répressions des personnes déloyales ou suspectes sont devenues plus continues et violentes. “L’ensemble de ces techniques a rendu plus difficile pour les mouvements civiques de provoquer la défection des forces de sécurité, et cette tendance s’est accentuée au fil du temps”.
La seconde adaptation clé a consisté à gagner la guerre de l’information, notamment en dominant les écosystèmes de l’information. “Inonder la zone de rumeurs, de désinformation et de propagande, dont certaines peuvent être créées et testées par différents outils d’IA, en fait partie. Il en va de même pour la coupure d’Internet aux moments opportuns, puis sa réouverture au moment opportun”.
Le troisième volet de la panoplie consiste à appliquer une répression sélective, consistant à viser des individus plutôt que les mouvements pour des crimes graves qui peuvent sembler décorrélé des manifestations, en les accusant de terrorisme ou de préparation de coup d’Etat. ”La guerre juridique est un autre outil administratif clé”.
Le quatrième volet consiste à diviser pour mieux régner. En encourageant la mobilisation loyaliste, en induisant des divisions dans les mouvements, en les infiltrant pour les radicaliser, en les poussant à des actions violentes pour générer des reflux d’opinion…
Comment utiliser l’IA pour gagner ?
Dans la montée de l’adaptation des techniques pour défaire leurs opposants, la technologie joue un rôle, estime Erica Chenoweth. Jusqu’à présent, les mouvements civiques ont plutôt eu tendance à s’approprier et à utiliser, souvent de manière très innovantes, les technologies à leur avantage, par exemple à l’heure de l’arrivée d’internet, qui a très tôt été utilisé pour s’organiser et se mobiliser. Or, aujourd’hui, les mouvements civiques sont bien plus prudents et sceptiques à utiliser l’IA, contrairement aux régimes autocratiques. Pourtant, l’un des principaux problèmes des mouvements civiques consiste à “cerner leur environnement opérationnel”, c’est-à-dire de savoir qui est connecté à qui, qui les soutient ou pourrait les soutenir, sous quelles conditions ? Où sont les vulnérabilités du mouvement ? Réfléchir de manière créative à ces questions et enjeux, aux tactiques à déployer pourrait pourtant être un atout majeur pour que les mouvements démocratiques réussissent.
Les mouvements démocratiques passent bien plus de temps à sensibiliser et communiquer qu’à faire de la stratégie, rappelle la chercheuse. Et c’est là deux enjeux où les IA pourraient aider, estime-t-elle. En 2018 par exemple, lors des élections municipales russe, un algorithme a permis de contrôler les images de vidéosurveillance des bureaux de vote pour détecter des irrégularités permettant de dégager les séquences où des bulletins préremplis avaient été introduits dans les urnes. Ce qui aurait demandé un contrôle militant épuisant a pu être accompli très simplement. Autre exemple avec les applications BuyCat, BoyCott ou NoThanks, qui sont des applications de boycott de produits, permettant aux gens de participer très facilement à des actions (des applications puissantes, mais parfois peu transparentes sur leurs méthodes, expliquait Le Monde). Pour Chenoweth, les techniques qui fonctionnent doivent être mieux documentées et partagées pour qu’elles puissent servir à d’autres. Certains groupes proposent d’ailleurs déjà des formations sur l’utilisation de l’IA pour l’action militante, comme c’est le cas de Canvas, de Social Movement Technologies et du Cooperative Impact Lab.
Le Non Violent Action Lab a d’ailleurs publié un rapport sur le sujet : Comment l’IA peut-elle venir aider les mouvements démocratiques ? Pour Chenoweth, il est urgent d’évaluer si les outils d’IA facilitent ou compliquent réellement le succès des mouvements démocratiques. Encore faudrait-il que les mouvements démocratiques puissent accéder à des outils d’IA qui ne partagent pas leurs données avec des plateformes et avec les autorités. L’autre enjeu consiste à construire des corpus adaptés pour aider les mouvements à résister. Les corpus de l’IA s’appuient sur des données des 125 dernières années, alors que l’on sait déjà que ce qui fonctionnait il y a 60 ans ne fonctionne plus nécessairement.
Pourtant, estime Chenoweth, les mouvements populaires ont besoin d’outils pour démêler des processus délibératifs souvent complexes, et l’IA devrait pouvoir les y aider. “Aussi imparfait qu’ait été notre projet démocratique, nous le regretterons certainement lorsqu’il prendra fin”, conclut la politologue. En invitant les mouvements civiques à poser la question de l’utilisation de l’IA a leur profit, plutôt que de la rejetter d’emblée comme l’instrument de l’autoritarisme, elle invite à faire un pas de côté pour trouver des modalités pour refaire gagner les luttes sociales.
On lui suggérera tout de même de regarder du côté des projets que Audrey Tang mène à Taïwan avec le Collective intelligence for collective progress, comme ses « assemblées d’alignement » qui mobilise l’IA pour garantir une participation équitable et une écoute active de toutes les opinions. Comme Tang le défend dans son manifeste, Plurality, l’IA pourrait être une technologie d’extension du débat démocratique pour mieux organiser la complexité. Tang parle d’ailleurs de broad listening (« écoute élargie ») pour l’opposer au broadcasting, la diffusion de un vers tous. Une méthode mobilisée par un jeune ingénieur au poste de gouverneur de Tokyo, Takahiro Anno, qui a bénéficié d’une audience surprenante, sans néanmoins l’emporter. Son adversaire a depuis mobilisé la méthode pour lancer une consultation, Tokyo 2050.
Le soulèvement contre l’obsolescence programmée est bien engagé, estime Geert Lovink (blog) dans la conclusion d’un petit livre sur l’internet des choses mortes (The Internet of Dead things, édité par Benjamin Gaulon, Institute of Network Cultures, 2025, non traduit). Le petit livre, qui rassemble notamment des contributions d’artistes de l’Institut de l’internet des choses mortes, qui ont œuvré à développer un système d’exploitation pour Minitel, met en perspective l’hybridation fonctionnelle d
Le soulèvement contre l’obsolescence programmée est bien engagé, estime Geert Lovink (blog) dans la conclusion d’un petit livre sur l’internet des choses mortes (The Internet of Dead things, édité par Benjamin Gaulon, Institute of Network Cultures, 2025, non traduit). Le petit livre, qui rassemble notamment des contributions d’artistes de l’Institut de l’internet des choses mortes, qui ont œuvré à développer un système d’exploitation pour Minitel, met en perspective l’hybridation fonctionnelle des technologies. Pour Lovink, l’avenir n’est pas seulement dans la réduction de la consommation et dans le recyclage, mais dans l’intégration à grande échelle de l’ancien dans le nouveau. Hybrider les technologies défuntes et les intégrer dans nos quotidiens est tout l’enjeu du monde à venir, dans une forme de permaculture du calcul. Arrêtons de déplorer l’appropriation du logiciel libre et ouvert par le capitalisme vautour, explique Geert Lovink. La réutilisation et la réparation nous conduisent désormais à refuser la technologie qu’on nous impose. Les mouvements alternatifs doivent désormais “refuser d’être neutralisés, écrasés et réduits au silence”, refuser de se faire réapproprier. Nous devons réclamer la tech – c’était déjà la conclusion de son précédent livre, Stuck on the platform (2022, voir notre critique) -, comme nous y invitent les hackers italiens, inspiré par le mouvement britannique des années 90, qui réclamait déjà la rue, pour reconquérir cet espace public contre la surveillance policière et la voiture.
“Reclaim the Tech » va plus loin en affirmant que « Nous sommes la technologie », explique Lovink. Cela signifie que la technologie n’est plus un phénomène passager, imposé : la technologie est en nous, nous la portons à fleur de peau ou sous la peau. Elle est intime, comme les applications menstruelles de la « femtech », décrites par Morgane Billuart dans son livre Cycles. Les ruines industrielles tiennent d’un faux romantisme, clame Lovink. Nous voulons un futur hybrid-punk, pas cypherpunk ! “La culture numérique actuelle est stagnante, elle n’est pas une échappatoire. Elle manque de direction et de destin. La volonté d’organisation est absente maintenant que même les réseaux à faible engagement ont été supplantés par les plateformes. L’esprit du temps est régressif, à l’opposé de l’accélérationnisme. Il n’y a pas d’objectif vers lequel tendre, quelle que soit la vitesse. Il n’y a pas non plus de dissolution du soi dans le virtuel. Le cloud est le nouveau ringard. Rien n’est plus ennuyeux que le virtuel pur. Rien n’est plus corporate que le centre de données. Ce que nous vivons est une succession interminable de courtes poussées d’extase orgasmique, suivies de longues périodes d’épuisement.”
Ce rythme culturel dominant a eu un effet dévastateur sur la recherche et la mise en œuvre d’alternatives durables, estime Lovink. L’optimisation prédictive a effacé l’énergie intérieure de révolte que nous portons en nous. Il ne reste que des explosions de colère, entraînant des mouvements sociaux erratiques – une dynamique alimentée par une utilisation des réseaux sociaux à courte durée d’attention. La question d’aujourd’hui est de savoir comment rendre la (post)colonialité visible dans la technologie et le design. Nous la voyons apparaître non seulement dans le cas des matières premières, mais aussi dans le contexte du « colonialisme des données ».
Mais, s’il est essentiel d’exiger la décolonisation de tout, estime Lovink, la technologie n’abandonnera pas volontairement sa domination du Nouveau au profit de la « créolisation technologique ».
La décolonisation de la technologie n’est pas un enjeu parmi d’autres : elle touche au cœur même de la production de valeur actuelle. Prenons garde de ne pas parler au nom des autres, mais agissons ensemble, créons des cultures de « vivre ensemble hybride » qui surmontent les nouveaux cloisonnements géopolitiques et autres formes subliminales et explicites de techno-apartheid. La violence technologique actuelle va des biais algorithmiques et de l’exclusion à la destruction militaire bien réelle de terres, de villes et de vies. Les alternatives, les designs innovants, les feuilles de route et les stratégies de sortie ne manquent pas. L’exode ne sera pas télévisé. Le monde ne peut attendre la mise en œuvre des principes de prévention des données. Arrêtons définitivement les flux de données !, clame Lovink.
La « confidentialité » des données s’étant révélée être un gouffre juridique impossible à garantir, la prochaine option sera des mécanismes intégrés, des filtres empêchant les données de quitter les appareils et les applications. Cela inclut une interdiction mondiale de la vente de données, estime-t-il. Les alternatives ne sont rien si elles ne sont pas locales. Apparaissant après la révolution, les « magasins de proximité » qui rendent les technologies aux gens ne se contenteront plus de réparer, mais nous permettront de vivre avec nos déchets, de les rendre visibles, à nouveau fonctionnels, tout comme on rend à nouveau fonctionnel le Minitel en changeant son objet, sa destination, ses modalités.
Le soulèvement contre l’obsolescence programmée est bien engagé, estime Geert Lovink (blog) dans la conclusion d’un petit livre sur l’internet des choses mortes (The Internet of Dead things, édité par Benjamin Gaulon, Institute of Network Cultures, 2025, non traduit). Le petit livre, qui rassemble notamment des contributions d’artistes de l’Institut de l’internet des choses mortes, qui ont œuvré à développer un système d’exploitation pour Minitel, met en perspective l’hybridation fonctionnelle d
Le soulèvement contre l’obsolescence programmée est bien engagé, estime Geert Lovink (blog) dans la conclusion d’un petit livre sur l’internet des choses mortes (The Internet of Dead things, édité par Benjamin Gaulon, Institute of Network Cultures, 2025, non traduit). Le petit livre, qui rassemble notamment des contributions d’artistes de l’Institut de l’internet des choses mortes, qui ont œuvré à développer un système d’exploitation pour Minitel, met en perspective l’hybridation fonctionnelle des technologies. Pour Lovink, l’avenir n’est pas seulement dans la réduction de la consommation et dans le recyclage, mais dans l’intégration à grande échelle de l’ancien dans le nouveau. Hybrider les technologies défuntes et les intégrer dans nos quotidiens est tout l’enjeu du monde à venir, dans une forme de permaculture du calcul. Arrêtons de déplorer l’appropriation du logiciel libre et ouvert par le capitalisme vautour, explique Geert Lovink. La réutilisation et la réparation nous conduisent désormais à refuser la technologie qu’on nous impose. Les mouvements alternatifs doivent désormais “refuser d’être neutralisés, écrasés et réduits au silence”, refuser de se faire réapproprier. Nous devons réclamer la tech – c’était déjà la conclusion de son précédent livre, Stuck on the platform (2022, voir notre critique) -, comme nous y invitent les hackers italiens, inspiré par le mouvement britannique des années 90, qui réclamait déjà la rue, pour reconquérir cet espace public contre la surveillance policière et la voiture.
“Reclaim the Tech » va plus loin en affirmant que « Nous sommes la technologie », explique Lovink. Cela signifie que la technologie n’est plus un phénomène passager, imposé : la technologie est en nous, nous la portons à fleur de peau ou sous la peau. Elle est intime, comme les applications menstruelles de la « femtech », décrites par Morgane Billuart dans son livre Cycles. Les ruines industrielles tiennent d’un faux romantisme, clame Lovink. Nous voulons un futur hybrid-punk, pas cypherpunk ! “La culture numérique actuelle est stagnante, elle n’est pas une échappatoire. Elle manque de direction et de destin. La volonté d’organisation est absente maintenant que même les réseaux à faible engagement ont été supplantés par les plateformes. L’esprit du temps est régressif, à l’opposé de l’accélérationnisme. Il n’y a pas d’objectif vers lequel tendre, quelle que soit la vitesse. Il n’y a pas non plus de dissolution du soi dans le virtuel. Le cloud est le nouveau ringard. Rien n’est plus ennuyeux que le virtuel pur. Rien n’est plus corporate que le centre de données. Ce que nous vivons est une succession interminable de courtes poussées d’extase orgasmique, suivies de longues périodes d’épuisement.”
Ce rythme culturel dominant a eu un effet dévastateur sur la recherche et la mise en œuvre d’alternatives durables, estime Lovink. L’optimisation prédictive a effacé l’énergie intérieure de révolte que nous portons en nous. Il ne reste que des explosions de colère, entraînant des mouvements sociaux erratiques – une dynamique alimentée par une utilisation des réseaux sociaux à courte durée d’attention. La question d’aujourd’hui est de savoir comment rendre la (post)colonialité visible dans la technologie et le design. Nous la voyons apparaître non seulement dans le cas des matières premières, mais aussi dans le contexte du « colonialisme des données ».
Mais, s’il est essentiel d’exiger la décolonisation de tout, estime Lovink, la technologie n’abandonnera pas volontairement sa domination du Nouveau au profit de la « créolisation technologique ».
La décolonisation de la technologie n’est pas un enjeu parmi d’autres : elle touche au cœur même de la production de valeur actuelle. Prenons garde de ne pas parler au nom des autres, mais agissons ensemble, créons des cultures de « vivre ensemble hybride » qui surmontent les nouveaux cloisonnements géopolitiques et autres formes subliminales et explicites de techno-apartheid. La violence technologique actuelle va des biais algorithmiques et de l’exclusion à la destruction militaire bien réelle de terres, de villes et de vies. Les alternatives, les designs innovants, les feuilles de route et les stratégies de sortie ne manquent pas. L’exode ne sera pas télévisé. Le monde ne peut attendre la mise en œuvre des principes de prévention des données. Arrêtons définitivement les flux de données !, clame Lovink.
La « confidentialité » des données s’étant révélée être un gouffre juridique impossible à garantir, la prochaine option sera des mécanismes intégrés, des filtres empêchant les données de quitter les appareils et les applications. Cela inclut une interdiction mondiale de la vente de données, estime-t-il. Les alternatives ne sont rien si elles ne sont pas locales. Apparaissant après la révolution, les « magasins de proximité » qui rendent les technologies aux gens ne se contenteront plus de réparer, mais nous permettront de vivre avec nos déchets, de les rendre visibles, à nouveau fonctionnels, tout comme on rend à nouveau fonctionnel le Minitel en changeant son objet, sa destination, ses modalités.
Encore une réflexion stimulante de Gregory Chatonsky, qui observe deux modes de relation à l’IA générative. L’un actif-productif, l’autre passif-reproductif-mémétique. « L’infrastructure générative n’a pas d’essence unifiée ni de destination prédéterminée — elle peut être orientée vers la production comme vers la consommation. Cette indétermination constitutive des technologies génératives révèle un aspect fondamental : nous nous trouvons face à un système technique dont les usages et les implic
Encore une réflexion stimulante de Gregory Chatonsky, qui observe deux modes de relation à l’IA générative. L’un actif-productif, l’autre passif-reproductif-mémétique. « L’infrastructure générative n’a pas d’essence unifiée ni de destination prédéterminée — elle peut être orientée vers la production comme vers la consommation. Cette indétermination constitutive des technologies génératives révèle un aspect fondamental : nous nous trouvons face à un système technique dont les usages et les implications restent largement à définir ».
« L’enjeu n’est donc pas de privilégier artificiellement un mode sur l’autre, mais de comprendre comment ces deux rapports à la génération déterminent des trajectoires divergentes pour notre avenir technologique. En reconnaissant cette dualité fondamentale, nous pouvons commencer à élaborer une relation plus consciente et réfléchie aux technologies génératives, capable de dépasser aussi bien l’instrumentalisme naïf que le déterminisme technologique.
La génération n’est ni intrinsèquement productive ni intrinsèquement consommatrice — elle devient l’un ou l’autre selon le rapport existentiel que nous établissons avec elle. C’est dans cette indétermination constitutive que résident sa réponse à la finitude. »
Dans une riche et détaillée revue d’études sur la modération des plateformes du web social, Lisa Macpherson de l’association Public Knowledge démontre que cette modération n’est ni équitable ni neutre. En fait, les études ne démontrent pas qu’il y aurait une surmodération des propos conservateurs, au contraire, les contenus de droite ayant tendance à générer plus d’engagement et donc de revenus publicitaires. En fait, si certains contenus conservateurs sont plus souvent modérés, c’est parce qu’i
Dans une riche et détaillée revue d’études sur la modération des plateformes du web social, Lisa Macpherson de l’association Public Knowledge démontre que cette modération n’est ni équitable ni neutre. En fait, les études ne démontrent pas qu’il y aurait une surmodération des propos conservateurs, au contraire, les contenus de droite ayant tendance à générer plus d’engagement et donc de revenus publicitaires. En fait, si certains contenus conservateurs sont plus souvent modérés, c’est parce qu’ils enfreignent plus volontiers les règles des plateformes en colportant de la désinformation ou des propos haineux, et non du fait des biais politiques de la modération. La modération injustifiée, elle, touche surtout les communautés marginalisées (personnes racisées, minorités religieuses, femmes, LGBTQ+). Les biais de modération sont toujours déséquilibrés. Et les contenus de droite sont plus amplifiés que ceux de gauche.
En France, rapporte Next, constatant le très faible taux de modération de contenus haineux sur Facebook, le cofondateur de l’association #jesuislà et activiste pour les droits numériques Xavier Brandao porte plainte contre Meta auprès de l’Arcom au titre du DSA. En envoyant plus de 118 signalements à Meta en quatre mois pour des discours racistes avérés, l’activiste s’est rendu compte que seulement 8 commentaires avaient été supprimés.
Encore une réflexion stimulante de Gregory Chatonsky, qui observe deux modes de relation à l’IA générative. L’un actif-productif, l’autre passif-reproductif-mémétique. « L’infrastructure générative n’a pas d’essence unifiée ni de destination prédéterminée — elle peut être orientée vers la production comme vers la consommation. Cette indétermination constitutive des technologies génératives révèle un aspect fondamental : nous nous trouvons face à un système technique dont les usages et les implic
Encore une réflexion stimulante de Gregory Chatonsky, qui observe deux modes de relation à l’IA générative. L’un actif-productif, l’autre passif-reproductif-mémétique. « L’infrastructure générative n’a pas d’essence unifiée ni de destination prédéterminée — elle peut être orientée vers la production comme vers la consommation. Cette indétermination constitutive des technologies génératives révèle un aspect fondamental : nous nous trouvons face à un système technique dont les usages et les implications restent largement à définir ».
« L’enjeu n’est donc pas de privilégier artificiellement un mode sur l’autre, mais de comprendre comment ces deux rapports à la génération déterminent des trajectoires divergentes pour notre avenir technologique. En reconnaissant cette dualité fondamentale, nous pouvons commencer à élaborer une relation plus consciente et réfléchie aux technologies génératives, capable de dépasser aussi bien l’instrumentalisme naïf que le déterminisme technologique.
La génération n’est ni intrinsèquement productive ni intrinsèquement consommatrice — elle devient l’un ou l’autre selon le rapport existentiel que nous établissons avec elle. C’est dans cette indétermination constitutive que résident sa réponse à la finitude. »
Dans une riche et détaillée revue d’études sur la modération des plateformes du web social, Lisa Macpherson de l’association Public Knowledge démontre que cette modération n’est ni équitable ni neutre. En fait, les études ne démontrent pas qu’il y aurait une surmodération des propos conservateurs, au contraire, les contenus de droite ayant tendance à générer plus d’engagement et donc de revenus publicitaires. En fait, si certains contenus conservateurs sont plus souvent modérés, c’est parce qu’i
Dans une riche et détaillée revue d’études sur la modération des plateformes du web social, Lisa Macpherson de l’association Public Knowledge démontre que cette modération n’est ni équitable ni neutre. En fait, les études ne démontrent pas qu’il y aurait une surmodération des propos conservateurs, au contraire, les contenus de droite ayant tendance à générer plus d’engagement et donc de revenus publicitaires. En fait, si certains contenus conservateurs sont plus souvent modérés, c’est parce qu’ils enfreignent plus volontiers les règles des plateformes en colportant de la désinformation ou des propos haineux, et non du fait des biais politiques de la modération. La modération injustifiée, elle, touche surtout les communautés marginalisées (personnes racisées, minorités religieuses, femmes, LGBTQ+). Les biais de modération sont toujours déséquilibrés. Et les contenus de droite sont plus amplifiés que ceux de gauche.
En France, rapporte Next, constatant le très faible taux de modération de contenus haineux sur Facebook, le cofondateur de l’association #jesuislà et activiste pour les droits numériques Xavier Brandao porte plainte contre Meta auprès de l’Arcom au titre du DSA. En envoyant plus de 118 signalements à Meta en quatre mois pour des discours racistes avérés, l’activiste s’est rendu compte que seulement 8 commentaires avaient été supprimés.
“Le respect des droits fondamentaux des étrangers est un marqueur essentiel du degré de protection des droits et des libertés dans un pays”, disait très clairement le Défenseur des droits en 2016. Le rapport pointait déjà très bien nombre de dérives : atteintes aux droits constantes, exclusions du droit commun, surveillances spécifiques et invasives… Près de 10 ans plus tard, contexte politique aidant, on ne sera pas étonné que ces atteintes se soient dégradées. Les réformes législatives en cont
“Le respect des droits fondamentaux des étrangers est un marqueur essentiel du degré de protection des droits et des libertés dans un pays”, disait très clairement le Défenseur des droits en 2016. Le rapport pointait déjà très bien nombre de dérives : atteintes aux droits constantes, exclusions du droit commun, surveillances spécifiques et invasives… Près de 10 ans plus tard, contexte politique aidant, on ne sera pas étonné que ces atteintes se soient dégradées. Les réformes législatives en continue (118 textes depuis 1945, dit un bilan du Monde) n’ont pas aidé et ne cessent de dégrader non seulement le droit, mais également les services publics dédiés. Ce qu’il se passe aux Etats-Unis n’est pas une exception.
Voilà longtemps que le droit des étrangers en France est plus que malmené. Voilà longtemps que les associations et autorités indépendantes qui surveillent ses évolutions le dénoncent. Des travaux des associations comme la Cimade, à ceux des autorités indépendantes, comme le Défenseur des droits ou la Cour des comptes, en passant par les travaux de chercheurs et de journalistes, les preuves ne cessent de s’accumuler montrant l’instrumentalisation mortifère de ce qui ne devrait être pourtant qu’un droit parmi d’autres.
Couverture du livre France terre d’écueils.
Dans un petit livre simple et percutant,France, Terre d’écueils (Rue de l’échiquier, 2025, 112 pages), l’avocate Marianne Leloup-Dassonville explique, très concrètement, comment agit la maltraitance administrative à l’égard de 5,6 millions d’étrangers qui vivent en France. Marianne Leloup-Dassonville, avocate spécialisée en droit des étrangers et administratrice de l’association Droits d’urgence, nous montre depuis sa pratique les défaillances de l’administration à destination des étrangers. Une administration mise au pas, au service d’un propos politique de plus en plus déconnecté des réalités, qui concentre des pratiques mortifères et profondément dysfonctionnelles, dont nous devrions nous alarmer, car ces pratiques portent en elles des menaces pour le fonctionnement du droit et des services publics. A terme, les dysfonctionnements du droit des étrangers pourraient devenir un modèle de maltraitance à appliquer à tous les autres services publics.
Le dysfonctionnement des services publics à destination des étrangers est caractérisé par plusieurs maux, détaille Marianne Leloup-Dassonville. Ce sont d’abord des services publics indisponibles, ce sont partout des droits à minima et qui se réduisent, ce sont partout des procédures à rallonge, où aucune instruction n’est disponible dans un délai “normal”. Ce sont enfin une suspicion et une persécution systématique. L’ensemble produit un empêchement organisé qui a pour but de diminuer l’accès au droit, d’entraver la régularisation. Ce que Marianne Leloup-Dassonville dessine dans son livre, c’est que nous ne sommes pas seulement confrontés à des pratiques problématiques, mais des pratiques systémiques qui finissent par faire modèle.
Indisponibilité et lenteur systémique
France, Terre d’écueils décrit d’abord des chaînes de dysfonctionnements administratifs. Par des exemples simples et accessibles, l’avocate donne de l’épaisseur à l’absurdité qui nous saisit face à la déshumanisation des étrangers dans les parcours d’accès aux droits. Nul n’accepterait pour quiconque ce que ces services font subir aux publics auxquels ils s’adressent. L’une des pratiques les plus courantes dans ce domaine, c’est l’indisponibilité d’un service : service téléphonique qui ne répond jamais, site web de prise de rendez-vous sans proposition de rendez-vous, dépôts sans récépissés, dossier auquel il n’est pas possible d’accéder ou de mettre à jour… Autant de pratiques qui sont là pour faire patienter c’est-à-dire pour décourager… et qui nécessitent de connaître les mesures de contournements qui ne sont pas dans la procédure officielle donc, comme de documenter l’indisponibilité d’un site par la prise de capture d’écran répétée, permettant de faire un recours administratif pour obliger le service à proposer un rendez-vous à un requérant.
Toutes les procédures que l’avocate décrit sont interminables. Toutes oeuvrent à décourager comme si ce découragement était le seul moyen pour désengorger des services partout incapables de répondre à l’afflux des demandes. Si tout est kafkaïen dans ce qui est décrit ici, on est surtout marqué par la terrible lenteur des procédures, rallongées de recours eux-mêmes interminables. Par exemple, l’Ofpra (Office Français de Protection des Réfugiés et Apatrides) statue en moyenne sur une demande d’asile en 4 mois, mais souvent par un refus. Pour une procédure de recours, la CNDA (Cour nationale du droit d’asile) met en moyenne 12 à 24 mois à réétudier un dossier. Quand un ressortissant étranger obtient le statut de réfugié, il devrait obtenir un titre de séjour dans les 3 mois. En réalité, les cartes de séjour et les actes d’état civils mettent de longs mois à être produits (douze mois en moyenne) ce qui prive les étrangers de nombreux droits sociaux, comme de pouvoir s’inscrire à France Travail ou de bénéficier des allocations familiales, du droit du travail. Même constat à l’AES (admission exceptionnelle au séjour). Depuis 2023, la demande d’AES se fait en ligne et consiste à enregistrer quelques documents pour amorcer la procédure. Mais les préfectures ne font de retour que 6 mois après le dépôt de la demande. Un rendez-vous n’est proposé bien souvent qu’encore une année plus tard, soit en moyenne 18 mois entre la demande initiale et le premier rendez-vous, et ce uniquement pour déposer un dossier. L’instruction qui suit, elle, prend entre 18 et 24 mois. Il faut donc compter à minima 3 à 4 années pour une demande de régularisation ! Sans compter qu’en cas de refus (ce qui est plutôt majoritairement le cas), il faut ajouter la durée de la procédure de recours au tribunal administratif. Même chose en cas de refus de visa injustifié, qui nécessite plus de 2 ans de procédure pour obtenir concrètement le papier permettant de revenir en France.
C’est un peu comme s’il fallait patienter des années pour obtenir un rendez-vous chez un dermatologue pour vérifier un grain de beauté inquiétant ou plusieurs mois pour obtenir des papiers d’identité. Dans le domaine du droit des étrangers, la dégradation des services publics semble seulement plus prononcée qu’ailleurs.
Droits minimaux et décisions discrétionnaires
Le dysfonctionnement que décrit l’avocate n’est pas qu’administratif, il est également juridique. Dans le domaine de la demande d’asile par exemple, il n’existe pas de procédure d’appel, qui est pourtant une garantie simple et forte d’une justice équitable. Les demandeurs ayant été refusés peuvent demander un réexamen qui a souvent lieu dans le cadre de procédures « accélérées ». Mais cette accélération là ne consiste pas à aller plus vite, elle signifie seulement que la décision sera prise par un juge unique, et donc, potentiellement, moins équitable.
L’admission exceptionnelle au séjour (AES), autre possibilité pour obtenir une naturalisation, nécessite elle de faire une demande à la préfecture de son domicile. Même si cette admission est bornée de conditions concrètes très lourdes (promesse d’embauche, présence sur le territoire depuis 3 ans, bulletins de salaires sur au moins 2 ans…), le préfet exerce ici une compétence discrétionnaire, puisqu’il évalue seul les demandes. « En matière de naturalisation, l’administration a un très large pouvoir d’appréciation », souligne l’avocate. Même constat quant aux demandes de naturalisation, tout aussi compliquées que les autres demandes. L’entretien de naturalisation par exemple, qu’avait étudié le sociologue Abdellali Hajjat dans son livre, Les frontières de l’identité nationale, a tout d’une sinécure. Il consiste en un entretien discrétionnaire, sans procès verbal ni enregistrement, sans programme pour se préparer à y répondre. Ce n’est pas qu’un test de culture général d’ailleurs auquel nombre de Français auraient du mal à répondre, puisque de nombreuses questions ne relèvent pas d’un QCM, mais sont appréciatives. Il n’y a même pas de score minimal à obtenir, comme ce peut-être le cas dans d’autres pays, comme le Royaume-Uni. Vous pouvez répondre juste aux questions… et être refusé.
Suspicion, persécution et empêchement systématiques
Le fait de chercher à empêcher les demandeurs d’asile d’accéder à un travail (en janvier 2024, une loi anti-immigration, une de plus, est même venue interdire à ceux qui ne disposent pas de titre de séjour d’obtenir un statut d’entrepreneur individuel) créé en fait une surcouche de dysfonctionnements et de coûts qui sont non seulement contre-productifs, mais surtout rendent la vie impossible aux étrangers présents sur le territoire. Et ce alors que 90% des personnes en situation irrégulière travaillent quand même, comme le souligne France Stratégies dans son rapport sur l’impact de l’immigration sur le marché du travail. En fait, en les empêchant de travailler, nous produisons une surcouche de violences : pour travailler, les sans-papiers produisent les titres de séjour d’un tiers, à qui seront adressés les bulletins de salaires. Tiers qui prélèvent une commission de 30 à 50% sur ces revenus, comme le montrait l’excellent film de Boris Lokjine, L’histoire de Souleymane.
Parce que le lien de paternité ou de maternité créé un droit pour l’enfant et pour le compagnon ou la compagne, la suspicion de mariage blanc est devenue systématique quand elle était avant un signe d’intégration, comme le rappelait le rapport du mouvement des amoureux aux ban publics. Enquêtes intrusives, abusives, surveillance policière, maires qui s’opposent aux unions (sans en avoir le droit)… Alors qu’on ne comptait que 345 mariages annulés en 2009 (soit moins de 0,5% des unions mixtes) et une trentaine de condamnations pénales par an, 100% des couples mixtes subissent des discriminations administratives. Le soupçon mariage blanc permet surtout de masquer les défaillances et le racisme de l’administration française. Ici comme ailleurs, le soupçon de fraude permet de faire croire à tous que ce sont les individus qui sont coupables des lacunes de l’administration française.
Une politique du non accueil perdu dans ses amalgames
France, terre d’écueils, nous montre le parcours du combattant que représente partout la demande à acquérir la nationalité. L’ouvrage nous montre ce que la France impose à ceux qui souhaitent y vivre, en notre nom. Une politique de non accueil qui a de quoi faire honte.
Ces dérives juridiques et administratives sont nées de l’amalgame sans cesse renouvelé à nous faire confondre immigration et délinquance. C’est ce que symbolise aujourd’hui le délires sur les OQTF. L’OQTF est une décision administrative prise par les préfectures à l’encontre d’un étranger en situation irrégulière, lui imposant un départ avec ou sans délai. Or, contrairement à ce que l’on ne cesse de nous faire croire, les OQTF ne concernent pas uniquement des individus dangereux, bien au contraire. La grande majorité des personnes frappées par des OQTF ne sont coupables d’aucun délit, rappelle Marianne Leloup-Dassonville. Elles sont d’abord un objectif chiffré. Les préfectures les démultiplent alors qu’elles sont très souvent annulées par les tribunaux. La France en émet plus de 100 000 par an et en exécute moins de 7000. Elle émet 30% des OQTF de toute l’Europe. Les services préfectoraux dédiés sont surchargés et commettent des “erreurs de droit” comme le dit très pudiquement la Cour des comptes dans son rapport sur la lutte contre l’immigration irrégulière. Le contentieux des étrangers représente 41% des affaires des tribunaux administratifs en 2023 (contre 30% en 2016) et 55% des affaires des cours d’appel, comme le rappelait Mediapart. La plupart des OQTF concernent des ressortissants étrangers qui n’ont jamais commis d’infraction (ou des infractions mineures et anciennes). Nombre d’entre elles sont annulées, nombre d’autres ne peuvent pas être exécutées. Peut-on sortir de cette spirale inutile, se demande l’avocate ?
Nous misons désormais bien plus sur une fausse sécurité que sur la sûreté. La sûreté, rappelle l’avocate, c’est la garantie que les libertés individuelles soient respectées, contre une arrestation, un emprisonnement ou une condamnation arbitraire. La sûreté nous garantit une administration équitable et juste. C’est elle que nous perdons en nous enfermant dans un délire sécuritaire qui a perdu contact avec la réalité. Les témoignages que livre Marianne Leloup-Dassonville montrent des personnes plutôt privilégiées, traumatisées par leurs rapports à l’administration française. Les étrangers sont partout assimilés à des délinquants comme les bénéficiaires de droits sociaux sont assimilés à des fraudeurs.
A lire le court ouvrage de Marianne Leloup-Dassonville, on se dit que nous devrions nous doter d’un observatoire de la maltraitance administrative pour éviter qu’elle ne progresse et qu’elle ne contamine toutes les autres administrations. Nous devons réaffirmer que l’administration ne peut se substituer nulle part à la justice, car c’est assurément par ce glissement là qu’on entraîne tous les autres.
Hubert Guillaud
PS : Au Royaume-Uni, le ministère de l’intérieur souhaite introduire deux outils d’IA dans les processus de décisions de demande d’asile d’après une étude pilote : une pour résumer les informations des dossiers, l’autre pour trouver des informations sur les pays d’origine des demandeurs d’asile. Une façon de renforcer là-bas, la boîte noire des décisions, au prétexte d’améliorer « la vitesse » de décision plutôt que leur qualité, comme le souligne une étude critique. Comme quoi, on peut toujours imaginer pire pour encore dégrader ce qui l’est déjà considérablement.
MAJ du 23/05/2025 : L’extension des prérogatives de l’administration au détriment du droit, permettant de contourner la justice sur l’application de mesures restreignant les libertés individuelles, à un nom, nous apprend Blast, l’« administrativisation », et permet des sanctions sans garanties de justice et d’appliquer des sanctions sans preuves.
“Le respect des droits fondamentaux des étrangers est un marqueur essentiel du degré de protection des droits et des libertés dans un pays”, disait très clairement le Défenseur des droits en 2016. Le rapport pointait déjà très bien nombre de dérives : atteintes aux droits constantes, exclusions du droit commun, surveillances spécifiques et invasives… Près de 10 ans plus tard, contexte politique aidant, on ne sera pas étonné que ces atteintes se soient dégradées. Les réformes législatives en cont
“Le respect des droits fondamentaux des étrangers est un marqueur essentiel du degré de protection des droits et des libertés dans un pays”, disait très clairement le Défenseur des droits en 2016. Le rapport pointait déjà très bien nombre de dérives : atteintes aux droits constantes, exclusions du droit commun, surveillances spécifiques et invasives… Près de 10 ans plus tard, contexte politique aidant, on ne sera pas étonné que ces atteintes se soient dégradées. Les réformes législatives en continue (118 textes depuis 1945, dit un bilan du Monde) n’ont pas aidé et ne cessent de dégrader non seulement le droit, mais également les services publics dédiés. Ce qu’il se passe aux Etats-Unis n’est pas une exception.
Voilà longtemps que le droit des étrangers en France est plus que malmené. Voilà longtemps que les associations et autorités indépendantes qui surveillent ses évolutions le dénoncent. Des travaux des associations comme la Cimade, à ceux des autorités indépendantes, comme le Défenseur des droits ou la Cour des comptes, en passant par les travaux de chercheurs et de journalistes, les preuves ne cessent de s’accumuler montrant l’instrumentalisation mortifère de ce qui ne devrait être pourtant qu’un droit parmi d’autres.
Couverture du livre France terre d’écueils.
Dans un petit livre simple et percutant,France, Terre d’écueils (Rue de l’échiquier, 2025, 112 pages), l’avocate Marianne Leloup-Dassonville explique, très concrètement, comment agit la maltraitance administrative à l’égard de 5,6 millions d’étrangers qui vivent en France. Marianne Leloup-Dassonville, avocate spécialisée en droit des étrangers et administratrice de l’association Droits d’urgence, nous montre depuis sa pratique les défaillances de l’administration à destination des étrangers. Une administration mise au pas, au service d’un propos politique de plus en plus déconnecté des réalités, qui concentre des pratiques mortifères et profondément dysfonctionnelles, dont nous devrions nous alarmer, car ces pratiques portent en elles des menaces pour le fonctionnement du droit et des services publics. A terme, les dysfonctionnements du droit des étrangers pourraient devenir un modèle de maltraitance à appliquer à tous les autres services publics.
Le dysfonctionnement des services publics à destination des étrangers est caractérisé par plusieurs maux, détaille Marianne Leloup-Dassonville. Ce sont d’abord des services publics indisponibles, ce sont partout des droits à minima et qui se réduisent, ce sont partout des procédures à rallonge, où aucune instruction n’est disponible dans un délai “normal”. Ce sont enfin une suspicion et une persécution systématique. L’ensemble produit un empêchement organisé qui a pour but de diminuer l’accès au droit, d’entraver la régularisation. Ce que Marianne Leloup-Dassonville dessine dans son livre, c’est que nous ne sommes pas seulement confrontés à des pratiques problématiques, mais des pratiques systémiques qui finissent par faire modèle.
Indisponibilité et lenteur systémique
France, Terre d’écueils décrit d’abord des chaînes de dysfonctionnements administratifs. Par des exemples simples et accessibles, l’avocate donne de l’épaisseur à l’absurdité qui nous saisit face à la déshumanisation des étrangers dans les parcours d’accès aux droits. Nul n’accepterait pour quiconque ce que ces services font subir aux publics auxquels ils s’adressent. L’une des pratiques les plus courantes dans ce domaine, c’est l’indisponibilité d’un service : service téléphonique qui ne répond jamais, site web de prise de rendez-vous sans proposition de rendez-vous, dépôts sans récépissés, dossier auquel il n’est pas possible d’accéder ou de mettre à jour… Autant de pratiques qui sont là pour faire patienter c’est-à-dire pour décourager… et qui nécessitent de connaître les mesures de contournements qui ne sont pas dans la procédure officielle donc, comme de documenter l’indisponibilité d’un site par la prise de capture d’écran répétée, permettant de faire un recours administratif pour obliger le service à proposer un rendez-vous à un requérant.
Toutes les procédures que l’avocate décrit sont interminables. Toutes oeuvrent à décourager comme si ce découragement était le seul moyen pour désengorger des services partout incapables de répondre à l’afflux des demandes. Si tout est kafkaïen dans ce qui est décrit ici, on est surtout marqué par la terrible lenteur des procédures, rallongées de recours eux-mêmes interminables. Par exemple, l’Ofpra (Office Français de Protection des Réfugiés et Apatrides) statue en moyenne sur une demande d’asile en 4 mois, mais souvent par un refus. Pour une procédure de recours, la CNDA (Cour nationale du droit d’asile) met en moyenne 12 à 24 mois à réétudier un dossier. Quand un ressortissant étranger obtient le statut de réfugié, il devrait obtenir un titre de séjour dans les 3 mois. En réalité, les cartes de séjour et les actes d’état civils mettent de longs mois à être produits (douze mois en moyenne) ce qui prive les étrangers de nombreux droits sociaux, comme de pouvoir s’inscrire à France Travail ou de bénéficier des allocations familiales, du droit du travail. Même constat à l’AES (admission exceptionnelle au séjour). Depuis 2023, la demande d’AES se fait en ligne et consiste à enregistrer quelques documents pour amorcer la procédure. Mais les préfectures ne font de retour que 6 mois après le dépôt de la demande. Un rendez-vous n’est proposé bien souvent qu’encore une année plus tard, soit en moyenne 18 mois entre la demande initiale et le premier rendez-vous, et ce uniquement pour déposer un dossier. L’instruction qui suit, elle, prend entre 18 et 24 mois. Il faut donc compter à minima 3 à 4 années pour une demande de régularisation ! Sans compter qu’en cas de refus (ce qui est plutôt majoritairement le cas), il faut ajouter la durée de la procédure de recours au tribunal administratif. Même chose en cas de refus de visa injustifié, qui nécessite plus de 2 ans de procédure pour obtenir concrètement le papier permettant de revenir en France.
C’est un peu comme s’il fallait patienter des années pour obtenir un rendez-vous chez un dermatologue pour vérifier un grain de beauté inquiétant ou plusieurs mois pour obtenir des papiers d’identité. Dans le domaine du droit des étrangers, la dégradation des services publics semble seulement plus prononcée qu’ailleurs.
Droits minimaux et décisions discrétionnaires
Le dysfonctionnement que décrit l’avocate n’est pas qu’administratif, il est également juridique. Dans le domaine de la demande d’asile par exemple, il n’existe pas de procédure d’appel, qui est pourtant une garantie simple et forte d’une justice équitable. Les demandeurs ayant été refusés peuvent demander un réexamen qui a souvent lieu dans le cadre de procédures « accélérées ». Mais cette accélération là ne consiste pas à aller plus vite, elle signifie seulement que la décision sera prise par un juge unique, et donc, potentiellement, moins équitable.
L’admission exceptionnelle au séjour (AES), autre possibilité pour obtenir une naturalisation, nécessite elle de faire une demande à la préfecture de son domicile. Même si cette admission est bornée de conditions concrètes très lourdes (promesse d’embauche, présence sur le territoire depuis 3 ans, bulletins de salaires sur au moins 2 ans…), le préfet exerce ici une compétence discrétionnaire, puisqu’il évalue seul les demandes. « En matière de naturalisation, l’administration a un très large pouvoir d’appréciation », souligne l’avocate. Même constat quant aux demandes de naturalisation, tout aussi compliquées que les autres demandes. L’entretien de naturalisation par exemple, qu’avait étudié le sociologue Abdellali Hajjat dans son livre, Les frontières de l’identité nationale, a tout d’une sinécure. Il consiste en un entretien discrétionnaire, sans procès verbal ni enregistrement, sans programme pour se préparer à y répondre. Ce n’est pas qu’un test de culture général d’ailleurs auquel nombre de Français auraient du mal à répondre, puisque de nombreuses questions ne relèvent pas d’un QCM, mais sont appréciatives. Il n’y a même pas de score minimal à obtenir, comme ce peut-être le cas dans d’autres pays, comme le Royaume-Uni. Vous pouvez répondre juste aux questions… et être refusé.
Suspicion, persécution et empêchement systématiques
Le fait de chercher à empêcher les demandeurs d’asile d’accéder à un travail (en janvier 2024, une loi anti-immigration, une de plus, est même venue interdire à ceux qui ne disposent pas de titre de séjour d’obtenir un statut d’entrepreneur individuel) créé en fait une surcouche de dysfonctionnements et de coûts qui sont non seulement contre-productifs, mais surtout rendent la vie impossible aux étrangers présents sur le territoire. Et ce alors que 90% des personnes en situation irrégulière travaillent quand même, comme le souligne France Stratégies dans son rapport sur l’impact de l’immigration sur le marché du travail. En fait, en les empêchant de travailler, nous produisons une surcouche de violences : pour travailler, les sans-papiers produisent les titres de séjour d’un tiers, à qui seront adressés les bulletins de salaires. Tiers qui prélèvent une commission de 30 à 50% sur ces revenus, comme le montrait l’excellent film de Boris Lokjine, L’histoire de Souleymane.
Parce que le lien de paternité ou de maternité créé un droit pour l’enfant et pour le compagnon ou la compagne, la suspicion de mariage blanc est devenue systématique quand elle était avant un signe d’intégration, comme le rappelait le rapport du mouvement des amoureux aux ban publics. Enquêtes intrusives, abusives, surveillance policière, maires qui s’opposent aux unions (sans en avoir le droit)… Alors qu’on ne comptait que 345 mariages annulés en 2009 (soit moins de 0,5% des unions mixtes) et une trentaine de condamnations pénales par an, 100% des couples mixtes subissent des discriminations administratives. Le soupçon mariage blanc permet surtout de masquer les défaillances et le racisme de l’administration française. Ici comme ailleurs, le soupçon de fraude permet de faire croire à tous que ce sont les individus qui sont coupables des lacunes de l’administration française.
Une politique du non accueil perdu dans ses amalgames
France, terre d’écueils, nous montre le parcours du combattant que représente partout la demande à acquérir la nationalité. L’ouvrage nous montre ce que la France impose à ceux qui souhaitent y vivre, en notre nom. Une politique de non accueil qui a de quoi faire honte.
Ces dérives juridiques et administratives sont nées de l’amalgame sans cesse renouvelé à nous faire confondre immigration et délinquance. C’est ce que symbolise aujourd’hui le délires sur les OQTF. L’OQTF est une décision administrative prise par les préfectures à l’encontre d’un étranger en situation irrégulière, lui imposant un départ avec ou sans délai. Or, contrairement à ce que l’on ne cesse de nous faire croire, les OQTF ne concernent pas uniquement des individus dangereux, bien au contraire. La grande majorité des personnes frappées par des OQTF ne sont coupables d’aucun délit, rappelle Marianne Leloup-Dassonville. Elles sont d’abord un objectif chiffré. Les préfectures les démultiplent alors qu’elles sont très souvent annulées par les tribunaux. La France en émet plus de 100 000 par an et en exécute moins de 7000. Elle émet 30% des OQTF de toute l’Europe. Les services préfectoraux dédiés sont surchargés et commettent des “erreurs de droit” comme le dit très pudiquement la Cour des comptes dans son rapport sur la lutte contre l’immigration irrégulière. Le contentieux des étrangers représente 41% des affaires des tribunaux administratifs en 2023 (contre 30% en 2016) et 55% des affaires des cours d’appel, comme le rappelait Mediapart. La plupart des OQTF concernent des ressortissants étrangers qui n’ont jamais commis d’infraction (ou des infractions mineures et anciennes). Nombre d’entre elles sont annulées, nombre d’autres ne peuvent pas être exécutées. Peut-on sortir de cette spirale inutile, se demande l’avocate ?
Nous misons désormais bien plus sur une fausse sécurité que sur la sûreté. La sûreté, rappelle l’avocate, c’est la garantie que les libertés individuelles soient respectées, contre une arrestation, un emprisonnement ou une condamnation arbitraire. La sûreté nous garantit une administration équitable et juste. C’est elle que nous perdons en nous enfermant dans un délire sécuritaire qui a perdu contact avec la réalité. Les témoignages que livre Marianne Leloup-Dassonville montrent des personnes plutôt privilégiées, traumatisées par leurs rapports à l’administration française. Les étrangers sont partout assimilés à des délinquants comme les bénéficiaires de droits sociaux sont assimilés à des fraudeurs.
A lire le court ouvrage de Marianne Leloup-Dassonville, on se dit que nous devrions nous doter d’un observatoire de la maltraitance administrative pour éviter qu’elle ne progresse et qu’elle ne contamine toutes les autres administrations. Nous devons réaffirmer que l’administration ne peut se substituer nulle part à la justice, car c’est assurément par ce glissement là qu’on entraîne tous les autres.
Hubert Guillaud
PS : Au Royaume-Uni, le ministère de l’intérieur souhaite introduire deux outils d’IA dans les processus de décisions de demande d’asile d’après une étude pilote : une pour résumer les informations des dossiers, l’autre pour trouver des informations sur les pays d’origine des demandeurs d’asile. Une façon de renforcer là-bas, la boîte noire des décisions, au prétexte d’améliorer « la vitesse » de décision plutôt que leur qualité, comme le souligne une étude critique. Comme quoi, on peut toujours imaginer pire pour encore dégrader ce qui l’est déjà considérablement.
MAJ du 23/05/2025 : L’extension des prérogatives de l’administration au détriment du droit, permettant de contourner la justice sur l’application de mesures restreignant les libertés individuelles, à un nom, nous apprend Blast, l’« administrativisation », et permet des sanctions sans garanties de justice et d’appliquer des sanctions sans preuves.
Pour Tech Policy Press, Victoire Rio de What to Fix estime qu’il faut réguler les programmes de monétisation de contenus que proposent désormais toutes les plateformes. Facebook a plus de 3,8 millions d’éditeurs « partenaires », comme il les appelle. Et plus d’un million ont été créés en 2025 seulement. Ces modèles de redistribution des revenus sont souvent très simples : plus le nombre de vues et d’engagements générés sont élevés, plus la plateforme verse d’argent. Or, la communauté de la régul
Pour Tech Policy Press, Victoire Rio de What to Fix estime qu’il faut réguler les programmes de monétisation de contenus que proposent désormais toutes les plateformes. Facebook a plus de 3,8 millions d’éditeurs « partenaires », comme il les appelle. Et plus d’un million ont été créés en 2025 seulement. Ces modèles de redistribution des revenus sont souvent très simples : plus le nombre de vues et d’engagements générés sont élevés, plus la plateforme verse d’argent. Or, la communauté de la régulation s’est beaucoup intéressée à la modération des contenus, aux recommandations publicitaires, aux problèmes que posent l’amplification algorithmique, mais elle s’est peu penchée sur la « gouvernance de leur monétisation », c’est-à-dire à la façon dont les plateformes redistribuent l’argent et à la manière dont leurs décisions de monétisation « façonnent in fine l’environnement informationnel ».
Dans un rapport consacré au sujet, What to Fix estime que « les plateformes de médias sociaux ont redistribué plus de 20 milliards de dollars de leurs revenus à plus de 6 millions de comptes l’année dernière ». « Et pourtant, nous ignorons qui les plateformes ont payé, combien elles ont payé, ni pour quel contenu ! », rappelle Victoire Rio. L’enjeu n’est pas que cette redistribution n’ait pas lieu, bien au contraire, précise-t-elle : « Ce qui m’inquiète, c’est de laisser les décisions de redistribution des revenus aux plateformes de médias sociaux, sans transparence ni contrôle ». Et notamment, le fait que ces revenus bénéficient de plus en plus à des acteurs de la désinformation ou encore le fait que ces financements puissent être coupés unilatéralement pour nombre d’acteurs légitimes, avec des recours limités et sans compensation pour les pertes de revenus associées. Or, ni le DSA européen, ni le Online Safety Act britannique, n’abordent clairement les systèmes de monétisation des plateformes comme un vecteur de risque. Là encore, la transparence des modalités de reversement est en cause, accuse Victoire Rio, qui souhaite que nous considérions les modalités de monétisation comme un enjeu spécifique, c’est-à-dire un enjeu de régulation.
Pour Tech Policy Press, Victoire Rio de What to Fix estime qu’il faut réguler les programmes de monétisation de contenus que proposent désormais toutes les plateformes. Facebook a plus de 3,8 millions d’éditeurs « partenaires », comme il les appelle. Et plus d’un million ont été créés en 2025 seulement. Ces modèles de redistribution des revenus sont souvent très simples : plus le nombre de vues et d’engagements générés sont élevés, plus la plateforme verse d’argent. Or, la communauté de la régul
Pour Tech Policy Press, Victoire Rio de What to Fix estime qu’il faut réguler les programmes de monétisation de contenus que proposent désormais toutes les plateformes. Facebook a plus de 3,8 millions d’éditeurs « partenaires », comme il les appelle. Et plus d’un million ont été créés en 2025 seulement. Ces modèles de redistribution des revenus sont souvent très simples : plus le nombre de vues et d’engagements générés sont élevés, plus la plateforme verse d’argent. Or, la communauté de la régulation s’est beaucoup intéressée à la modération des contenus, aux recommandations publicitaires, aux problèmes que posent l’amplification algorithmique, mais elle s’est peu penchée sur la « gouvernance de leur monétisation », c’est-à-dire à la façon dont les plateformes redistribuent l’argent et à la manière dont leurs décisions de monétisation « façonnent in fine l’environnement informationnel ».
Dans un rapport consacré au sujet, What to Fix estime que « les plateformes de médias sociaux ont redistribué plus de 20 milliards de dollars de leurs revenus à plus de 6 millions de comptes l’année dernière ». « Et pourtant, nous ignorons qui les plateformes ont payé, combien elles ont payé, ni pour quel contenu ! », rappelle Victoire Rio. L’enjeu n’est pas que cette redistribution n’ait pas lieu, bien au contraire, précise-t-elle : « Ce qui m’inquiète, c’est de laisser les décisions de redistribution des revenus aux plateformes de médias sociaux, sans transparence ni contrôle ». Et notamment, le fait que ces revenus bénéficient de plus en plus à des acteurs de la désinformation ou encore le fait que ces financements puissent être coupés unilatéralement pour nombre d’acteurs légitimes, avec des recours limités et sans compensation pour les pertes de revenus associées. Or, ni le DSA européen, ni le Online Safety Act britannique, n’abordent clairement les systèmes de monétisation des plateformes comme un vecteur de risque. Là encore, la transparence des modalités de reversement est en cause, accuse Victoire Rio, qui souhaite que nous considérions les modalités de monétisation comme un enjeu spécifique, c’est-à-dire un enjeu de régulation.
Pascal Chabot est philosophe et enseigne à l’Institut des hautes études des communications sociales à Bruxelles. Son plus récent ouvrage, Un sens à la vie : enquête philosophique sur l’essentiel (PUF, 2024) fait suite à une riche production de livres, où la question du numérique est toujours présente, lancinante, quand elle n’est pas au cœur de sa réflexion. L’occasion de revenir avec lui sur comment les enjeux numériques d’aujourd’hui questionnent la philosophie. Entretien.
Dans les algorith
Pascal Chabot est philosophe et enseigne à l’Institut des hautes études des communications sociales à Bruxelles. Son plus récent ouvrage, Un sens à la vie : enquête philosophique sur l’essentiel (PUF, 2024) fait suite à une riche production de livres, où la question du numérique est toujours présente, lancinante, quand elle n’est pas au cœur de sa réflexion. L’occasion de revenir avec lui sur comment les enjeux numériques d’aujourd’hui questionnent la philosophie. Entretien.
Dans les algorithmes : Dans votre dernier livre, Un sens à la vie, vous vous interrogez sur le meaning washing, c’est à la dire à la fois sur la perte de sens de nos sociétés contemporaines et leur récupération, par exemple par le consumérisme qui nous invite à consommer pour donner du sens à l’existence. Pour vous, notre monde contemporain est saisi d’une “dissonance majeure”, où les sources de sens s’éloignent de nous du fait du développement d’environnements entièrement artificiels, du monde physique comme du monde numérique.
Couverture du livre de Pascal Chabot, Un sens à la vie.
Vous interrogez cette perte de sens ou notre difficulté, fréquente, à retrouver du sens dans les contradictions de la modernité. Retrouver le sens nécessite de trouver comment circuler entre les sensations, les significations et les orientations, expliquez-vous, c’est-à-dire à trouver des formes de circulations entre ce que l’on ressent, ce qu’on en comprend et là où l’on souhaite aller. “Vivre, c’est faire circuler du sens”, le désirer, se le réapproprier. Mais le sens que tout à chacun cherche est aujourd’hui bouleversé par le numérique. Le sens “est transformé par les modalités de sa transmission” dites-vous. En quoi ces nouvelles modalités de transmission modifient-elles notre compréhension même du monde ?
Pascal Chabot : Une chose qui m’intéresse beaucoup en philosophie, c’est de comprendre comment des questions, anciennes, traditionnelles, sont à la fois toujours actuelles et bouleversées par ce que nous vivons. Par rapport à la question du sens, qui est un accord entre ce que l’on sent, ce que l’on comprend et ce que l’on devient, les choses ont peu bougé. Un ancien grec ou un humaniste de la Renaissance auraient pu faire des constats sur le sens de la vie proches des miens, pour peu qu’ils aient été en dehors des très grands récits de transcendance qui s’imposaient alors, où le sens est donné par Dieu ou le Salut, c’est à dire où le sens a un nom avec une majuscule. Cette façon de faire circuler du sens dans nos vies, on la partage avec nos lointains prédécesseurs dans l’histoire de la philosophie. Il y a une lignée humaine dans laquelle nous sommes chacun profondément inscrits.
Cela étant, après avoir dit la continuité, il faut penser la rupture. Et la rupture, selon moi, elle est dans le branchement de nos consciences à ce que j’appelle le surconscient numérique. La conscience, telle qu’elle est ordinairement définie à partir du XXe siècle et bien sûr de Freud, est toujours couplée à son inconscient. Cette découverte, d’un enrichissement inédit, même si l’on ne sait pas toujours très bien ce qu’est l’inconscient, est restée d’une grande originalité, en apportant ce binôme conscience-inconscience qui permet d’enrichir notre compréhension de la pensée, en accord avec une nature humaine profonde, allant des grands mythes freudiens à la nature, dans lesquels notre inconscient peut s’exprimer, que ce soit via la sexualité ou la contemplation. Ce binôme a permis de créer des sens nouveaux. Cependant, je crois qu’on est de plus en plus débranchés de notre inconscient. C’est pourquoi une partie de la psychiatrie et de la psychanalyse ont un mal fou à comprendre ce qu’il se passe avec les nouvelles pathologies. En revanche, on est beaucoup plus branché, on fait couple, avec ce surconscient auquel on a accès dès qu’on fait le geste de consulter un écran. Ce mot surconscient, créé par analogie avec l’inconscient, est un mot assez large qui désigne pour moi un réseau, un dôme d’information, de communication, de protocoles d’échanges, d’images, qui a une certaine conscience. Une conscience relative comme l’inconscient a lui-même une conscience relative. Ce n’est pas une conscience en terme de « JE », mais de « NOUS ». C’est un savoir exploitable par la conscience et l’inconscient et qui est de plus en plus déterminant sur notre conscience comme sur notre inconscient.
Dans les algorithmes : Mais on pourrait dire que ce surconscient existait avant le numérique, non ? Des grands récits à la presse, toutes nos formes médiatiques et culturelles y participaient. Pourquoi le numérique modifierait-il particulièrement ce rapport ?
Pascal Chabot : Oui, toute œuvre culturelle, de la presse à la littérature, crée des bulles de signification, un cadre de signification, avec lequel nous sommes en dialogue. La graphosphère, comme on l’a parfois appelé, existe. Mais la grande différence, c’est que le monde numérique propose un monde où les significations ont une vie propre. Ce que Tolstoï a écrit par exemple, a été écrit une fois pour toute. On se réfère à Guerre et Paix à partir des significations qui ont été données depuis un écrit stabilisé. Si Guerre et Paix continue à vivre, c’est par l’acte d’enrichissement du livre dans notre imagination, dans nos souvenirs, dans notre mémoire. Dans le monde du surconscient numérique, il n’y a pas d’inertie. Les informations sont modifiées, mises à jour, répétées, dynamiques, avec une personnalisation des contenus continue. Cette personnalisation là est assez spécifique, centrée sur les personnes, calibrée pour chacun d’entre nous.
Cette personnalisation est une caractéristique importante. Il y en a une autre, celle du temps. Quand on se réfère à un livre écrit à la fin du XIXe siècle, on fait venir dans le temps présent un objet du passé. La sphère numérique est caractérisée par un temps nouveau, comme je l’évoquais dans Avoir le temps, où j’essayais de dire, qu’il y a eu deux grands temps. Le temps comme destin, c’est le temps de la nature, et le temps du progrès, celui de la construction d’un monde commun. Dans le numérique on vit un hypertemps. Un temps de synchronisation permanente. Un temps où la nouveauté est tout le temps présente. Un temps décompté, à rebours. Le temps du surconscient est aussi cet hypertemps. On est de moins en moins dans l’espace et de plus en plus dans des bulles temporelles qui s’ouvrent notamment quand on est dans la consommation de l’écran, où l’on se branche à un hypertemps commun.
« Dans le monde du surconscient numérique, il n’y a pas d’inertie. Les informations sont modifiées, mises à jour, répétées, dynamiques, avec une personnalisation des contenus continue. Cette personnalisation là est assez spécifique, centrée sur les personnes, calibrée pour chacun d’entre nous. »
Dans les algorithmes :Cette consommation d’écran, ce pas de côté dans nos réalités, nécessite de « faire le geste » dites-vous, c’est-à-dire d’ouvrir son smartphone. Geste que nous faisons des centaines de fois par jour. « Nous passons nos vies à caresser une vitre », ironise l’écrivain Alain Damasio. C’est consulter, nous brancher en permanence, dans un geste qui est désormais si présent dans notre quotidien, qu’il ne semble nullement le perturber, alors qu’il l’entrecoupe sans arrêt. Or, ce geste nous coupe de nos environnements. Il réduit nos sensations, limite nos orientations… Comme si ce geste était le symptôme de notre envahissement par ce surconscient…
Pascal Chabot : C’est effectivement sa matérialisation. C’est par ce geste que le surconscient colonise nos consciences. On dit beaucoup qu’on vit une mutation anthropologique majeure, mais elle est orchestrée par des ultraforces, c’est-à-dire des moyens qui ne sont pas une fin mais une force en soi, comme le sont la finance ou le numérique. « Faire le geste » nous fait changer de réalité, nous fait muter, nous fait passer dans un autre monde. Un monde très libidinal, un monde qui sait nos intentions, qui satisfait nos désirs. Un monde qui nous rend captif mais qui nous permet surtout de quitter une réalité qui nous apparaît de moins en moins satisfaisante. Le rapport au présent, à la matérialité, nous apparaît désormais plus pauvre que le voyage dans le surconscient de l’humanité. La plupart d’entre nous sommes devenus incapables de rester 5 minutes sans « faire le geste ». Toute addiction est aphrodisiaque : elle nous promet un désir qu’on ne peut plus avoir ailleurs. Comme si notre conscience et notre inconscient ne nous suffisaient plus.
Dans les algorithmes : Vous reconnaissez pourtant que ce surconscient a des vertus : « il fait exploser nos compréhensions », dites-vous. Vous expliquez que le rendement informationnel du temps que l’on passe sur son smartphone – différent de son impact intellectuel ou affectif – est bien supérieur à la lecture d’un livre ou même d’un dialogue avec un collègue. Que notre connexion au réseau permet de zoomer et dézoomer en continue, comme disait le sociologue Dominique Cardon, nous permet d’aller du micro au macro. Nous sommes plongés dans un flux continu de signifiants. “Les sensations s’atrophient, les significations s’hypertrophient. Quant aux orientations, en se multipliant et se complexifiant, elles ouvrent sur des mondes labyrinthiques” qui se reconfigurent selon nos circulations. Nous sommes plongés dans un surconscient tentaculaire qui vient inhiber notre inconscient et notre conscience. Ce surconscient perturbe certes la circulation du sens. Mais nos écrans ne cessent de produire du sens en permanence…
Pascal Chabot : Oui, mais ce surconscient apporte de l’information, plus que du sens. Je parle bien de rendement informationnel. Quand les livres permettent eux de déployer l’imagination, la créativité, la sensibilité, l’émotivité… de les ancrer dans nos corps, de dialoguer avec l’inconscient. En revanche, ce que nous offre le surconscient en terme quantitatif, en précision, en justesse est indéniable. Comme beaucoup, j’ai muté des mondes de la bibliothèque au monde du surconscient. Il était souvent difficile de retrouver une information dans le monde des livres. Alors que le surconscient, lui, est un monde sous la main. Nous avons un accès de plus en plus direct à l’information. Et celle-ci se rapproche toujours plus de notre conscience, notamment avec ChatGPT. La recherche Google nous ouvrait une forme d’arborescence dans laquelle nous devions encore choisir où aller. Avec les chatbots, l’information arrive à nous de manière plus directe encore.
Mais l’information n’est ni le savoir ni la sagesse et sûrement pas le sens.
Dans les algorithmes :Vous dites d’ailleurs que nous sommes entrés dans des sociétés de la question après avoir été des sociétés de la réponse. Nous sommes en train de passer de la réponse qu’apporte un article de Wikipédia, à une société de l’invite, à l’image de l’interface des chatbots qui nous envahissent, et qui nous invitent justement à poser des questions – sans nécessairement en lire les réponses d’ailleurs. Est-ce vraiment une société de la question, de l’interrogation, quand, en fait, les réponses deviennent sans importance ?
Pascal Chabot : Quand j’évoque les sociétés de la question et de la réponse, j’évoque les sociétés modernes du XVIIe et du XVIIIe siècle, des sociétés où certaines choses ne s’interrogent pas, parce qu’il y a des réponses partout. La question du sens ne hante pas les grands penseurs de cette époque car pour eux, le sens est donné. Les sociétés de la question naissent de la mort de Dieu, de la perte de la transcendance et du fait qu’on n’écrit plus le sens en majuscule. Ce sont des sociétés de l’inquiétude et du questionnement. La question du sens de la vie est une question assez contemporaine finalement. C’est Nietzsche qui est un des premiers à la poser sous cette forme là.
Dans la société de la question dans laquelle nous entrons, on interroge les choses, le sens… Mais les réponses qui nous sont faites restent désincanées. Or, pour que le sens soit présent dans une existence, il faut qu’il y ait un enracinement, une incarnation… Il faut que le corps soit là pour que la signification soit comprise. Il faut une parole et pas seulement une information. De même, l’orientation, le chemin et son caractère initiatique comme déroutant, produisent du sens.
Mais, si nous le vivons ainsi c’est parce que nous avons vécu dans un monde de sensation, de signification et d’orientation relativement classique. Les plus jeunes n’ont pas nécessairement ces réflexes. Certains sont déjà couplés aux outils d’IA générative qui leurs servent de coach particuliers en continue… C’est un autre rapport au savoir qui arrive pour une génération qui n’a pas le rapport au savoir que nous avons construit.
Dans les algorithmes : Vous expliquez que cette extension du surconscient produit des pathologies que vous qualifiez de digitoses, pour parler d’un conflit entre la conscience et le surconscient. Mais pourquoi parlez-vous de digitose plutôt que de nouvelles névroses ou de nouvelles psychoses ?
Pascal Chabot : Quand j’ai travaillé sur la question du burn-out, j’ai pu constater que le domaine de la santé mentale devait évoluer. Les concepts classiques, de névrose ou de psychose, n’étaient plus opérants pour décrire ces nouvelles afflictions. Nous avions des notions orphelines d’une théorie plus englobante. Le burn-out ou l’éco-anxiété ne sont ni des névroses ni des psychoses. Pour moi, la santé mentale avait besoin d’un aggiornamento, d’une mise à jour. J’ai cherché des analogies entre inconscient et surconscient, le ça, le là, le refoulement et le défoulement… J’ai d’abord trouvé le terme de numérose avant de lui préféré le terme de digitose en référence au digital plus qu’au numérique. C’est un terme qui par son suffixe en tout cas ajoute un penchant pathologique au digital. Peu à peu, les digitoses se sont structurées en plusieurs familles : les digitoses de scission, d’avenir, de rivalité… qui m’ont permis de créer une typologie des problèmes liés à un rapport effréné ou sans conscience au numérique qui génère de nouveaux types de pathologies.
Dans les algorithmes : Le terme de digitose, plus que le lien avec le surconscient, n’accuse-t-il pas plus le messager que le message ? Sur l’éco-anxiété, l’information que l’on obtient via le numérique peut nous amener à cette nouvelle forme d’inquiétude sourde vis à vis du futur, mais on peut être éco-anxieux sans être connecté. Or, dans votre typologie des digitoses, c’est toujours le rapport au numérique qui semble mis au banc des accusés…
Pascal Chabot : Je ne voudrais pas donner l’impression que je confond le thermomètre et la maladie effectivement. Mais, quand même : le média est le message. Ce genre de pathologies là, qui concernent notre rapport au réel, arrivent dans un monde où le réel est connu et transformé par le numérique. Pour prendre l’exemple de l’éco-anxiété, on pourrait tout à fait faire remarquer qu’elle a existé avant internet. Le livre de Rachel Carson, Le printemps silencieux, par exemple, date des années 60.
Mais, ce qui est propre au monde numérique est qu’il a permis de populariser une connaissance de l’avenir que le monde d’autrefois ne connaissait absolument pas. L’avenir a toujours été le lieu de l’opacité, comblé par de grands récits mythiques ou apocalyptiques. Aujourd’hui, l’apport informationnel majeur du numérique, permet d’avoir pour chaque réalité un ensemble de statistiques prospectives extrêmement fiables. On peut trouver comment vont évoluer les populations d’insectes, la fonte des glaciers, les températures globales comme locales… Ce n’est pas uniquement le média numérique qui est mobilisé ici, mais la science, la technoscience, les calculateurs… c’est-à-dire la forme contemporaine du savoir. Les rapports du Giec en sont une parfaite illustration. Ils sont des éventails de scénarios chiffrés, sourcés, documentés… assortis de probabilités et validés collectivement. Ils font partie du surconscient, du dôme de savoir dans lequel nous évoluons et qui étend sa chape d’inquiétude et de soucis sur nos consciences. L’éco-anxiété est une digitose parce que c’est le branchement à ce surconscient là qui est important. Ce n’est pas uniquement la digitalisation de l’information qui est en cause, mais l’existence d’un contexte informationnel dont le numérique est le vecteur.
« Le numérique a permis de populariser une connaissance de l’avenir que le monde d’autrefois ne connaissait absolument pas »
Dans les algorithmes : Ce n’est pas le fait que ce soit numérique, c’est ce que ce branchement transforme en nous…
Pascal Chabot : Oui, c’est la même chose dans le monde du travail, par rapport à la question du burn-out… Nombre de burn-out sont liés à des facteurs extra-numériques qui vont des patrons chiants, aux collègues toxiques… et qui ont toujours existé, hélas. Mais dans la structure contemporaine du travail, dans son exigence, dans ce que les algorithmes font de notre rapport au système, au travail, à la société… ces nouveaux branchements, ce reporting constant, cette normalisation du travail… renforcent encore les souffrances que nous endurons.
« L’éco-anxiété est une digitose parce que c’est le branchement à ce surconscient là qui est important. Ce n’est pas uniquement la digitalisation de l’information qui est en cause, mais l’existence d’un contexte informationnel dont le numérique est le vecteur. »
Dans les algorithmes :Outre la digitose de scission (le burn-out), et la digitose d’avenir (l’éco-anxiété) dont vous nous avez parlé, vous évoquez aussi la digitose de rivalité, celle de notre confrontation à l’IA et de notre devenir machine. Expliquez-nous !
Pascal Chabot : Il faut partir de l’écriture pour la comprendre. Ce que l’on délègue à un chatbot, c’est de l’écriture. Bien sûr, elles peuvent générer bien d’autres choses, mais ce sont d’abord des machines qui ont appris à aligner des termes en suivant les grammaires pour produire des réponses sensées, c’est-à-dire qui font sens pour quelqu’un qui les lit. Ce qui est tout à fait perturbant, c’est que de cette sorte de graphogenèse, de genèse du langage graphique, naît quelque chose comme une psychogenèse. C’est simplement le bon alignement de termes qui répond à telle ou telle question qui nous donne l’impression d’une intentionnalité. Depuis que l’humanité est l’humanité, un terme écrit nous dit qu’il a été pensé par un autre. Notre rapport au signe attribue toujours une paternité. L’humanité a été créée par les Ecritures. Les sociétés religieuses, celles des grands monothéismes, sont des sociétés du livre. Être en train de déléguer l’écriture à des machines qui le feront de plus en plus correctement, est quelque chose d’absolument subjuguant. Le problème, c’est que l’humain est paresseux et que nous risquons de prendre cette voie facile. Nos consciences sont pourtant nées de l’écriture. Et voilà que désormais, elles se font écrire par des machines qui appartiennent à des ultraforces qui ont, elles, des visées politiques et économiques. Politique, car écrire la réponse à la question « la démocratie est-elle un bon régime ? » dépendra de qui relèvent de ces ultraforces. Économique, comme je m’en amusait dans L’homme qui voulait acheter le langage… car l’accès à ChatGPT est déjà payant et on peut imaginer que les accès à de meilleures versions demain, pourraient être plus chères encore. La capitalisme linguistique va continuer à se développer. L’écriture, qui a été un outil d’émancipation démocratique sans commune mesure (car apprendre à écrire a toujours été le marqueur d’entrée dans la société), risque de se transformer en simple outil de consommation. Outre la rivalité existentielle de l’IA qui vient dévaluer notre intelligence, les impacts politiques et économiques ne font que commencer. Pour moi, il y dans ce nouveau rapport quelque chose de l’ordre de la dépossession, d’une dépossession très très profonde de notre humanité.
Dans les algorithmes : Ecrire, c’est penser. Être déposséder de l’écriture, c’est être dépossédé de la pensée.
Pascal Chabot : Oui et cela reste assez vertigineux. Notamment pour ceux qui ont appris à manier l’écriture et la pensée. Ecrire, c’est s’emparer du langage pour lui injecter un rythme, une stylistique et une heuristique, c’est-à-dire un outil de découverte, de recherche, qui nous permet de stabiliser nos relations à nous-mêmes, à autrui, au savoir… Quand on termine un mail, on réfléchit à la formule qu’on veut adopter en fonction de la relation à l’autre que nous avons… jusqu’à ce que les machines prennent cela en charge. On a l’impression pour le moment d’être au stade de la rivalité entre peinture et photographie vers 1885. Souvenons-nous que la photographie a balayé le monde ancien.
Mais c’est un monde dont il faut reconnaître aussi les limites et l’obsolescence. Le problème des nouvelles formes qui viennent est que le sens qu’elles proposent est bien trop extérieur aux individus. On enlève l’individu au sens. On est dans des significations importées, dans des orientations qui ne sont pas vécues existentiellement.
Dans les algorithmes :Pour répondre aux pathologies des digitoses, vous nous invitez à une thérapie de civilisation. De quoi avons-nous besoin pour pouvoir répondre aux digitoses ?
Pascal Chabot : La conscience, le fait d’accompagner en conscience ce que nous faisons change la donne. Réfléchir sur le temps, prendre conscience de notre rapport temporel, change notre rapport au temps. Réfléchir à la question du sens permet de prendre une hauteur et de créer une série de filtres permettant de distinguer des actions insensées qui relèvent à la fois des grandes transcendance avec une majuscule que des conduites passives face au sens. La thérapie de la civilisation, n’est rien d’autre que la philosophie. C’est un plaidoyer pro domo ! Mais la philosophie permet de redoubler ce que nous vivons d’une sorte de conscience de ce que nous vivons : la réflexivité. Et cette façon de réfléchir permet d’évaluer et garder vive la question de l’insensé, de l’absurde et donc du sens.
Dans les algorithmes : Dans ce surconscient qui nous aplatit, comment vous situez-vous face aux injonctions à débrancher, à ne plus écouter la télévision, la radio, à débrancher les écrans ? Cela relève d’un levier, du coaching comportemental ou est-ce du meaning washing ?
Pascal Chabot : Je n’y crois pas trop. C’est comme manger des légumes ou faire pipi sous la douche. Les mouvements auxquels nous sommes confrontés sont bien plus profonds. Bien sûr, chacun s’adapte comme il peut. Je ne cherche pas à être jugeant. Mais cela nous rappelle d’ailleurs que la civilisation du livre et de l’écrit a fait beaucoup de dégâts. La conscience nous aide toujours à penser mieux. Rien n’est neutre. Confrontés aux ultraforces, on est dans un monde qui développe des anti-rapports, à la fois des dissonnances, des dénis ou des esquives pour tenter d’échapper à notre impuissance.
Dans les algorithmes : Vous êtes assez alarmiste sur les enjeux civilisationnels de l’intelligence artificielle que vous appelez très joliment des « communicants artificiels ». Et de l’autre, vous nous expliquez que ces outils vont continuer la démocratisation culturelle à l’œuvre. Vous rappelez d’ailleurs que le protestantisme est né de la généralisation de la lecture et vous posez la question : « que naîtra-t-il de la généralisation de l’écriture ? »
Mais est-ce vraiment une généralisation de l’écriture à laquelle nous assistons ? On parle de l’écriture de et par des machines. Et il n’est pas sûr que ce qu’elles produisent nous pénètrent, nous traversent, nous émancipent. Finalement, ce qu’elles produisent ne sont que des réponses qui ne nous investissent pas nécessairement. Elles font à notre place. Nous leur déléguons non seulement l’écriture, mais également la lecture… au risque d’abandonner les deux. Est-ce que ces outils produisent vraiment une nouvelle démocratisation culturelle ? Sommes-nous face à un nouvel outil interculturel ou assistons-nous simplement à une colonisation et une expansion du capitalisme linguistique ?
Pascal Chabot : L’écriture a toujours été une sorte de ticket d’entrée dans la société et selon les types d’écritures dont on était capable, on pouvait pénétrer dans tel ou tel milieu. L’écriture est très clairement un marqueur de discrimination sociale. C’est le cas de l’orthographe, très clairement, qui est la marque de niveaux d’éducation. Mais au-delà de l’orthographe, le fait de pouvoir rédiger un courrier, un CV… est quelque chose de très marqué socialement. Dans une formation à l’argumentation dans l’équivalent belge de France Travail, j’ai été marqué par le fait que pour les demandeurs d’emploi, l’accès à l’IA leur changeait la vie, leur permettant d’avoir des CV, des lettres de motivation adaptées. Pour eux, c’était un boulet de ne pas avoir de CV corrects. Même chose pour les étudiants. Pour nombre d’entre eux, écrire est un calvaire et ils savent très bien que c’est ce qu’ils ne savent pas toujours faire correctement. Dans ces nouveaux types de couplage que l’IA permet, branchés sur un surconscient qui les aide, ils ont accès à une assurance nouvelle.
Bien sûr, dans cette imitation, personne n’est dupe. Mais nous sommes conditionnés par une société qui attribue à l’auteur d’un texte les qualités de celui-ci, alors que ses productions ne sont pas que personnelles, elles sont d’abord le produit des classes sociales de leurs auteurs, de la société dont nous sommes issus. Dans ce nouveau couplage à l’IA, il me semble qu’il y a quelque chose de l’ordre d’une démocratisation.
Dans les algorithmes :Le risque avec l’IA, n’est-il pas aussi, derrière la dépossession de l’écriture, notre dépossession du sens lui-même ? Le sens nous est désormais imposé par d’autres, par les résultats des machines. Ce qui m’interroge beaucoup avec l’IA, c’est cette forme de délégation des significations, leur aplatissement, leur moyennisation. Quand on demande à ces outils de nous représenter un mexicain, ils nous livrent l’image d’une personne avec un sombrero ! Or, faire société, c’est questionner tout le temps les significations pour les changer, les modifier, les faire évoluer. Et là, nous sommes confrontés à des outils qui les figent, qui excluent ce qui permet de les remettre en cause, ce qui sort de la norme, de la moyenne…
Pascal Chabot : Oui, nous sommes confrontés à un « Bon gros bon sens » qui n’est pas sans rappeler Le dictionnaire des idées de reçues de Flaubert…
Dans les algorithmes :…mais le dictionnaire des idées reçues était ironique, lui !
Pascal Chabot : Il est ironique parce qu’il a vu l’humour dans le « Bon gros bon sens ». Dans la société, les platitudes circulent. C’est la tâche de la culture et de la créativité de les dépasser. Car le « Bon gros bon sens » est aussi très politique : il est aussi un sens commun, avec des assurances qui sont rabachées, des slogans répétés…. Les outils d’IA sont de nouveaux instruments de bon sens, notamment parce qu’ils doivent plaire au plus grand monde. On est très loin de ce qui est subtil, de ce qui est fin, polysémique, ambiguë, plein de doute, raffiné, étrange, surréaliste… C’est-à-dire tout ce qui fait la vie de la culture. On est plongé dans un pragmatisme anglo-saxon, qui a un rapport au langage très peu polysémique d’ailleurs. Le problème, c’est que ce « Bon gros bon sens » est beaucoup plus invasif. Il a une force d’autorité. Le produit de ChatGPT ne nous est-il pas présenté d’ailleurs comme un summum de la science ?
« Les outils d’IA sont de nouveaux instruments de bon sens, notamment parce qu’ils doivent plaire au plus grand monde. On est très loin de ce qui est subtil, de ce qui est fin, polysémique, ambiguë, plein de doute, raffiné, étrange, surréaliste… C’est-à-dire tout ce qui fait la vie de la culture. »
Dans les algorithmes : Et en même temps, ce calcul laisse bien souvent les gens sans prise, sans moyens d’action individuels comme collectifs.
Le point commun entre les différentes digitoses que vous listez me semble-t-il est que nous n’avons pas de réponses individuelles à leur apporter. Alors que les névroses et psychoses nécessitent notre implication pour être réparées. Face aux digitoses, nous n’avons pas de clefs, nous n’avons pas de prises, nous sommes sans moyen d’action individuels comme collectifs. Ne sommes nous pas confrontés à une surconscience qui nous démunie ?
Pascal Chabot : Il est certain que le couplage des consciences au surconscient, en tant qu’elle est un processus de civilisation, apparaît comme un nouveau destin. Il s’impose, piloté par des ultraforces sur lesquelles nous n’avons pas de prise. En ce sens, il s’agit d’un nouveau destin, avec tout ce que ce terme charrie d’imposition et d’inexorabilité.
En tant que les digitoses expriment le versant problématique de ce nouveau couplage, elles aussi ont quelque chose de fatal. Branchée à une réalité numérique qui la dépasse et la détermine, la conscience peine souvent à exprimer sa liberté, qui est pourtant son essence. La rivalité avec les IA, l’eco-anxiété, la scission avec le monde sensible : autant de digitoses qui ont un aspect civilisationnel, presque indépendant du libre-arbitre individuel. Les seules réponses, en l’occurrence, ne peuvent être que politiques. Mais là aussi, elles ne sont pas faciles à imaginer.
Or on ne peut pourtant en rester là. Si ce seul aspect nécessaire existait, toute cette théorie ne serait qu’une nouvelle formulation de l’aliénation. Mais les digitoses ont une composante psychologique, de même que les névroses et psychoses. Cette composante recèle aussi des leviers de résistance. La prise de conscience, la lucidité, la reappropriation, l’hygiène mentale, une certaine désintoxication, le choix de brancher sa conscience sur des réalités extra-numériques, et tant d’autres stratégies encore, voire tant d’autres modes de vies, peuvent très clairement tempérer l’emprise de ces digitoses sur l’humain. C’est dire que l’individu, face à ce nouveau destin civilisationnel, garde des marges de résistance qui, lorsqu’elles deviennent collectives, peuvent être puissantes.
Les digitoses sont donc un défi et un repoussoir : une occasion de chercher et d’affirmer des libertés nouvelles dans un monde où s’inventent sous nos yeux de nouveaux déterminismes.
Dans les algorithmes : Derrière le surconscient, le risque n’est-il pas que s’impose une forme de sur-autorité, de sur-vision… sur lesquelles, il sera difficile de créer des formes d’échappement, de subtilité, d’ambiguité. On a l’impression d’être confronté à une force politique qui ne dit pas son nom mais qui se donne un nouveau moyen de pouvoir…
Pascal Chabot : C’est clair que la question est celle du pouvoir, politique et économique. Les types de résistances sont extrêmement difficiles à inventer. C’est le propre du pouvoir de rendre la résistance à sa force difficile. On est confronté à un tel mélange de pragmatisme, de facilitation de la vie, de création d’une bulle de confort, d’une enveloppe où les réponses sont faciles et qui nous donnent accès à de nouveaux mondes, comme le montrait la question de la démocratisation qu’on évoquait à l’instant… que la servitude devient très peu apparente. Et la perte de subtilité et d’ambiguïté est peu vue, car les gains économiques supplantent ces pertes. Qui se rend compte de l’appauvrissement ? Il faut avoir un pied dans les formes culturelles précédentes pour cela. Quand les choses seront plus franches, ce que je redoute, c’est que nos démocraties ne produisent pas de récits numériques pour faire entendre une autre forme de puissance.
Dans les algorithmes :En 2016 vous avez publié, ChatBot le robot, une très courte fable écrite bien avant l’avènement de l’IA générative, qui met en scène un jury de philosophes devant décider si une intelligence artificielle est capable de philosopher. Ce petit drame philosophique où l’IA fomente des réponses à des questions philosophiques, se révèle très actuel 9 ans plus tard. Qualifieriez vous ChatGPT et ses clones de philosophes ?
Pascal Chabot : Je ne suis pas sûr. Je ne suis pas sûr que ce chatbot là se le décernerait à lui, comme il est difficile à un artiste de se dire artiste. Mon Chatbot était un récalcitrant, ce n’est pas le cas des outils d’IA d’aujourd’hui. Il leur manque un rapport au savoir, le lien entre la sensation et la signification. La philosophie ne peut pas être juste de la signification. Et c’est pour cela que l’existentialisme reste la matrice de toute philosophie, et qu’il n’y a pas de philosophie qui serait non-existentielle, c’est-à-dire pure création de langage. La graphogenèse engendre une psychogenèse. Mais la psychogenèse, cette imitation de la conscience, n’engendre ni philosophie ni pensée humaine. Il n’y a pas de conscience artificielle. La conscience est liée à la naissance, la mort, la vie.
Dans les algorithmes :La question de l’incalculabitéest le sujet de la conférence USI 2025 à laquelle vous allez participer. Pour un un philosophe, qu’est-ce qui est incalculable ?
Pascal Chabot : L’incalculable, c’est le subtil ! L’étymologie de subtil, c’est subtela, littéralement, ce qui est en-dessous d’une toile. En dessous d’une toile sur laquelle on tisse, il y a évidémment la trame, les fils de trame. Le subtil, c’est les fils de trame, c’est-à-dire nos liens majeurs, les liens à nous-mêmes, aux autres, au sens, à la culture, nos liens amoureux, amicaux… Et tout cela est profondément de l’ordre de l’incalculable. Et tout cela est même profané quand on les calcule. Ces liens sont ce qui résiste intrinsèquement à la calculabilité, qui est pourtant l’un des grands ressort de l’esprit humain et pas seulement des machines. Le problème, c’est qu’on est tellement dans une idéologie de la calculabilité qu’on ne perçoit même plus qu’on peut faire des progrès dans le domaine du subtil. Désormais, le progrès semble lié à la seule calculabilité. Le progrès est un progrès du calculable et de l’utile. Or, je pense qu’il existe aussi un progrès dans le domaine du subtil. Dans l’art d’être ami par exemple, dans l’art d’être lié à soi-même ou aux autres, il y a moyen de faire des progrès. Il y a là toute une zone de développement, de progrès (nous ne devons pas laisser le terme uniquement à la civilisation techno-économique), de progrès subtil. Un progrès subtil, incalculable, mais extrêmement précieux.
Propos recueillis par Hubert Guillaud.
Pascal Chabot sera l’un des intervenants de la conférence USI 2025 qui aura lieu lundi 2 juin à Paris et dont le thème est « la part incalculable du numérique » et pour laquelle Danslesalgorithmes.net est partenaire.
Pascal Chabot est philosophe et enseigne à l’Institut des hautes études des communications sociales à Bruxelles. Son plus récent ouvrage, Un sens à la vie : enquête philosophique sur l’essentiel (PUF, 2024) fait suite à une riche production de livres, où la question du numérique est toujours présente, lancinante, quand elle n’est pas au cœur de sa réflexion. L’occasion de revenir avec lui sur comment les enjeux numériques d’aujourd’hui questionnent la philosophie. Entretien.
Dans les algorith
Pascal Chabot est philosophe et enseigne à l’Institut des hautes études des communications sociales à Bruxelles. Son plus récent ouvrage, Un sens à la vie : enquête philosophique sur l’essentiel (PUF, 2024) fait suite à une riche production de livres, où la question du numérique est toujours présente, lancinante, quand elle n’est pas au cœur de sa réflexion. L’occasion de revenir avec lui sur comment les enjeux numériques d’aujourd’hui questionnent la philosophie. Entretien.
Dans les algorithmes : Dans votre dernier livre, Un sens à la vie, vous vous interrogez sur le meaning washing, c’est à la dire à la fois sur la perte de sens de nos sociétés contemporaines et leur récupération, par exemple par le consumérisme qui nous invite à consommer pour donner du sens à l’existence. Pour vous, notre monde contemporain est saisi d’une “dissonance majeure”, où les sources de sens s’éloignent de nous du fait du développement d’environnements entièrement artificiels, du monde physique comme du monde numérique.
Couverture du livre de Pascal Chabot, Un sens à la vie.
Vous interrogez cette perte de sens ou notre difficulté, fréquente, à retrouver du sens dans les contradictions de la modernité. Retrouver le sens nécessite de trouver comment circuler entre les sensations, les significations et les orientations, expliquez-vous, c’est-à-dire à trouver des formes de circulations entre ce que l’on ressent, ce qu’on en comprend et là où l’on souhaite aller. “Vivre, c’est faire circuler du sens”, le désirer, se le réapproprier. Mais le sens que tout à chacun cherche est aujourd’hui bouleversé par le numérique. Le sens “est transformé par les modalités de sa transmission” dites-vous. En quoi ces nouvelles modalités de transmission modifient-elles notre compréhension même du monde ?
Pascal Chabot : Une chose qui m’intéresse beaucoup en philosophie, c’est de comprendre comment des questions, anciennes, traditionnelles, sont à la fois toujours actuelles et bouleversées par ce que nous vivons. Par rapport à la question du sens, qui est un accord entre ce que l’on sent, ce que l’on comprend et ce que l’on devient, les choses ont peu bougé. Un ancien grec ou un humaniste de la Renaissance auraient pu faire des constats sur le sens de la vie proches des miens, pour peu qu’ils aient été en dehors des très grands récits de transcendance qui s’imposaient alors, où le sens est donné par Dieu ou le Salut, c’est à dire où le sens a un nom avec une majuscule. Cette façon de faire circuler du sens dans nos vies, on la partage avec nos lointains prédécesseurs dans l’histoire de la philosophie. Il y a une lignée humaine dans laquelle nous sommes chacun profondément inscrits.
Cela étant, après avoir dit la continuité, il faut penser la rupture. Et la rupture, selon moi, elle est dans le branchement de nos consciences à ce que j’appelle le surconscient numérique. La conscience, telle qu’elle est ordinairement définie à partir du XXe siècle et bien sûr de Freud, est toujours couplée à son inconscient. Cette découverte, d’un enrichissement inédit, même si l’on ne sait pas toujours très bien ce qu’est l’inconscient, est restée d’une grande originalité, en apportant ce binôme conscience-inconscience qui permet d’enrichir notre compréhension de la pensée, en accord avec une nature humaine profonde, allant des grands mythes freudiens à la nature, dans lesquels notre inconscient peut s’exprimer, que ce soit via la sexualité ou la contemplation. Ce binôme a permis de créer des sens nouveaux. Cependant, je crois qu’on est de plus en plus débranchés de notre inconscient. C’est pourquoi une partie de la psychiatrie et de la psychanalyse ont un mal fou à comprendre ce qu’il se passe avec les nouvelles pathologies. En revanche, on est beaucoup plus branché, on fait couple, avec ce surconscient auquel on a accès dès qu’on fait le geste de consulter un écran. Ce mot surconscient, créé par analogie avec l’inconscient, est un mot assez large qui désigne pour moi un réseau, un dôme d’information, de communication, de protocoles d’échanges, d’images, qui a une certaine conscience. Une conscience relative comme l’inconscient a lui-même une conscience relative. Ce n’est pas une conscience en terme de « JE », mais de « NOUS ». C’est un savoir exploitable par la conscience et l’inconscient et qui est de plus en plus déterminant sur notre conscience comme sur notre inconscient.
Dans les algorithmes : Mais on pourrait dire que ce surconscient existait avant le numérique, non ? Des grands récits à la presse, toutes nos formes médiatiques et culturelles y participaient. Pourquoi le numérique modifierait-il particulièrement ce rapport ?
Pascal Chabot : Oui, toute œuvre culturelle, de la presse à la littérature, crée des bulles de signification, un cadre de signification, avec lequel nous sommes en dialogue. La graphosphère, comme on l’a parfois appelé, existe. Mais la grande différence, c’est que le monde numérique propose un monde où les significations ont une vie propre. Ce que Tolstoï a écrit par exemple, a été écrit une fois pour toute. On se réfère à Guerre et Paix à partir des significations qui ont été données depuis un écrit stabilisé. Si Guerre et Paix continue à vivre, c’est par l’acte d’enrichissement du livre dans notre imagination, dans nos souvenirs, dans notre mémoire. Dans le monde du surconscient numérique, il n’y a pas d’inertie. Les informations sont modifiées, mises à jour, répétées, dynamiques, avec une personnalisation des contenus continue. Cette personnalisation là est assez spécifique, centrée sur les personnes, calibrée pour chacun d’entre nous.
Cette personnalisation est une caractéristique importante. Il y en a une autre, celle du temps. Quand on se réfère à un livre écrit à la fin du XIXe siècle, on fait venir dans le temps présent un objet du passé. La sphère numérique est caractérisée par un temps nouveau, comme je l’évoquais dans Avoir le temps, où j’essayais de dire, qu’il y a eu deux grands temps. Le temps comme destin, c’est le temps de la nature, et le temps du progrès, celui de la construction d’un monde commun. Dans le numérique on vit un hypertemps. Un temps de synchronisation permanente. Un temps où la nouveauté est tout le temps présente. Un temps décompté, à rebours. Le temps du surconscient est aussi cet hypertemps. On est de moins en moins dans l’espace et de plus en plus dans des bulles temporelles qui s’ouvrent notamment quand on est dans la consommation de l’écran, où l’on se branche à un hypertemps commun.
« Dans le monde du surconscient numérique, il n’y a pas d’inertie. Les informations sont modifiées, mises à jour, répétées, dynamiques, avec une personnalisation des contenus continue. Cette personnalisation là est assez spécifique, centrée sur les personnes, calibrée pour chacun d’entre nous. »
Dans les algorithmes :Cette consommation d’écran, ce pas de côté dans nos réalités, nécessite de « faire le geste » dites-vous, c’est-à-dire d’ouvrir son smartphone. Geste que nous faisons des centaines de fois par jour. « Nous passons nos vies à caresser une vitre », ironise l’écrivain Alain Damasio. C’est consulter, nous brancher en permanence, dans un geste qui est désormais si présent dans notre quotidien, qu’il ne semble nullement le perturber, alors qu’il l’entrecoupe sans arrêt. Or, ce geste nous coupe de nos environnements. Il réduit nos sensations, limite nos orientations… Comme si ce geste était le symptôme de notre envahissement par ce surconscient…
Pascal Chabot : C’est effectivement sa matérialisation. C’est par ce geste que le surconscient colonise nos consciences. On dit beaucoup qu’on vit une mutation anthropologique majeure, mais elle est orchestrée par des ultraforces, c’est-à-dire des moyens qui ne sont pas une fin mais une force en soi, comme le sont la finance ou le numérique. « Faire le geste » nous fait changer de réalité, nous fait muter, nous fait passer dans un autre monde. Un monde très libidinal, un monde qui sait nos intentions, qui satisfait nos désirs. Un monde qui nous rend captif mais qui nous permet surtout de quitter une réalité qui nous apparaît de moins en moins satisfaisante. Le rapport au présent, à la matérialité, nous apparaît désormais plus pauvre que le voyage dans le surconscient de l’humanité. La plupart d’entre nous sommes devenus incapables de rester 5 minutes sans « faire le geste ». Toute addiction est aphrodisiaque : elle nous promet un désir qu’on ne peut plus avoir ailleurs. Comme si notre conscience et notre inconscient ne nous suffisaient plus.
Dans les algorithmes : Vous reconnaissez pourtant que ce surconscient a des vertus : « il fait exploser nos compréhensions », dites-vous. Vous expliquez que le rendement informationnel du temps que l’on passe sur son smartphone – différent de son impact intellectuel ou affectif – est bien supérieur à la lecture d’un livre ou même d’un dialogue avec un collègue. Que notre connexion au réseau permet de zoomer et dézoomer en continue, comme disait le sociologue Dominique Cardon, nous permet d’aller du micro au macro. Nous sommes plongés dans un flux continu de signifiants. “Les sensations s’atrophient, les significations s’hypertrophient. Quant aux orientations, en se multipliant et se complexifiant, elles ouvrent sur des mondes labyrinthiques” qui se reconfigurent selon nos circulations. Nous sommes plongés dans un surconscient tentaculaire qui vient inhiber notre inconscient et notre conscience. Ce surconscient perturbe certes la circulation du sens. Mais nos écrans ne cessent de produire du sens en permanence…
Pascal Chabot : Oui, mais ce surconscient apporte de l’information, plus que du sens. Je parle bien de rendement informationnel. Quand les livres permettent eux de déployer l’imagination, la créativité, la sensibilité, l’émotivité… de les ancrer dans nos corps, de dialoguer avec l’inconscient. En revanche, ce que nous offre le surconscient en terme quantitatif, en précision, en justesse est indéniable. Comme beaucoup, j’ai muté des mondes de la bibliothèque au monde du surconscient. Il était souvent difficile de retrouver une information dans le monde des livres. Alors que le surconscient, lui, est un monde sous la main. Nous avons un accès de plus en plus direct à l’information. Et celle-ci se rapproche toujours plus de notre conscience, notamment avec ChatGPT. La recherche Google nous ouvrait une forme d’arborescence dans laquelle nous devions encore choisir où aller. Avec les chatbots, l’information arrive à nous de manière plus directe encore.
Mais l’information n’est ni le savoir ni la sagesse et sûrement pas le sens.
Dans les algorithmes :Vous dites d’ailleurs que nous sommes entrés dans des sociétés de la question après avoir été des sociétés de la réponse. Nous sommes en train de passer de la réponse qu’apporte un article de Wikipédia, à une société de l’invite, à l’image de l’interface des chatbots qui nous envahissent, et qui nous invitent justement à poser des questions – sans nécessairement en lire les réponses d’ailleurs. Est-ce vraiment une société de la question, de l’interrogation, quand, en fait, les réponses deviennent sans importance ?
Pascal Chabot : Quand j’évoque les sociétés de la question et de la réponse, j’évoque les sociétés modernes du XVIIe et du XVIIIe siècle, des sociétés où certaines choses ne s’interrogent pas, parce qu’il y a des réponses partout. La question du sens ne hante pas les grands penseurs de cette époque car pour eux, le sens est donné. Les sociétés de la question naissent de la mort de Dieu, de la perte de la transcendance et du fait qu’on n’écrit plus le sens en majuscule. Ce sont des sociétés de l’inquiétude et du questionnement. La question du sens de la vie est une question assez contemporaine finalement. C’est Nietzsche qui est un des premiers à la poser sous cette forme là.
Dans la société de la question dans laquelle nous entrons, on interroge les choses, le sens… Mais les réponses qui nous sont faites restent désincanées. Or, pour que le sens soit présent dans une existence, il faut qu’il y ait un enracinement, une incarnation… Il faut que le corps soit là pour que la signification soit comprise. Il faut une parole et pas seulement une information. De même, l’orientation, le chemin et son caractère initiatique comme déroutant, produisent du sens.
Mais, si nous le vivons ainsi c’est parce que nous avons vécu dans un monde de sensation, de signification et d’orientation relativement classique. Les plus jeunes n’ont pas nécessairement ces réflexes. Certains sont déjà couplés aux outils d’IA générative qui leurs servent de coach particuliers en continue… C’est un autre rapport au savoir qui arrive pour une génération qui n’a pas le rapport au savoir que nous avons construit.
Dans les algorithmes : Vous expliquez que cette extension du surconscient produit des pathologies que vous qualifiez de digitoses, pour parler d’un conflit entre la conscience et le surconscient. Mais pourquoi parlez-vous de digitose plutôt que de nouvelles névroses ou de nouvelles psychoses ?
Pascal Chabot : Quand j’ai travaillé sur la question du burn-out, j’ai pu constater que le domaine de la santé mentale devait évoluer. Les concepts classiques, de névrose ou de psychose, n’étaient plus opérants pour décrire ces nouvelles afflictions. Nous avions des notions orphelines d’une théorie plus englobante. Le burn-out ou l’éco-anxiété ne sont ni des névroses ni des psychoses. Pour moi, la santé mentale avait besoin d’un aggiornamento, d’une mise à jour. J’ai cherché des analogies entre inconscient et surconscient, le ça, le là, le refoulement et le défoulement… J’ai d’abord trouvé le terme de numérose avant de lui préféré le terme de digitose en référence au digital plus qu’au numérique. C’est un terme qui par son suffixe en tout cas ajoute un penchant pathologique au digital. Peu à peu, les digitoses se sont structurées en plusieurs familles : les digitoses de scission, d’avenir, de rivalité… qui m’ont permis de créer une typologie des problèmes liés à un rapport effréné ou sans conscience au numérique qui génère de nouveaux types de pathologies.
Dans les algorithmes : Le terme de digitose, plus que le lien avec le surconscient, n’accuse-t-il pas plus le messager que le message ? Sur l’éco-anxiété, l’information que l’on obtient via le numérique peut nous amener à cette nouvelle forme d’inquiétude sourde vis à vis du futur, mais on peut être éco-anxieux sans être connecté. Or, dans votre typologie des digitoses, c’est toujours le rapport au numérique qui semble mis au banc des accusés…
Pascal Chabot : Je ne voudrais pas donner l’impression que je confond le thermomètre et la maladie effectivement. Mais, quand même : le média est le message. Ce genre de pathologies là, qui concernent notre rapport au réel, arrivent dans un monde où le réel est connu et transformé par le numérique. Pour prendre l’exemple de l’éco-anxiété, on pourrait tout à fait faire remarquer qu’elle a existé avant internet. Le livre de Rachel Carson, Le printemps silencieux, par exemple, date des années 60.
Mais, ce qui est propre au monde numérique est qu’il a permis de populariser une connaissance de l’avenir que le monde d’autrefois ne connaissait absolument pas. L’avenir a toujours été le lieu de l’opacité, comblé par de grands récits mythiques ou apocalyptiques. Aujourd’hui, l’apport informationnel majeur du numérique, permet d’avoir pour chaque réalité un ensemble de statistiques prospectives extrêmement fiables. On peut trouver comment vont évoluer les populations d’insectes, la fonte des glaciers, les températures globales comme locales… Ce n’est pas uniquement le média numérique qui est mobilisé ici, mais la science, la technoscience, les calculateurs… c’est-à-dire la forme contemporaine du savoir. Les rapports du Giec en sont une parfaite illustration. Ils sont des éventails de scénarios chiffrés, sourcés, documentés… assortis de probabilités et validés collectivement. Ils font partie du surconscient, du dôme de savoir dans lequel nous évoluons et qui étend sa chape d’inquiétude et de soucis sur nos consciences. L’éco-anxiété est une digitose parce que c’est le branchement à ce surconscient là qui est important. Ce n’est pas uniquement la digitalisation de l’information qui est en cause, mais l’existence d’un contexte informationnel dont le numérique est le vecteur.
« Le numérique a permis de populariser une connaissance de l’avenir que le monde d’autrefois ne connaissait absolument pas »
Dans les algorithmes : Ce n’est pas le fait que ce soit numérique, c’est ce que ce branchement transforme en nous…
Pascal Chabot : Oui, c’est la même chose dans le monde du travail, par rapport à la question du burn-out… Nombre de burn-out sont liés à des facteurs extra-numériques qui vont des patrons chiants, aux collègues toxiques… et qui ont toujours existé, hélas. Mais dans la structure contemporaine du travail, dans son exigence, dans ce que les algorithmes font de notre rapport au système, au travail, à la société… ces nouveaux branchements, ce reporting constant, cette normalisation du travail… renforcent encore les souffrances que nous endurons.
« L’éco-anxiété est une digitose parce que c’est le branchement à ce surconscient là qui est important. Ce n’est pas uniquement la digitalisation de l’information qui est en cause, mais l’existence d’un contexte informationnel dont le numérique est le vecteur. »
Dans les algorithmes :Outre la digitose de scission (le burn-out), et la digitose d’avenir (l’éco-anxiété) dont vous nous avez parlé, vous évoquez aussi la digitose de rivalité, celle de notre confrontation à l’IA et de notre devenir machine. Expliquez-nous !
Pascal Chabot : Il faut partir de l’écriture pour la comprendre. Ce que l’on délègue à un chatbot, c’est de l’écriture. Bien sûr, elles peuvent générer bien d’autres choses, mais ce sont d’abord des machines qui ont appris à aligner des termes en suivant les grammaires pour produire des réponses sensées, c’est-à-dire qui font sens pour quelqu’un qui les lit. Ce qui est tout à fait perturbant, c’est que de cette sorte de graphogenèse, de genèse du langage graphique, naît quelque chose comme une psychogenèse. C’est simplement le bon alignement de termes qui répond à telle ou telle question qui nous donne l’impression d’une intentionnalité. Depuis que l’humanité est l’humanité, un terme écrit nous dit qu’il a été pensé par un autre. Notre rapport au signe attribue toujours une paternité. L’humanité a été créée par les Ecritures. Les sociétés religieuses, celles des grands monothéismes, sont des sociétés du livre. Être en train de déléguer l’écriture à des machines qui le feront de plus en plus correctement, est quelque chose d’absolument subjuguant. Le problème, c’est que l’humain est paresseux et que nous risquons de prendre cette voie facile. Nos consciences sont pourtant nées de l’écriture. Et voilà que désormais, elles se font écrire par des machines qui appartiennent à des ultraforces qui ont, elles, des visées politiques et économiques. Politique, car écrire la réponse à la question « la démocratie est-elle un bon régime ? » dépendra de qui relèvent de ces ultraforces. Économique, comme je m’en amusait dans L’homme qui voulait acheter le langage… car l’accès à ChatGPT est déjà payant et on peut imaginer que les accès à de meilleures versions demain, pourraient être plus chères encore. La capitalisme linguistique va continuer à se développer. L’écriture, qui a été un outil d’émancipation démocratique sans commune mesure (car apprendre à écrire a toujours été le marqueur d’entrée dans la société), risque de se transformer en simple outil de consommation. Outre la rivalité existentielle de l’IA qui vient dévaluer notre intelligence, les impacts politiques et économiques ne font que commencer. Pour moi, il y dans ce nouveau rapport quelque chose de l’ordre de la dépossession, d’une dépossession très très profonde de notre humanité.
Dans les algorithmes : Ecrire, c’est penser. Être déposséder de l’écriture, c’est être dépossédé de la pensée.
Pascal Chabot : Oui et cela reste assez vertigineux. Notamment pour ceux qui ont appris à manier l’écriture et la pensée. Ecrire, c’est s’emparer du langage pour lui injecter un rythme, une stylistique et une heuristique, c’est-à-dire un outil de découverte, de recherche, qui nous permet de stabiliser nos relations à nous-mêmes, à autrui, au savoir… Quand on termine un mail, on réfléchit à la formule qu’on veut adopter en fonction de la relation à l’autre que nous avons… jusqu’à ce que les machines prennent cela en charge. On a l’impression pour le moment d’être au stade de la rivalité entre peinture et photographie vers 1885. Souvenons-nous que la photographie a balayé le monde ancien.
Mais c’est un monde dont il faut reconnaître aussi les limites et l’obsolescence. Le problème des nouvelles formes qui viennent est que le sens qu’elles proposent est bien trop extérieur aux individus. On enlève l’individu au sens. On est dans des significations importées, dans des orientations qui ne sont pas vécues existentiellement.
Dans les algorithmes :Pour répondre aux pathologies des digitoses, vous nous invitez à une thérapie de civilisation. De quoi avons-nous besoin pour pouvoir répondre aux digitoses ?
Pascal Chabot : La conscience, le fait d’accompagner en conscience ce que nous faisons change la donne. Réfléchir sur le temps, prendre conscience de notre rapport temporel, change notre rapport au temps. Réfléchir à la question du sens permet de prendre une hauteur et de créer une série de filtres permettant de distinguer des actions insensées qui relèvent à la fois des grandes transcendance avec une majuscule que des conduites passives face au sens. La thérapie de la civilisation, n’est rien d’autre que la philosophie. C’est un plaidoyer pro domo ! Mais la philosophie permet de redoubler ce que nous vivons d’une sorte de conscience de ce que nous vivons : la réflexivité. Et cette façon de réfléchir permet d’évaluer et garder vive la question de l’insensé, de l’absurde et donc du sens.
Dans les algorithmes : Dans ce surconscient qui nous aplatit, comment vous situez-vous face aux injonctions à débrancher, à ne plus écouter la télévision, la radio, à débrancher les écrans ? Cela relève d’un levier, du coaching comportemental ou est-ce du meaning washing ?
Pascal Chabot : Je n’y crois pas trop. C’est comme manger des légumes ou faire pipi sous la douche. Les mouvements auxquels nous sommes confrontés sont bien plus profonds. Bien sûr, chacun s’adapte comme il peut. Je ne cherche pas à être jugeant. Mais cela nous rappelle d’ailleurs que la civilisation du livre et de l’écrit a fait beaucoup de dégâts. La conscience nous aide toujours à penser mieux. Rien n’est neutre. Confrontés aux ultraforces, on est dans un monde qui développe des anti-rapports, à la fois des dissonnances, des dénis ou des esquives pour tenter d’échapper à notre impuissance.
Dans les algorithmes : Vous êtes assez alarmiste sur les enjeux civilisationnels de l’intelligence artificielle que vous appelez très joliment des « communicants artificiels ». Et de l’autre, vous nous expliquez que ces outils vont continuer la démocratisation culturelle à l’œuvre. Vous rappelez d’ailleurs que le protestantisme est né de la généralisation de la lecture et vous posez la question : « que naîtra-t-il de la généralisation de l’écriture ? »
Mais est-ce vraiment une généralisation de l’écriture à laquelle nous assistons ? On parle de l’écriture de et par des machines. Et il n’est pas sûr que ce qu’elles produisent nous pénètrent, nous traversent, nous émancipent. Finalement, ce qu’elles produisent ne sont que des réponses qui ne nous investissent pas nécessairement. Elles font à notre place. Nous leur déléguons non seulement l’écriture, mais également la lecture… au risque d’abandonner les deux. Est-ce que ces outils produisent vraiment une nouvelle démocratisation culturelle ? Sommes-nous face à un nouvel outil interculturel ou assistons-nous simplement à une colonisation et une expansion du capitalisme linguistique ?
Pascal Chabot : L’écriture a toujours été une sorte de ticket d’entrée dans la société et selon les types d’écritures dont on était capable, on pouvait pénétrer dans tel ou tel milieu. L’écriture est très clairement un marqueur de discrimination sociale. C’est le cas de l’orthographe, très clairement, qui est la marque de niveaux d’éducation. Mais au-delà de l’orthographe, le fait de pouvoir rédiger un courrier, un CV… est quelque chose de très marqué socialement. Dans une formation à l’argumentation dans l’équivalent belge de France Travail, j’ai été marqué par le fait que pour les demandeurs d’emploi, l’accès à l’IA leur changeait la vie, leur permettant d’avoir des CV, des lettres de motivation adaptées. Pour eux, c’était un boulet de ne pas avoir de CV corrects. Même chose pour les étudiants. Pour nombre d’entre eux, écrire est un calvaire et ils savent très bien que c’est ce qu’ils ne savent pas toujours faire correctement. Dans ces nouveaux types de couplage que l’IA permet, branchés sur un surconscient qui les aide, ils ont accès à une assurance nouvelle.
Bien sûr, dans cette imitation, personne n’est dupe. Mais nous sommes conditionnés par une société qui attribue à l’auteur d’un texte les qualités de celui-ci, alors que ses productions ne sont pas que personnelles, elles sont d’abord le produit des classes sociales de leurs auteurs, de la société dont nous sommes issus. Dans ce nouveau couplage à l’IA, il me semble qu’il y a quelque chose de l’ordre d’une démocratisation.
Dans les algorithmes :Le risque avec l’IA, n’est-il pas aussi, derrière la dépossession de l’écriture, notre dépossession du sens lui-même ? Le sens nous est désormais imposé par d’autres, par les résultats des machines. Ce qui m’interroge beaucoup avec l’IA, c’est cette forme de délégation des significations, leur aplatissement, leur moyennisation. Quand on demande à ces outils de nous représenter un mexicain, ils nous livrent l’image d’une personne avec un sombrero ! Or, faire société, c’est questionner tout le temps les significations pour les changer, les modifier, les faire évoluer. Et là, nous sommes confrontés à des outils qui les figent, qui excluent ce qui permet de les remettre en cause, ce qui sort de la norme, de la moyenne…
Pascal Chabot : Oui, nous sommes confrontés à un « Bon gros bon sens » qui n’est pas sans rappeler Le dictionnaire des idées de reçues de Flaubert…
Dans les algorithmes :…mais le dictionnaire des idées reçues était ironique, lui !
Pascal Chabot : Il est ironique parce qu’il a vu l’humour dans le « Bon gros bon sens ». Dans la société, les platitudes circulent. C’est la tâche de la culture et de la créativité de les dépasser. Car le « Bon gros bon sens » est aussi très politique : il est aussi un sens commun, avec des assurances qui sont rabachées, des slogans répétés…. Les outils d’IA sont de nouveaux instruments de bon sens, notamment parce qu’ils doivent plaire au plus grand monde. On est très loin de ce qui est subtil, de ce qui est fin, polysémique, ambiguë, plein de doute, raffiné, étrange, surréaliste… C’est-à-dire tout ce qui fait la vie de la culture. On est plongé dans un pragmatisme anglo-saxon, qui a un rapport au langage très peu polysémique d’ailleurs. Le problème, c’est que ce « Bon gros bon sens » est beaucoup plus invasif. Il a une force d’autorité. Le produit de ChatGPT ne nous est-il pas présenté d’ailleurs comme un summum de la science ?
« Les outils d’IA sont de nouveaux instruments de bon sens, notamment parce qu’ils doivent plaire au plus grand monde. On est très loin de ce qui est subtil, de ce qui est fin, polysémique, ambiguë, plein de doute, raffiné, étrange, surréaliste… C’est-à-dire tout ce qui fait la vie de la culture. »
Dans les algorithmes : Et en même temps, ce calcul laisse bien souvent les gens sans prise, sans moyens d’action individuels comme collectifs.
Le point commun entre les différentes digitoses que vous listez me semble-t-il est que nous n’avons pas de réponses individuelles à leur apporter. Alors que les névroses et psychoses nécessitent notre implication pour être réparées. Face aux digitoses, nous n’avons pas de clefs, nous n’avons pas de prises, nous sommes sans moyen d’action individuels comme collectifs. Ne sommes nous pas confrontés à une surconscience qui nous démunie ?
Pascal Chabot : Il est certain que le couplage des consciences au surconscient, en tant qu’elle est un processus de civilisation, apparaît comme un nouveau destin. Il s’impose, piloté par des ultraforces sur lesquelles nous n’avons pas de prise. En ce sens, il s’agit d’un nouveau destin, avec tout ce que ce terme charrie d’imposition et d’inexorabilité.
En tant que les digitoses expriment le versant problématique de ce nouveau couplage, elles aussi ont quelque chose de fatal. Branchée à une réalité numérique qui la dépasse et la détermine, la conscience peine souvent à exprimer sa liberté, qui est pourtant son essence. La rivalité avec les IA, l’eco-anxiété, la scission avec le monde sensible : autant de digitoses qui ont un aspect civilisationnel, presque indépendant du libre-arbitre individuel. Les seules réponses, en l’occurrence, ne peuvent être que politiques. Mais là aussi, elles ne sont pas faciles à imaginer.
Or on ne peut pourtant en rester là. Si ce seul aspect nécessaire existait, toute cette théorie ne serait qu’une nouvelle formulation de l’aliénation. Mais les digitoses ont une composante psychologique, de même que les névroses et psychoses. Cette composante recèle aussi des leviers de résistance. La prise de conscience, la lucidité, la reappropriation, l’hygiène mentale, une certaine désintoxication, le choix de brancher sa conscience sur des réalités extra-numériques, et tant d’autres stratégies encore, voire tant d’autres modes de vies, peuvent très clairement tempérer l’emprise de ces digitoses sur l’humain. C’est dire que l’individu, face à ce nouveau destin civilisationnel, garde des marges de résistance qui, lorsqu’elles deviennent collectives, peuvent être puissantes.
Les digitoses sont donc un défi et un repoussoir : une occasion de chercher et d’affirmer des libertés nouvelles dans un monde où s’inventent sous nos yeux de nouveaux déterminismes.
Dans les algorithmes : Derrière le surconscient, le risque n’est-il pas que s’impose une forme de sur-autorité, de sur-vision… sur lesquelles, il sera difficile de créer des formes d’échappement, de subtilité, d’ambiguité. On a l’impression d’être confronté à une force politique qui ne dit pas son nom mais qui se donne un nouveau moyen de pouvoir…
Pascal Chabot : C’est clair que la question est celle du pouvoir, politique et économique. Les types de résistances sont extrêmement difficiles à inventer. C’est le propre du pouvoir de rendre la résistance à sa force difficile. On est confronté à un tel mélange de pragmatisme, de facilitation de la vie, de création d’une bulle de confort, d’une enveloppe où les réponses sont faciles et qui nous donnent accès à de nouveaux mondes, comme le montrait la question de la démocratisation qu’on évoquait à l’instant… que la servitude devient très peu apparente. Et la perte de subtilité et d’ambiguïté est peu vue, car les gains économiques supplantent ces pertes. Qui se rend compte de l’appauvrissement ? Il faut avoir un pied dans les formes culturelles précédentes pour cela. Quand les choses seront plus franches, ce que je redoute, c’est que nos démocraties ne produisent pas de récits numériques pour faire entendre une autre forme de puissance.
Dans les algorithmes :En 2016 vous avez publié, ChatBot le robot, une très courte fable écrite bien avant l’avènement de l’IA générative, qui met en scène un jury de philosophes devant décider si une intelligence artificielle est capable de philosopher. Ce petit drame philosophique où l’IA fomente des réponses à des questions philosophiques, se révèle très actuel 9 ans plus tard. Qualifieriez vous ChatGPT et ses clones de philosophes ?
Pascal Chabot : Je ne suis pas sûr. Je ne suis pas sûr que ce chatbot là se le décernerait à lui, comme il est difficile à un artiste de se dire artiste. Mon Chatbot était un récalcitrant, ce n’est pas le cas des outils d’IA d’aujourd’hui. Il leur manque un rapport au savoir, le lien entre la sensation et la signification. La philosophie ne peut pas être juste de la signification. Et c’est pour cela que l’existentialisme reste la matrice de toute philosophie, et qu’il n’y a pas de philosophie qui serait non-existentielle, c’est-à-dire pure création de langage. La graphogenèse engendre une psychogenèse. Mais la psychogenèse, cette imitation de la conscience, n’engendre ni philosophie ni pensée humaine. Il n’y a pas de conscience artificielle. La conscience est liée à la naissance, la mort, la vie.
Dans les algorithmes :La question de l’incalculabitéest le sujet de la conférence USI 2025 à laquelle vous allez participer. Pour un un philosophe, qu’est-ce qui est incalculable ?
Pascal Chabot : L’incalculable, c’est le subtil ! L’étymologie de subtil, c’est subtela, littéralement, ce qui est en-dessous d’une toile. En dessous d’une toile sur laquelle on tisse, il y a évidémment la trame, les fils de trame. Le subtil, c’est les fils de trame, c’est-à-dire nos liens majeurs, les liens à nous-mêmes, aux autres, au sens, à la culture, nos liens amoureux, amicaux… Et tout cela est profondément de l’ordre de l’incalculable. Et tout cela est même profané quand on les calcule. Ces liens sont ce qui résiste intrinsèquement à la calculabilité, qui est pourtant l’un des grands ressort de l’esprit humain et pas seulement des machines. Le problème, c’est qu’on est tellement dans une idéologie de la calculabilité qu’on ne perçoit même plus qu’on peut faire des progrès dans le domaine du subtil. Désormais, le progrès semble lié à la seule calculabilité. Le progrès est un progrès du calculable et de l’utile. Or, je pense qu’il existe aussi un progrès dans le domaine du subtil. Dans l’art d’être ami par exemple, dans l’art d’être lié à soi-même ou aux autres, il y a moyen de faire des progrès. Il y a là toute une zone de développement, de progrès (nous ne devons pas laisser le terme uniquement à la civilisation techno-économique), de progrès subtil. Un progrès subtil, incalculable, mais extrêmement précieux.
Propos recueillis par Hubert Guillaud.
Pascal Chabot sera l’un des intervenants de la conférence USI 2025 qui aura lieu lundi 2 juin à Paris et dont le thème est « la part incalculable du numérique » et pour laquelle Danslesalgorithmes.net est partenaire.
Les tarifs des études dans les grandes universités américaines sont très élevés et les établissements se livrent à une concurrence féroce que ce soit pour fixer les prix des frais de scolarité comme pour fixer les réductions qu’elles distribuent sous forme de bourses. Ces réductions peuvent être considérables : en moyenne, elles permettent de réduire le prix de plus de 56% pour les nouveaux étudiants et peuvent monter jusqu’à six chiffres sur le coût total des études. Or, explique Ron Lieber, po
Les tarifs des études dans les grandes universités américaines sont très élevés et les établissements se livrent à une concurrence féroce que ce soit pour fixer les prix des frais de scolarité comme pour fixer les réductions qu’elles distribuent sous forme de bourses. Ces réductions peuvent être considérables : en moyenne, elles permettent de réduire le prix de plus de 56% pour les nouveaux étudiants et peuvent monter jusqu’à six chiffres sur le coût total des études. Or, explique Ron Lieber, pour le New York Times, les prix comme les réductions dépendent de calculs complexes, d’algorithmes opaques, mis au point discrètement depuis des décennies par des cabinets de conseil opérant dans l’ombre, notamment EAB et Ruffalo Noel Levitz (RNL) qui appartiennent à des sociétés de capital-investissement.
Lieber raconte la mise au point d’un algorithme dédié au Boston College par Jack Maguire dans les années 70, visant à accorder des réductions ciblées sur la base de la qualité des candidats plutôt que sur leurs moyens financiers, dans le but que nombre d’entre eux acceptent l’offre d’étude qui leur sera faite. Les sociétés qui proposent des algorithmes parlent, elles, “d’optimisation de l’aide financière”. Pour cela, elles utilisent les données sociodémographiques que les étudiants remplissent lors d’une demande d’information. S’ensuit des échanges numériques nourris entre universités et candidats pour évaluer leur engagement en mesurant tout ce qui est mesurable : clics d’ouvertures aux messages qui leurs sont adressés, nombre de secondes passées sur certaines pages web. L’EAB utilise plus de 200 variables pour fixer le prix d’admission en s’appuyant sur les données de plus de 350 clients et plus de 1,5 milliard d’interactions avec des étudiants. Pour chaque profil, des matrices sont produites mesurant à la fois la capacité de paiement et évaluant la réussite scolaire du candidat avant que les écoles ne fassent une offre initiale qui évolue au gré des discussions avec les familles. L’article évoque par exemple un établissement qui “a offert aux étudiants provenant d’autres Etats une réduction trois fois supérieure au prix catalogue par étudiant par rapport à celle proposée aux étudiants de l’Etat, tout en leur faisant payer le double du prix net”. Le but de l’offre était de les attirer en leur faisant une proposition qu’ils ne pouvaient pas refuser.
Mais contrairement à ce que l’on croit, les « bourses » ne sont pas que des bourses sur critères sociaux. C’est même de moins en moins le cas. Bien souvent, les universités proposent des bourses à des gens qui n’en ont pas besoin, comme une forme de remise tarifaire. En fait, la concurrence pour attirer les étudiants capables de payer est très forte, d’où l’enjeu à leur offrir des remises convaincantes, et les familles ont vite compris qu’elles pouvaient jouer de cette concurrence. En fait, constate une responsable administrative : “je pensais que l’aide financière servait à améliorer l’accès, mais ce n’est plus le cas. C’est devenu un modèle économique.” Les bourses ne servent plus tant à permettre aux plus démunis d’accéder à l’université, qu’à moduler la concurrence inter-établissement, à chasser les étudiants qui ont les capacités de payer.
En 2023, EAB a lancé Appily, un portail universitaire grand public à l’ambiance positive, une plateforme de mise en relation entre futurs étudiants à la manière d’une application de rencontre qui compte déjà 3 millions d’utilisateurs. Le recrutement d’étudiants est en passe de devenir de plus en plus concurrentiel à l’heure où les financements des universités s’apprêtent à se tarit sous les coupes de l’administration Trump et où la venue d’étudiants étrangers devient extrêmement difficile du fait des nouvelles politiques d’immigration mises en place. Comme on le constatait dans d’autres rapports tarifaires, dans les études supérieures également, le marketing numérique a pris le contrôle : là encore, le meilleur prix est devenu celui que les étudiants et les familles sont prêts à payer.
Les tarifs des études dans les grandes universités américaines sont très élevés et les établissements se livrent à une concurrence féroce que ce soit pour fixer les prix des frais de scolarité comme pour fixer les réductions qu’elles distribuent sous forme de bourses. Ces réductions peuvent être considérables : en moyenne, elles permettent de réduire le prix de plus de 56% pour les nouveaux étudiants et peuvent monter jusqu’à six chiffres sur le coût total des études. Or, explique Ron Lieber, po
Les tarifs des études dans les grandes universités américaines sont très élevés et les établissements se livrent à une concurrence féroce que ce soit pour fixer les prix des frais de scolarité comme pour fixer les réductions qu’elles distribuent sous forme de bourses. Ces réductions peuvent être considérables : en moyenne, elles permettent de réduire le prix de plus de 56% pour les nouveaux étudiants et peuvent monter jusqu’à six chiffres sur le coût total des études. Or, explique Ron Lieber, pour le New York Times, les prix comme les réductions dépendent de calculs complexes, d’algorithmes opaques, mis au point discrètement depuis des décennies par des cabinets de conseil opérant dans l’ombre, notamment EAB et Ruffalo Noel Levitz (RNL) qui appartiennent à des sociétés de capital-investissement.
Lieber raconte la mise au point d’un algorithme dédié au Boston College par Jack Maguire dans les années 70, visant à accorder des réductions ciblées sur la base de la qualité des candidats plutôt que sur leurs moyens financiers, dans le but que nombre d’entre eux acceptent l’offre d’étude qui leur sera faite. Les sociétés qui proposent des algorithmes parlent, elles, “d’optimisation de l’aide financière”. Pour cela, elles utilisent les données sociodémographiques que les étudiants remplissent lors d’une demande d’information. S’ensuit des échanges numériques nourris entre universités et candidats pour évaluer leur engagement en mesurant tout ce qui est mesurable : clics d’ouvertures aux messages qui leurs sont adressés, nombre de secondes passées sur certaines pages web. L’EAB utilise plus de 200 variables pour fixer le prix d’admission en s’appuyant sur les données de plus de 350 clients et plus de 1,5 milliard d’interactions avec des étudiants. Pour chaque profil, des matrices sont produites mesurant à la fois la capacité de paiement et évaluant la réussite scolaire du candidat avant que les écoles ne fassent une offre initiale qui évolue au gré des discussions avec les familles. L’article évoque par exemple un établissement qui “a offert aux étudiants provenant d’autres Etats une réduction trois fois supérieure au prix catalogue par étudiant par rapport à celle proposée aux étudiants de l’Etat, tout en leur faisant payer le double du prix net”. Le but de l’offre était de les attirer en leur faisant une proposition qu’ils ne pouvaient pas refuser.
Mais contrairement à ce que l’on croit, les « bourses » ne sont pas que des bourses sur critères sociaux. C’est même de moins en moins le cas. Bien souvent, les universités proposent des bourses à des gens qui n’en ont pas besoin, comme une forme de remise tarifaire. En fait, la concurrence pour attirer les étudiants capables de payer est très forte, d’où l’enjeu à leur offrir des remises convaincantes, et les familles ont vite compris qu’elles pouvaient jouer de cette concurrence. En fait, constate une responsable administrative : “je pensais que l’aide financière servait à améliorer l’accès, mais ce n’est plus le cas. C’est devenu un modèle économique.” Les bourses ne servent plus tant à permettre aux plus démunis d’accéder à l’université, qu’à moduler la concurrence inter-établissement, à chasser les étudiants qui ont les capacités de payer.
En 2023, EAB a lancé Appily, un portail universitaire grand public à l’ambiance positive, une plateforme de mise en relation entre futurs étudiants à la manière d’une application de rencontre qui compte déjà 3 millions d’utilisateurs. Le recrutement d’étudiants est en passe de devenir de plus en plus concurrentiel à l’heure où les financements des universités s’apprêtent à se tarit sous les coupes de l’administration Trump et où la venue d’étudiants étrangers devient extrêmement difficile du fait des nouvelles politiques d’immigration mises en place. Comme on le constatait dans d’autres rapports tarifaires, dans les études supérieures également, le marketing numérique a pris le contrôle : là encore, le meilleur prix est devenu celui que les étudiants et les familles sont prêts à payer.
« La crise de l’emploi via l’IA est arrivée. Elle est là, maintenant. Elle ne ressemble simplement pas à ce que beaucoup attendaient.
La crise de l’emploi dans l’IA ne ressemble pas, comme je l’ai déjà écrit, à l’apparition de programmes intelligents partout autour de nous, remplaçant inexorablement et massivement les emplois humains. Il s’agit d’une série de décisions managériales prises par des dirigeants cherchant à réduire les coûts de main-d’œuvre et à consolider le contrôle de leurs org
« La crise de l’emploi via l’IA est arrivée. Elle est là, maintenant. Elle ne ressemble simplement pas à ce que beaucoup attendaient.
La crise de l’emploi dans l’IA ne ressemble pas, comme je l’ai déjà écrit, à l’apparition de programmes intelligents partout autour de nous, remplaçant inexorablement et massivement les emplois humains. Il s’agit d’une série de décisions managériales prises par des dirigeants cherchant à réduire les coûts de main-d’œuvre et à consolider le contrôle de leurs organisations. La crise de l’emploi dans l’IA n’est pas une apocalypse d’emplois robotisés à la SkyNet : c’est le Doge qui licencie des dizaines de milliers d’employés fédéraux sous couvert d’une « stratégie IA prioritaire ».
La crise de l’emploi dans l’IA ne se résume pas au déplacement soudain de millions de travailleurs d’un seul coup ; elle se manifeste plutôt par l’attrition dans les industries créatives, la baisse des revenus des artistes, écrivains et illustrateurs indépendants, et par la propension des entreprises à embaucher moins de travailleurs humains.
En d’autres termes, la crise de l’emploi dans l’IA est davantage une crise de la nature et de la structure du travail qu’une simple tendance émergeant des données économiques », explique Brian Merchant. « Les patrons ont toujours cherché à maximiser leurs profits en utilisant des technologies de réduction des coûts. Et l’IA générative a été particulièrement efficace pour leur fournir un argumentaire pour y parvenir, et ainsi justifier la dégradation, la déresponsabilisation ou la destruction d’emplois précaires ». Le Doge en est une parfaite illustration : « il est présenté comme une initiative de réduction des coûts visant à générer des gains d’efficacité, mais il détruit surtout massivement des moyens de subsistance et érode le savoir institutionnel ».
« On entend souvent dire que l’IA moderne était censée automatiser les tâches rébarbatives pour que nous puissions tous être plus créatifs, mais qu’au lieu de cela, elle est utilisée pour automatiser les tâches créatives ». Pourquoi ? Parce que l’IA générative reste performante pour « certaines tâches qui ne nécessitent pas une fiabilité constante, ce qui explique que ses fournisseurs ciblent les industries artistiques et créatives ».
Luis von Ahn, PDG milliardaire de la célèbre application d’apprentissage des langues Duolingo, a annoncé que son entreprise allait officiellement être axée sur l’IA. Mais ce n’est pas nouveau, voilà longtemps que la startup remplace ses employés par de l’IA. En réalité, les employés ne cessent de corriger les contenus produits par l’IA au détriment du caractère original et de la qualité.
« La crise de l’emploi via l’IA est arrivée. Elle est là, maintenant. Elle ne ressemble simplement pas à ce que beaucoup attendaient.
La crise de l’emploi dans l’IA ne ressemble pas, comme je l’ai déjà écrit, à l’apparition de programmes intelligents partout autour de nous, remplaçant inexorablement et massivement les emplois humains. Il s’agit d’une série de décisions managériales prises par des dirigeants cherchant à réduire les coûts de main-d’œuvre et à consolider le contrôle de leurs org
« La crise de l’emploi via l’IA est arrivée. Elle est là, maintenant. Elle ne ressemble simplement pas à ce que beaucoup attendaient.
La crise de l’emploi dans l’IA ne ressemble pas, comme je l’ai déjà écrit, à l’apparition de programmes intelligents partout autour de nous, remplaçant inexorablement et massivement les emplois humains. Il s’agit d’une série de décisions managériales prises par des dirigeants cherchant à réduire les coûts de main-d’œuvre et à consolider le contrôle de leurs organisations. La crise de l’emploi dans l’IA n’est pas une apocalypse d’emplois robotisés à la SkyNet : c’est le Doge qui licencie des dizaines de milliers d’employés fédéraux sous couvert d’une « stratégie IA prioritaire ».
La crise de l’emploi dans l’IA ne se résume pas au déplacement soudain de millions de travailleurs d’un seul coup ; elle se manifeste plutôt par l’attrition dans les industries créatives, la baisse des revenus des artistes, écrivains et illustrateurs indépendants, et par la propension des entreprises à embaucher moins de travailleurs humains.
En d’autres termes, la crise de l’emploi dans l’IA est davantage une crise de la nature et de la structure du travail qu’une simple tendance émergeant des données économiques », explique Brian Merchant. « Les patrons ont toujours cherché à maximiser leurs profits en utilisant des technologies de réduction des coûts. Et l’IA générative a été particulièrement efficace pour leur fournir un argumentaire pour y parvenir, et ainsi justifier la dégradation, la déresponsabilisation ou la destruction d’emplois précaires ». Le Doge en est une parfaite illustration : « il est présenté comme une initiative de réduction des coûts visant à générer des gains d’efficacité, mais il détruit surtout massivement des moyens de subsistance et érode le savoir institutionnel ».
« On entend souvent dire que l’IA moderne était censée automatiser les tâches rébarbatives pour que nous puissions tous être plus créatifs, mais qu’au lieu de cela, elle est utilisée pour automatiser les tâches créatives ». Pourquoi ? Parce que l’IA générative reste performante pour « certaines tâches qui ne nécessitent pas une fiabilité constante, ce qui explique que ses fournisseurs ciblent les industries artistiques et créatives ».
Luis von Ahn, PDG milliardaire de la célèbre application d’apprentissage des langues Duolingo, a annoncé que son entreprise allait officiellement être axée sur l’IA. Mais ce n’est pas nouveau, voilà longtemps que la startup remplace ses employés par de l’IA. En réalité, les employés ne cessent de corriger les contenus produits par l’IA au détriment du caractère original et de la qualité.
Dans une tribune pour Tech Policy Press, l’anthropologue Corinne Cath revient sur la montée de la prise de conscience de la dépendance européenne aux clouds américains. Aux Pays-Bas, le projet de transfert des processus d’enregistrements des noms de domaines nationaux « .nl » sur Amazon Web Services, a initié une réflexion nationale sur l’indépendance des infrastructures, sur laquelle la chercheuse a publié un rapport via son laboratoire, le Critical infrastructure Lab. Cette migration a finalem
Dans une tribune pour Tech Policy Press, l’anthropologue Corinne Cath revient sur la montée de la prise de conscience de la dépendance européenne aux clouds américains. Aux Pays-Bas, le projet de transfert des processus d’enregistrements des noms de domaines nationaux « .nl » sur Amazon Web Services, a initié une réflexion nationale sur l’indépendance des infrastructures, sur laquelle la chercheuse a publié un rapport via son laboratoire, le Critical infrastructure Lab. Cette migration a finalement été stoppée par les politiciens néerlandais au profit de réponses apportées par les fournisseurs locaux.
Ces débats relatifs à la souveraineté sont désormais présents dans toute l’Europe, remarque-t-elle, à l’image du projet EuroStack, qui propose de développer une « souveraineté technologique européenne ». Son initiatrice, Francesca Bria, plaide pour la création d’un un Fonds européen pour la souveraineté technologique doté de 10 milliards d’euros afin de soutenir cette initiative, ainsi que pour des changements politiques tels que la priorité donnée aux technologies européennes dans les marchés publics, l’encouragement de l’adoption de l’open source et la garantie de l’interopérabilité. Ce projet a reçu le soutien d’entreprises européennes, qui alertent sur la crise critique de dépendance numérique qui menace la souveraineté et l’avenir économique de l’Europe.
La chercheuse souligne pourtant pertinemment le risque d’une défense uniquement souverainiste, consistant à construire des clones des services américains, c’est-à-dire un remplacement par des équivalents locaux. Pour elle, il est nécessaire de « repenser radicalement l’économie politique sous-jacente qui façonne le fonctionnement des systèmes numériques et leurs bénéficiaires ». Nous devons en profiter pour repenser la position des acteurs. Quand les acteurs migrent leurs infrastructure dans les nuages américains, ils ne font pas que déplacer leurs besoins informatiques, bien souvent ils s’adaptent aussi à des changements organisationnels, liés à l’amenuisements de leurs compétences techniques. Un cloud souverain européen ou national n’adresse pas l’enjeu de perte de compétences internes que le cloud tiers vient soulager. L’enjeu n’est pas de choisir un cloud plutôt qu’un autre, mais devrait être avant tout de réduire la dépendance des services aux clouds, quels qu’ils soient. Des universitaires des universités d’Utrecht et d’Amsterdam ont ainsi appelé leurs conseils d’administration, non pas à trouver des solutions de clouds souverains, mais à réduire la dépendance des services aux services en nuage. Pour eux, la migration vers le cloud transforme les universités « d’une source d’innovation technique et de diffusion de connaissances en consommateurs de services ».
Les initiatives locales, même très bien financées, ne pourront jamais concurrencer les services en nuage des grands acteurs du numérique américain, rappelle Corinne Cath. Les remplacer par des offres locales équivalentes ne peut donc pas être l’objectif. Le concept de souveraineté numérique produit un cadrage nationaliste voire militariste qui peut-être tout aussi préjudiciable à l’intérêt général que l’autonomie technologique pourrait souhaiter porter. Nous n’avons pas besoin de cloner les services en nuage américains, mais « de développer une vision alternative du rôle de l’informatique dans la société, qui privilégie l’humain sur la maximisation du profit ». Ce ne sont pas seulement nos dépendances technologiques que nous devons résoudre, mais également concevoir et financer des alternatives qui portent d’autres valeurs que celles de l’économie numérique américaine. « Les systèmes et les économies fondés sur les principes de suffisance, de durabilité, d’équité et de droits humains, plutôt que sur l’abondance informatique et l’expansion des marchés, offrent une voie plus prometteuse ».
Dans une tribune pour Tech Policy Press, l’anthropologue Corinne Cath revient sur la montée de la prise de conscience de la dépendance européenne aux clouds américains. Aux Pays-Bas, le projet de transfert des processus d’enregistrements des noms de domaines nationaux « .nl » sur Amazon Web Services, a initié une réflexion nationale sur l’indépendance des infrastructures, sur laquelle la chercheuse a publié un rapport via son laboratoire, le Critical infrastructure Lab. Cette migration a finalem
Dans une tribune pour Tech Policy Press, l’anthropologue Corinne Cath revient sur la montée de la prise de conscience de la dépendance européenne aux clouds américains. Aux Pays-Bas, le projet de transfert des processus d’enregistrements des noms de domaines nationaux « .nl » sur Amazon Web Services, a initié une réflexion nationale sur l’indépendance des infrastructures, sur laquelle la chercheuse a publié un rapport via son laboratoire, le Critical infrastructure Lab. Cette migration a finalement été stoppée par les politiciens néerlandais au profit de réponses apportées par les fournisseurs locaux.
Ces débats relatifs à la souveraineté sont désormais présents dans toute l’Europe, remarque-t-elle, à l’image du projet EuroStack, qui propose de développer une « souveraineté technologique européenne ». Son initiatrice, Francesca Bria, plaide pour la création d’un un Fonds européen pour la souveraineté technologique doté de 10 milliards d’euros afin de soutenir cette initiative, ainsi que pour des changements politiques tels que la priorité donnée aux technologies européennes dans les marchés publics, l’encouragement de l’adoption de l’open source et la garantie de l’interopérabilité. Ce projet a reçu le soutien d’entreprises européennes, qui alertent sur la crise critique de dépendance numérique qui menace la souveraineté et l’avenir économique de l’Europe.
La chercheuse souligne pourtant pertinemment le risque d’une défense uniquement souverainiste, consistant à construire des clones des services américains, c’est-à-dire un remplacement par des équivalents locaux. Pour elle, il est nécessaire de « repenser radicalement l’économie politique sous-jacente qui façonne le fonctionnement des systèmes numériques et leurs bénéficiaires ». Nous devons en profiter pour repenser la position des acteurs. Quand les acteurs migrent leurs infrastructure dans les nuages américains, ils ne font pas que déplacer leurs besoins informatiques, bien souvent ils s’adaptent aussi à des changements organisationnels, liés à l’amenuisements de leurs compétences techniques. Un cloud souverain européen ou national n’adresse pas l’enjeu de perte de compétences internes que le cloud tiers vient soulager. L’enjeu n’est pas de choisir un cloud plutôt qu’un autre, mais devrait être avant tout de réduire la dépendance des services aux clouds, quels qu’ils soient. Des universitaires des universités d’Utrecht et d’Amsterdam ont ainsi appelé leurs conseils d’administration, non pas à trouver des solutions de clouds souverains, mais à réduire la dépendance des services aux services en nuage. Pour eux, la migration vers le cloud transforme les universités « d’une source d’innovation technique et de diffusion de connaissances en consommateurs de services ».
Les initiatives locales, même très bien financées, ne pourront jamais concurrencer les services en nuage des grands acteurs du numérique américain, rappelle Corinne Cath. Les remplacer par des offres locales équivalentes ne peut donc pas être l’objectif. Le concept de souveraineté numérique produit un cadrage nationaliste voire militariste qui peut-être tout aussi préjudiciable à l’intérêt général que l’autonomie technologique pourrait souhaiter porter. Nous n’avons pas besoin de cloner les services en nuage américains, mais « de développer une vision alternative du rôle de l’informatique dans la société, qui privilégie l’humain sur la maximisation du profit ». Ce ne sont pas seulement nos dépendances technologiques que nous devons résoudre, mais également concevoir et financer des alternatives qui portent d’autres valeurs que celles de l’économie numérique américaine. « Les systèmes et les économies fondés sur les principes de suffisance, de durabilité, d’équité et de droits humains, plutôt que sur l’abondance informatique et l’expansion des marchés, offrent une voie plus prometteuse ».
Depuis 2018, l’administration brésilienne s’est mise à l’IA pour examiner les demandes de prestations sociales, avec pour objectif que 55% des demandes d’aides sociales soient automatisées d’ici la fin 2025. Problème : au Brésil comme partout ailleurs, le système dysfonctionne et rejette de nombreuses demandes à tort, rapporte Rest of the World, notamment celles de travailleurs ruraux pauvres dont les situations sont souvent aussi complexes que les règles de calcul de la sécurité sociale à leur
Depuis 2018, l’administration brésilienne s’est mise à l’IA pour examiner les demandes de prestations sociales, avec pour objectif que 55% des demandes d’aides sociales soient automatisées d’ici la fin 2025. Problème : au Brésil comme partout ailleurs, le système dysfonctionne et rejette de nombreuses demandes à tort, rapporte Rest of the World, notamment celles de travailleurs ruraux pauvres dont les situations sont souvent aussi complexes que les règles de calcul de la sécurité sociale à leur égard. « Les utilisateurs mécontents des décisions peuvent faire appel auprès d’un comité interne de ressources juridiques, ce qui doit également se faire via l’application de la sécurité sociale brésilienne. Le délai moyen d’attente pour obtenir une réponse est de 278 jours ».
Depuis 2018, l’administration brésilienne s’est mise à l’IA pour examiner les demandes de prestations sociales, avec pour objectif que 55% des demandes d’aides sociales soient automatisées d’ici la fin 2025. Problème : au Brésil comme partout ailleurs, le système dysfonctionne et rejette de nombreuses demandes à tort, rapporte Rest of the World, notamment celles de travailleurs ruraux pauvres dont les situations sont souvent aussi complexes que les règles de calcul de la sécurité sociale à leur
Depuis 2018, l’administration brésilienne s’est mise à l’IA pour examiner les demandes de prestations sociales, avec pour objectif que 55% des demandes d’aides sociales soient automatisées d’ici la fin 2025. Problème : au Brésil comme partout ailleurs, le système dysfonctionne et rejette de nombreuses demandes à tort, rapporte Rest of the World, notamment celles de travailleurs ruraux pauvres dont les situations sont souvent aussi complexes que les règles de calcul de la sécurité sociale à leur égard. « Les utilisateurs mécontents des décisions peuvent faire appel auprès d’un comité interne de ressources juridiques, ce qui doit également se faire via l’application de la sécurité sociale brésilienne. Le délai moyen d’attente pour obtenir une réponse est de 278 jours ».
A l’heure où, aux Etats-Unis, le FBI, les services d’immigration et de police se mettent à poursuivre les ressortissants étrangers pour les reconduire aux frontières, sur Tech Policy Press, l’activiste Dia Kayyali rappelle que les Etats-Unis ont une longue histoire de chasse aux opposants politiques et aux étrangers. Du MacCarthysme au 11 septembre, les crises politiques ont toujours renforcé la surveillance des citoyens et plus encore des ressortissants d’origine étrangère. Le Brennan Center fo
A l’heure où, aux Etats-Unis, le FBI, les services d’immigration et de police se mettent à poursuivre les ressortissants étrangers pour les reconduire aux frontières, sur Tech Policy Press, l’activiste Dia Kayyali rappelle que les Etats-Unis ont une longue histoire de chasse aux opposants politiques et aux étrangers. Du MacCarthysme au 11 septembre, les crises politiques ont toujours renforcé la surveillance des citoyens et plus encore des ressortissants d’origine étrangère. Le Brennan Center for Justice a publié en 2022 un rapport sur la montée de l’utilisation des réseaux sociaux dans ces activités de surveillance et rappelle que ceux-ci sont massivement mobilisés pour la surveillance des opposants politiques, notamment depuis Occupy et depuis 2014 pour le contrôle des demandes d’immigration et les contrôles aux frontières, rappelle The Verge.
Le premier projet de loi du second mandat de Donald Trump était un texte concernant l’immigration clandestine, nous rappelle Le Monde. C’est un texte qui propose la détention automatique par les forces de l’ordre fédérales de migrants en situation irrégulière qui ont été accusés, condamnés ou inculpés pour certains délits, mêmes mineurs, comme le vol à l’étalage.
La lutte contre l’immigration est au cœur de la politique du président américain, qui dénonce une “invasion” et annonce vouloir déporter 11 millions d’immigrants illégaux, au risque que le tissu social des Etats-Unis, nation d’immigrants, se déchire, rappelait The Guardian. Dès janvier, l’administration Trump a mis fin à l’application CBP One, seule voie pour les demandeurs d’asile désirant entrer légalement sur le territoire des Etats-Unis pour prendre rendez-vous avec l’administration douanière américaine et régulariser leur situation. La suppression unilatérale de l’application a laissé tous les demandeurs d’asile en attente d’un rendez-vous sans recours, rapportait Le Monde.
Une opération de fusion des informations sans précédent
Cette politique est en train de s’accélérer, notamment en mobilisant toutes les données numériques à sa disposition, rapporte Wired. Le Doge est en train de construire une base de données dédiée aux étrangers, collectant les données de plusieurs administrations, afin de créer un outil de surveillance d’une portée sans précédent. L’enjeu est de recouper toutes les données disponibles, non seulement pour mieux caractériser les situations des étrangers en situation régulière comme irrégulière, mais également les géolocaliser afin d’aider les services de police chargés des arrestations et de la déportation, d’opérer.
Jusqu’à présent, il existait d’innombrables bases de données disparates entre les différentes agences et au sein des agences. Si certaines pouvaient être partagées, à des fins policières, celles-ci n’ont jamais été regroupées par défaut, parce qu’elles sont souvent utilisées à des fins spécifiques. Le service de l’immigration et des douanes (ICE, Immigration and Customs Enforcement) et le département d’investigation de la sécurité intérieure (HSI, Homeland Security Investigations), par exemple, sont des organismes chargés de l’application de la loi et ont parfois besoin d’ordonnances du tribunal pour accéder aux informations sur un individu dans le cadre d’enquêtes criminelles, tandis que le service de citoyenneté et d’immigration des États-Unis (USCIS, United States Citizenship and Immigration Services) des États-Unis collecte des informations sensibles dans le cadre de la délivrance régulière de visas et de cartes vertes.
Des agents du Doge ont obtenu l’accès aux systèmes de l’USCIS. Ces bases de données contiennent des informations sur les réfugiés et les demandeurs d’asile, des données sur les titulaires de cartes vertes, les citoyens américains naturalisés et les bénéficiaires du programme d’action différée pour les arrivées d’enfants. Le Doge souhaite également télécharger des informations depuis les bases de données de myUSCIS, le portail en ligne où les immigrants peuvent déposer des demandes, communiquer avec l’USCIS, consulter l’historique de leurs demandes et répondre aux demandes de preuves à l’appui de leur dossier. Associées aux informations d’adresse IP des personnes qui consultent leurs données, elles pourraient servir à géolocaliser les immigrants.
Le département de sécurité intérieur (DHS, Department of Homeland Security) dont dépendent certaines de ces agences a toujours été très prudent en matière de partage de données. Ce n’est plus le cas. Le 20 mars, le président Trump a d’ailleurs signé un décret exigeant que toutes les agences fédérales facilitent « le partage intra- et inter-agences et la consolidation des dossiers non classifiés des agences », afin d’entériner la politique de récupération de données tout azimut du Doge. Jusqu’à présent, il était historiquement « extrêmement difficile » d’accéder aux données que le DHS possédait déjà dans ses différents départements. L’agrégation de toutes les données disponibles « représenterait une rupture significative dans les normes et les politiques en matière de données », rappelle un expert. Les agents du Doge ont eu accès à d’innombrables bases, comme à Save, un système de l’USCIS permettant aux administrations locales et étatiques, ainsi qu’au gouvernement fédéral, de vérifier le statut d’immigration d’une personne. Le Doge a également eu accès à des données de la sécurité sociale et des impôts pour recouper toutes les informations disponibles.
Le problème, c’est que la surveillance et la protection des données est également rendue plus difficile. Les coupes budgétaires et les licenciements ont affecté trois services clés qui constituaient des garde-fous importants contre l’utilisation abusive des données par les services fédéraux, à savoir le Bureau des droits civils et des libertés civiles (CRCL, Office for Civil Rights and Civil Liberties), le Bureau du médiateur chargé de la détention des immigrants et le Bureau du médiateur des services de citoyenneté et d’immigration. Le CRCL, qui enquête sur d’éventuelles violations des droits de l’homme par le DHS et dont la création a été mandatée par le Congrès est depuis longtemps dans le collimateur du Doge.
Le 5 avril, le DHS a conclu un accord avec les services fiscaux (IRS) pour utiliser les données fiscales. Plus de sept millions de migrants travaillent et vivent aux États-Unis. L’ICE a également récemment versé des millions de dollars à l’entreprise privée Palantir pour mettre à jour et modifier une base de données de l’ICE destinée à traquer les immigrants, a rapporté 404 Media. Le Washington Post a rapporté également que des représentants de Doge au sein d’agences gouvernementales – du Département du Logement et du Développement urbain à l’Administration de la Sécurité sociale – utilisent des données habituellement confidentielles pour identifier les immigrants sans papiers. Selon Wired, au Département du Travail, le Doge a obtenu l’accès à des données sensibles sur les immigrants et les ouvriers agricoles. La fusion de toutes les données entre elles pour permettre un accès panoptique aux informations est depuis l’origine le projet même du ministère de l’efficacité américain, qui espère que l’IA va lui permettre de rendre le traitement omniscient.
Le changement de finalités de la collecte de données, moteur d’une défiance généralisée
L’administration des impôts a donc accepté un accord de partage d’information et de données avec les services d’immigration, rapporte la NPR, permettant aux agents de l’immigration de demander des informations sur les immigrants faisant l’objet d’une ordonnance d’expulsion. Derrière ce qui paraît comme un simple accès à des données, il faut voir un changement majeur dans l’utilisation des dossiers fiscaux. Les modalités de ce partage d’information ne sont pas claires puisque la communication du cadre de partage a été expurgée de très nombreuses informations. Pour Murad Awawdeh, responsable de la New York Immigration Coalition, ce partage risque d’instaurer un haut niveau de défiance à respecter ses obligations fiscales, alors que les immigrants paient des impôts comme les autres et que les services fiscaux assuraient jusqu’à présent aux contribuables sans papiers la confidentialité de leurs informations et la sécurité de leur déclaration de revenus.
La NPR revient également sur un autre changement de finalité, particulièrement problématique : celle de l’application CBP One. Cette application lancée en 2020 par l’administration Biden visait à permettre aux immigrants de faire une demande d’asile avant de pénétrer aux Etats-Unis. Avec l’arrivée de l’administration Trump, les immigrants qui ont candidaté à une demande d’asile ont reçu une notification les enjoignants à quitter les Etats-Unis et les données de l’application ont été partagées avec les services de police pour localiser les demandeurs d’asile et les arrêter pour les reconduire aux frontières. Pour le dire simplement : une application de demande d’asile est désormais utilisée par les services de police pour identifier ces mêmes demandeurs et les expulser. Les finalités sociales sont transformées en finalités policières. La confidentialité même des données est détruite.
CBP One n’est pas la seule application dont la finalité a été modifiée. Une belle enquête du New York Times évoque une application administrée par Geo Group, l’un des principaux gestionnaires privés de centres pénitentiaires et d’établissements psychiatriques aux Etats-Unis. Une application que des étrangers doivent utiliser pour se localiser et s’identifier régulièrement, à la manière d’un bracelet électronique. Récemment, des utilisateurs de cette application ont été convoqués à un centre d’immigration pour mise à jour de l’application. En fait, ils ont été arrêtés.
Geo Group a développé une activité lucrative d’applications et de bracelets électroniques pour surveiller les immigrants pour le compte du gouvernement fédéral qui ont tous été mis au service des procédures d’expulsion lancées par l’administration Trump, constatent nombre d’associations d’aides aux étrangers. “Alors même que M. Trump réduit les dépenses du gouvernement fédéral, ses agences ont attribué à Geo Group de nouveaux contrats fédéraux pour héberger des immigrants sans papiers. Le DHS envisage également de renouveler un contrat de longue date avec l’entreprise – d’une valeur d’environ 350 millions de dollars l’an dernier – pour suivre les quelque 180 000 personnes actuellement sous surveillance”. Ce programme “d’alternative à la détention en centre de rétention » que Noor Zafar, avocate principale à l’American Civil Liberties Union, estime relever plutôt d’une “extension à la détention”, consiste en des applications et bracelets électroniques. Les programmes de Geo Group, coûteux, n’ont pas été ouverts à la concurrence, rapporte le New York Times, qui explique également que ses programmes sont en plein boom. Ces applications permettent aux employés de Geo Group de savoir en temps réel où se trouvent leurs porteurs, leur permettent de délimiter des zones dont ils ne peuvent pas sortir sans déclencher des alertes.
Une confiance impossible !
Ces exemples américains de changement de finalités sont emblématiques et profondément problématiques. Ils ne se posent pourtant pas que de l’autre côté de l’Atlantique. Utiliser des données produites dans un contexte pour d’autres enjeux et d’autres contextes est au cœur des fonctionnements des systèmes numériques, comme nous l’avions vu à l’époque du Covid. Les finalités des traitements des services numériques qu’on utilise sont rarement claires, notamment parce qu’elles peuvent être mises à jour unilatéralement et ce, sans garantie. Et le changement de finalité peut intervenir à tout moment, quelque soit l’application que vous utilisez. Remplir un simple questionnaire d’évaluation peut finalement, demain, être utilisé par le service qui le conçoit ou d’autres pour une toute autre finalité, et notamment pour réduire les droits des utilisateurs qui y ont répondu. Répondre à un questionnaire de satisfaction de votre banque ou d’un service public, qui semble anodin, peut divulguer des données qui seront utilisées pour d’autres enjeux. Sans renforcer la protection absolue des données, le risque est que ces exemples démultiplient la méfiance voire le rejet des citoyens et des administrés. A quoi va être utilisé le questionnaire qu’on me propose ? Pourra-t-il être utilisé contre moi ?Qu’est-ce qui me garantie qu’il ne le sera pas ?
La confiance dans l’utilisation qui est faite des données par les services, est en train d’être profondément remise en question par l’exemple américain et pourrait avoir des répercussions sur tous les services numériques, bien au-delà des Etats-Unis. La spécialiste de la sécurité informatique, Susan Landau, nous l’avait pourtant rappelé quand elle avait étudié les défaillances des applications de suivi de contact durant la pandémie : la confidentialité est toujours critique. Elle parlait bien sûr des données de santé des gens, mais on comprend qu’assurer la confidentialité des données personnelles que les autorités détiennent sur les gens est tout aussi critique. Les défaillances de confidentialité sapent la confiance des autorités qui sont censées pourtant être les premières garantes des données personnelles des citoyens.
Aurait-on oublié pourquoi les données sont cloisonnées ?
« Ces systèmes sont cloisonnés pour une raison », rappelle Victoria Noble, avocate à l’Electronic Frontier Foundation. « Lorsque vous centralisez toutes les données d’une agence dans un référentiel central accessible à tous les membres de l’agence, voire à d’autres agences, vous augmentez considérablement le risque que ces informations soient consultées par des personnes qui n’en ont pas besoin et qui les utilisent à des fins inappropriées ou répressives, pour les instrumentaliser, les utiliser contre des personnes qu’elles détestent, des dissidents, surveiller des immigrants ou d’autres groupes. »
« La principale inquiétude désormais est la création d’une base de données fédérale unique contenant tout ce que le gouvernement sait sur chaque personne de ce pays », estime Cody Venzke de l’Union américaine pour les libertés civiles (ACLU). « Ce que nous voyons est probablement la première étape vers la création d’un dossier centralisé sur chaque habitant.» Wired rapporte d’ailleurs que l’ACLU a déposé plainte contre l’Administration de la Sécurité Sociale (SSA) et le Département des Anciens Combattants (VA) qui ont ouvert des accès de données sensibles au Doge en violation de la loi sur la liberté d’information, après en avoir déjà déposé une en février contre le Trésor américain pour les mêmes raisons (alors que ce n’est pas nécessairement la seule manière de procéder. Confronté aux demandes du Doge, le régulateur des marchés financiers américains, rapporte Reuters, a pour l’instant pu créer une équipe de liaison spécifique pour répondre aux demandes d’information du Doge, afin que ses équipes n’aient pas accès aux données de l’autorité des marchés financiers).
En déposant plainte, l’ACLU cherche notamment à obtenir des documents pour saisir exactement ce à quoi a accès le Doge. “Les Américains méritent de savoir qui a accès à leurs numéros de sécurité sociale, à leurs informations bancaires et à leurs dossiers médicaux”, explique une avocate de l’ACLU.
Le cloisonnement des données, des bases, selon leurs finalités et les agences qui les administrent, est un moyen non seulement d’en préserver l’intégrité, mais également d’en assurer la sécurité et la confidentialité. Ce sont ces verrous qui sont en train de sauter dans toutes les administrations sous la pression du Doge, posant des questions de sécurité inédites, comme nous nous en inquiétons avec Jean Cattan dans une lettre du Conseil national du numérique. Ce sont les mesures de protection d’une démocratie numérique qui sont en train de voler en éclat.
Pour Wired, Brian Barrett estime que les données qu’agrège le Doge ne sont pas tant un outil pour produire une hypothétique efficacité, qu’une arme au service des autorités. La question de l’immigration n’est qu’un terrain d’application parmi d’autres. La brutalité qui s’abat sur les étrangers, les plus vulnérables, les plus démunis, est bien souvent une préfiguration de son extension à toutes les autres populations, nous disait le philosophe Achille Mbembe dans Brutalisme.
Et maintenant que les croisements de données sont opérationnels, que les données ont été récupérées par les équipes du Doge, l’enjeu va être de les faire parler, de les mettre en pratique.
Finalement, le départ annoncé ou probable de Musk de son poste en première ligne du Doge ne signe certainement pas la fin de cette politique, toute impopulaire qu’elle soit (enfin, Musk est bien plus impopulaire que les économies dans les services publics qu’il propose), mais au contraire, le passage à une autre phase. Le Doge a pris le contrôle, etil s’agit désormais de rendre les données productives. L’efficacité n’est plus de réduire les dépenses publiques de 2 000 milliards de dollars, comme le promettait Musk à son arrivée. Il a lui-même reconnu qu’il ne visait plus que 150 milliards de dollars de coupe en 2025, soit 15 % de l’objectif initial, comme le soulignait Le Monde. Mais le débat sur les coupes et l’efficacité, sont d’abord un quolifichet qu’on agite pour détourner l’attention de ce qui se déroule vraiment, à savoir la fin de la vie privée aux Etats-Unis. En fait, la politique initiée par le Doge ne s’arrêtera pas avec le retrait probable de Musk. IL n’en a été que le catalyseur.
Elizabeth Lopatto pour The Verge explique elle aussi que l’ère du Doge ne fait que commencer. Malgré ses échecs patents et l’explosion des plaintes judiciaires à son encontre (Bloomberg a dénombré plus de 300 actions en justice contre les décisions prises par le président Trump : dans 128 affaires, ils ont suspendu les décisions de l’administration Trump). Pour elle, Musk ne va pas moins s’immiscer dans la politique publique. Son implication risque surtout d’être moins publique et moins visible dans ses ingérences, afin de préserver son égo et surtout son portefeuille. Mais surtout, estime-t-elle, les tribunaux ne sauveront pas les Américains des actions du Doge, notamment parce que dans la plupart des cas, les décisions tardent à être prises et à être effectives. Pourtant, si les tribunaux étaient favorables à « l’élimination de la fraude et des abus », comme le dit Musk – à ce stade, ils devraient surtout œuvrer à “éliminer le Doge” !
Ce n’est malgré tout pas la direction qui est prise, au contraire. Même si Musk s’en retire, l’administration continue à renforcer le pouvoir du Doge qu’à l’éteindre. C’est ainsi qu’il faut lire le récent hackathon aux services fiscaux ou le projet qui s’esquisse avec Palantir. L’ICE, sous la coupe du Doge, vient de demander à Palantir, la sulfureuse entreprise de Thiel, de construire une plateforme dédiée, explique Wired : “ImmigrationOS”, « le système d’exploitation de l’immigration » (sic). Un outil pour “choisir les personnes à expulser”, en accordant une priorité particulière aux personnes dont le visa est dépassé qui doivent, selon la demande de l’administration, prendre leurs dispositions pour “s’expulser elles-mêmes des Etats-Unis”. L’outil qui doit être livré en septembre a pour fonction de cibler et prioriser les mesures d’application, c’est-à-dire d’aider à sélectionner les étrangers en situation irrégulière, les localiser pour les arrêter. Il doit permettre de suivre que les étrangers en situation irrégulière prennent bien leur disposition pour quitter les Etats-Unis, afin de mesurer la réalité des départs, et venir renforcer les efforts des polices locales, bras armées des mesures de déportation, comme le pointait The Markup.
De ImmigrationOS au panoptique américain : le démantèlement des mesures de protection de la vie privée
Dans un article pour Gizmodo qui donne la parole à nombre d’opposants à la politique de destructions des silos de données, plusieurs rappellent les propos du sénateur démocrate Sam Ervin, auteur de la loi sur la protection des informations personnelles suite au scandale du Watergate, qui redoutait le caractère totalitaire des informations gouvernementales sur les citoyens. Pour Victoria Noble de l’Electronic Frontier Foundation, ce contrôle pourrait conduire les autorités à « exercer des représailles contre les critiques adressées aux représentants du gouvernement, à affaiblir les opposants politiques ou les ennemis personnels perçus, et à cibler les groupes marginalisés. » N’oubliez pas qu’il s’agit du même président qui a qualifié d’« ennemis » les agents électoraux, les journalistes, les juges et, en fait, toute personne en désaccord avec lui. Selon Reuters, le Doge a déjà utilisé l’IA pour détecter les cas de déloyauté parmi les fonctionnaires fédéraux. Pour les défenseurs des libertés et de la confidentialité, il est encore temps de renforcer les protections citoyennes. Et de rappeler que le passage de la sûreté à la sécurité, de la défense contre l’arbitraire à la défense de l’arbitraire, vient de ce que les élus ont passé bien plus d’énergie à légiférer pour la surveillance qu’à établir des garde-fous contre celle-ci, autorisant toujours plus de dérives, comme d’autoriser la surveillance des individus sans mandats de justice.
Pour The Atlantic, Ian Bogost et Charlie Warzel estiment que le Doge est en train de construire le panoptique américain. Ils rappellent que l’administration est l’univers de l’information, composée de constellations de bases de données. Des impôts au travail, toutes les administrations collectent et produisent des données sur les Américains, et notamment des données particulièrement sensibles et personnelles. Jusqu’à présent, de vieilles lois et des normes fragiles ont empêché que les dépôts de données ne soient regroupés. Mais le Doge vient de faire voler cela en éclat, préparant la construction d’un Etat de surveillance centralisé. En mars, le président Trump a publié un décret visant à éliminer les silos de données qui maintiennent les informations séparément.
Dans leur article, Bogost et Warzel listent d’innombrables bases de données maintenues par des agences administratives : bases de données de revenus, bases de données sur les lanceurs d’alerte, bases de données sur la santé mentale d’anciens militaires… L’IA promet de transformer ces masses de données en outils “consultables, exploitables et rentables”. Mais surtout croisables, interconnectables. Les entreprises bénéficiant de prêts fédéraux et qui ont du mal à rembourser, pourraient désormais être punies au-delà de ce qui est possible, par la révocation de leurs licences, le gel des aides ou de leurs comptes bancaires. Une forme d’application universelle permettant de tout croiser et de tout inter-relier. Elles pourraient permettre de cibler la population en fonction d’attributs spécifiques. L’utilisation actuelle par le gouvernement de ces données pour expulser des étrangers, et son refus de fournir des preuves d’actes répréhensibles reprochées à certaines personnes expulsées, suggère que l’administration a déjà franchi la ligne rouge de l’utilisation des données à des fins politiques.
Le Doge ne se contente pas de démanteler les mesures de protection de la vie privée, il ignore qu’elles ont été rédigées. Beaucoup de bases ont été conçues sans interconnectivité par conception, pour protéger la vie privée. “Dans les cas où le partage d’informations ou de données est nécessaire, la loi sur la protection de la vie privée de 1974 exige un accord de correspondance informatique (Computer Matching Agreement, CMA), un contrat écrit qui définit les conditions de ce partage et assure la protection des informations personnelles. Un CMA est « un véritable casse-tête », explique un fonctionnaire, et constitue l’un des moyens utilisés par le gouvernement pour décourager l’échange d’informations comme mode de fonctionnement par défaut”.
La centralisation des données pourrait peut-être permettre d’améliorer l’efficacité gouvernementale, disent bien trop rapidement Bogost et Warzel, alors que rien ne prouve que ces croisements de données produiront autre chose qu’une discrimination toujours plus étendue car parfaitement granulaire. La protection de la vie privée vise à limiter les abus de pouvoir, notamment pour protéger les citoyens de mesures de surveillance illégales du gouvernement.
Derrière les bases de données, rappellent encore les deux journalistes, les données ne sont pas toujours ce que l’on imagine. Toutes les données de ces bases ne sont pas nécessairement numérisées. Les faire parler et les croiser ne sera pas si simple. Mais le Doge a eu accès à des informations inédites. “Ce que nous ignorons, c’est ce qu’ils ont copié, exfiltré ou emporté avec eux”.
“Doge constitue l’aboutissement logique du mouvement Big Data” : les données sont un actif. Les collecter et les croiser est un moyen de leur donner de la valeur. Nous sommes en train de passer d’une administration pour servir les citoyens à une administration pour les exploiter, suggèrent certains agents publics. Ce renversement de perspective “correspond parfaitement à l’éthique transactionnelle de Trump”. Ce ne sont plus les intérêts des américains qui sont au centre de l’équation, mais ceux des intérêts commerciaux des services privés, des intérêts des amis et alliés de Trump et Musk.
La menace totalitaire de l’accaparement des données personnelles gouvernementales
C’est la même inquiétude qu’exprime la politiste Allison Stanger dans un article pour The Conversation, qui rappelle que l’accès aux données gouvernementales n’a rien à voir avec les données personnelles que collectent les entreprises privées. Les référentiels gouvernementaux sont des enregistrements vérifiés du comportement humain réel de populations entières. « Les publications sur les réseaux sociaux et les historiques de navigation web révèlent des comportements ciblés ou intentionnels, tandis que les bases de données gouvernementales capturent les décisions réelles et leurs conséquences. Par exemple, les dossiers Medicare révèlent les choix et les résultats en matière de soins de santé. Les données de l’IRS et du Trésor révèlent les décisions financières et leurs impacts à long terme. Les statistiques fédérales sur l’emploi et l’éducation révèlent les parcours scolaires et les trajectoires professionnelles. » Ces données là, capturées pour faire tourner et entraîner des IA sont à la fois longitudinales et fiables. « Chaque versement de la Sécurité sociale, chaque demande de remboursement Medicare et chaque subvention fédérale constituent un point de données vérifié sur les comportements réels. Ces données n’existent nulle part ailleurs aux États-Unis avec une telle ampleur et une telle authenticité. »« Les bases de données gouvernementales suivent des populations entières au fil du temps, et pas seulement les utilisateurs actifs en ligne. Elles incluent les personnes qui n’utilisent jamais les réseaux sociaux, n’achètent pas en ligne ou évitent activement les services numériques. Pour une entreprise d’IA, cela impliquerait de former les systèmes à la diversité réelle de l’expérience humaine, plutôt qu’aux simples reflets numériques que les gens projettent en ligne.« A terme, explique Stanger, ce n’est pas la même IA à laquelle nous serions confrontés. « Imaginez entraîner un système d’IA non seulement sur les opinions concernant les soins de santé, mais aussi sur les résultats réels des traitements de millions de patients. Imaginez la différence entre tirer des enseignements des discussions sur les réseaux sociaux concernant les politiques économiques et analyser leurs impacts réels sur différentes communautés et groupes démographiques sur des décennies ». Pour une entreprise développant des IA, l’accès à ces données constituerait un avantage quasi insurmontable. « Un modèle d’IA, entraîné à partir de ces données gouvernementales pourrait identifier les schémas thérapeutiques qui réussissent là où d’autres échouent, et ainsi dominer le secteur de la santé. Un tel modèle pourrait comprendre comment différentes interventions affectent différentes populations au fil du temps, en tenant compte de facteurs tels que la localisation géographique, le statut socio-économique et les pathologies concomitantes. » Une entreprise d’IA qui aurait accès aux données fiscales, pourrait « développer des capacités exceptionnelles de prévision économique et de prévision des marchés. Elle pourrait modéliser les effets en cascade des changements réglementaires, prédire les vulnérabilités économiques avant qu’elles ne se transforment en crises et optimiser les stratégies d’investissement avec une précision impossible à atteindre avec les méthodes traditionnelles ». Explique Stanger, en étant peut-être un peu trop dithyrambique sur les potentialités de l’IA, quand rien ne prouve qu’elles puissent faire mieux que nos approches plus classiques. Pour Stanger, la menace de l’accès aux données gouvernementales par une entreprise privée transcende les préoccupations relatives à la vie privée des individus. Nous deviendrons des sujets numériques plutôt que des citoyens, prédit-elle. Les données absolues corrompt absolument, rappelle Stanger. Oubliant peut-être un peu rapidement que ce pouvoir totalitaire est une menace non seulement si une entreprise privée se l’accapare, mais également si un Etat le déploie. La menace d’un Etat totalitaire par le croisement de toutes les données ne réside pas seulement par l’accaparement de cette puissance au profit d’une entreprise, comme celles de Musk, mais également au profit d’un Etat.
Nombre de citoyens étaient déjà résignés face à l’accumulation de données du secteur privé, face à leur exploitation sans leur consentement, concluent Bogost et Warzel. L’idée que le gouvernement cède à son tour ses données à des fins privées est scandaleuse, mais est finalement prévisible. La surveillance privée comme publique n’a cessé de se développer et de se renforcer. La rupture du barrage, la levée des barrières morales, limitant la possibilité à recouper l’ensemble des données disponibles, n’était peut-être qu’une question de temps. Certes, le pire est désormais devant nous, car cette rupture de barrière morale en annonce d’autres. Dans la kleptocratie des données qui s’est ouverte, celles-ci pourront être utilisées contre chacun, puisqu’elles permettront désormais de trouver une justification rétroactive voire de l’inventer, puisque l’intégrité des bases de données publiques ne saurait plus être garantie. Bogost et Warzel peuvent imaginer des modalités, en fait, désormais, les systèmes n’ont même pas besoin de corréler vos dons à des associations pro-palestiniennes pour vous refuser une demande de prêt ou de subvention. Il suffit de laisser croire que désormais, le croisement de données le permet.
Pire encore, “les Américains sont tenus de fournir de nombreuses données sensibles au gouvernement, comme des informations sur le divorce d’une personne pour garantir le versement d’une pension alimentaire, ou des dossiers détaillés sur son handicap pour percevoir les prestations d’assurance invalidité de la Sécurité sociale”, rappelle Sarah Esty, ancienne conseillère principale pour la technologie et la prestation de services au ministère américain de la Santé et des Services sociaux. “Ils ont agi ainsi en étant convaincus que le gouvernement protégerait ces données et que seules les personnes autorisées et absolument nécessaires à la prestation des services y auraient accès. Si ces garanties sont violées, ne serait-ce qu’une seule fois, la population perdra confiance dans le gouvernement, ce qui compromettra à jamais sa capacité à gérer ces services”. C’est exactement là où l’Amérique est plongée. Et le risque, devant nous, est que ce qui se passe aux Etats-Unis devienne un modèle pour saper partout les garanties et la protection des données personnelles.
A l’heure où, aux Etats-Unis, le FBI, les services d’immigration et de police se mettent à poursuivre les ressortissants étrangers pour les reconduire aux frontières, sur Tech Policy Press, l’activiste Dia Kayyali rappelle que les Etats-Unis ont une longue histoire de chasse aux opposants politiques et aux étrangers. Du MacCarthysme au 11 septembre, les crises politiques ont toujours renforcé la surveillance des citoyens et plus encore des ressortissants d’origine étrangère. Le Brennan Center fo
A l’heure où, aux Etats-Unis, le FBI, les services d’immigration et de police se mettent à poursuivre les ressortissants étrangers pour les reconduire aux frontières, sur Tech Policy Press, l’activiste Dia Kayyali rappelle que les Etats-Unis ont une longue histoire de chasse aux opposants politiques et aux étrangers. Du MacCarthysme au 11 septembre, les crises politiques ont toujours renforcé la surveillance des citoyens et plus encore des ressortissants d’origine étrangère. Le Brennan Center for Justice a publié en 2022 un rapport sur la montée de l’utilisation des réseaux sociaux dans ces activités de surveillance et rappelle que ceux-ci sont massivement mobilisés pour la surveillance des opposants politiques, notamment depuis Occupy et depuis 2014 pour le contrôle des demandes d’immigration et les contrôles aux frontières, rappelle The Verge.
Le premier projet de loi du second mandat de Donald Trump était un texte concernant l’immigration clandestine, nous rappelle Le Monde. C’est un texte qui propose la détention automatique par les forces de l’ordre fédérales de migrants en situation irrégulière qui ont été accusés, condamnés ou inculpés pour certains délits, mêmes mineurs, comme le vol à l’étalage.
La lutte contre l’immigration est au cœur de la politique du président américain, qui dénonce une “invasion” et annonce vouloir déporter 11 millions d’immigrants illégaux, au risque que le tissu social des Etats-Unis, nation d’immigrants, se déchire, rappelait The Guardian. Dès janvier, l’administration Trump a mis fin à l’application CBP One, seule voie pour les demandeurs d’asile désirant entrer légalement sur le territoire des Etats-Unis pour prendre rendez-vous avec l’administration douanière américaine et régulariser leur situation. La suppression unilatérale de l’application a laissé tous les demandeurs d’asile en attente d’un rendez-vous sans recours, rapportait Le Monde.
Une opération de fusion des informations sans précédent
Cette politique est en train de s’accélérer, notamment en mobilisant toutes les données numériques à sa disposition, rapporte Wired. Le Doge est en train de construire une base de données dédiée aux étrangers, collectant les données de plusieurs administrations, afin de créer un outil de surveillance d’une portée sans précédent. L’enjeu est de recouper toutes les données disponibles, non seulement pour mieux caractériser les situations des étrangers en situation régulière comme irrégulière, mais également les géolocaliser afin d’aider les services de police chargés des arrestations et de la déportation, d’opérer.
Jusqu’à présent, il existait d’innombrables bases de données disparates entre les différentes agences et au sein des agences. Si certaines pouvaient être partagées, à des fins policières, celles-ci n’ont jamais été regroupées par défaut, parce qu’elles sont souvent utilisées à des fins spécifiques. Le service de l’immigration et des douanes (ICE, Immigration and Customs Enforcement) et le département d’investigation de la sécurité intérieure (HSI, Homeland Security Investigations), par exemple, sont des organismes chargés de l’application de la loi et ont parfois besoin d’ordonnances du tribunal pour accéder aux informations sur un individu dans le cadre d’enquêtes criminelles, tandis que le service de citoyenneté et d’immigration des États-Unis (USCIS, United States Citizenship and Immigration Services) des États-Unis collecte des informations sensibles dans le cadre de la délivrance régulière de visas et de cartes vertes.
Des agents du Doge ont obtenu l’accès aux systèmes de l’USCIS. Ces bases de données contiennent des informations sur les réfugiés et les demandeurs d’asile, des données sur les titulaires de cartes vertes, les citoyens américains naturalisés et les bénéficiaires du programme d’action différée pour les arrivées d’enfants. Le Doge souhaite également télécharger des informations depuis les bases de données de myUSCIS, le portail en ligne où les immigrants peuvent déposer des demandes, communiquer avec l’USCIS, consulter l’historique de leurs demandes et répondre aux demandes de preuves à l’appui de leur dossier. Associées aux informations d’adresse IP des personnes qui consultent leurs données, elles pourraient servir à géolocaliser les immigrants.
Le département de sécurité intérieur (DHS, Department of Homeland Security) dont dépendent certaines de ces agences a toujours été très prudent en matière de partage de données. Ce n’est plus le cas. Le 20 mars, le président Trump a d’ailleurs signé un décret exigeant que toutes les agences fédérales facilitent « le partage intra- et inter-agences et la consolidation des dossiers non classifiés des agences », afin d’entériner la politique de récupération de données tout azimut du Doge. Jusqu’à présent, il était historiquement « extrêmement difficile » d’accéder aux données que le DHS possédait déjà dans ses différents départements. L’agrégation de toutes les données disponibles « représenterait une rupture significative dans les normes et les politiques en matière de données », rappelle un expert. Les agents du Doge ont eu accès à d’innombrables bases, comme à Save, un système de l’USCIS permettant aux administrations locales et étatiques, ainsi qu’au gouvernement fédéral, de vérifier le statut d’immigration d’une personne. Le Doge a également eu accès à des données de la sécurité sociale et des impôts pour recouper toutes les informations disponibles.
Le problème, c’est que la surveillance et la protection des données est également rendue plus difficile. Les coupes budgétaires et les licenciements ont affecté trois services clés qui constituaient des garde-fous importants contre l’utilisation abusive des données par les services fédéraux, à savoir le Bureau des droits civils et des libertés civiles (CRCL, Office for Civil Rights and Civil Liberties), le Bureau du médiateur chargé de la détention des immigrants et le Bureau du médiateur des services de citoyenneté et d’immigration. Le CRCL, qui enquête sur d’éventuelles violations des droits de l’homme par le DHS et dont la création a été mandatée par le Congrès est depuis longtemps dans le collimateur du Doge.
Le 5 avril, le DHS a conclu un accord avec les services fiscaux (IRS) pour utiliser les données fiscales. Plus de sept millions de migrants travaillent et vivent aux États-Unis. L’ICE a également récemment versé des millions de dollars à l’entreprise privée Palantir pour mettre à jour et modifier une base de données de l’ICE destinée à traquer les immigrants, a rapporté 404 Media. Le Washington Post a rapporté également que des représentants de Doge au sein d’agences gouvernementales – du Département du Logement et du Développement urbain à l’Administration de la Sécurité sociale – utilisent des données habituellement confidentielles pour identifier les immigrants sans papiers. Selon Wired, au Département du Travail, le Doge a obtenu l’accès à des données sensibles sur les immigrants et les ouvriers agricoles. La fusion de toutes les données entre elles pour permettre un accès panoptique aux informations est depuis l’origine le projet même du ministère de l’efficacité américain, qui espère que l’IA va lui permettre de rendre le traitement omniscient.
Le changement de finalités de la collecte de données, moteur d’une défiance généralisée
L’administration des impôts a donc accepté un accord de partage d’information et de données avec les services d’immigration, rapporte la NPR, permettant aux agents de l’immigration de demander des informations sur les immigrants faisant l’objet d’une ordonnance d’expulsion. Derrière ce qui paraît comme un simple accès à des données, il faut voir un changement majeur dans l’utilisation des dossiers fiscaux. Les modalités de ce partage d’information ne sont pas claires puisque la communication du cadre de partage a été expurgée de très nombreuses informations. Pour Murad Awawdeh, responsable de la New York Immigration Coalition, ce partage risque d’instaurer un haut niveau de défiance à respecter ses obligations fiscales, alors que les immigrants paient des impôts comme les autres et que les services fiscaux assuraient jusqu’à présent aux contribuables sans papiers la confidentialité de leurs informations et la sécurité de leur déclaration de revenus.
La NPR revient également sur un autre changement de finalité, particulièrement problématique : celle de l’application CBP One. Cette application lancée en 2020 par l’administration Biden visait à permettre aux immigrants de faire une demande d’asile avant de pénétrer aux Etats-Unis. Avec l’arrivée de l’administration Trump, les immigrants qui ont candidaté à une demande d’asile ont reçu une notification les enjoignants à quitter les Etats-Unis et les données de l’application ont été partagées avec les services de police pour localiser les demandeurs d’asile et les arrêter pour les reconduire aux frontières. Pour le dire simplement : une application de demande d’asile est désormais utilisée par les services de police pour identifier ces mêmes demandeurs et les expulser. Les finalités sociales sont transformées en finalités policières. La confidentialité même des données est détruite.
CBP One n’est pas la seule application dont la finalité a été modifiée. Une belle enquête du New York Times évoque une application administrée par Geo Group, l’un des principaux gestionnaires privés de centres pénitentiaires et d’établissements psychiatriques aux Etats-Unis. Une application que des étrangers doivent utiliser pour se localiser et s’identifier régulièrement, à la manière d’un bracelet électronique. Récemment, des utilisateurs de cette application ont été convoqués à un centre d’immigration pour mise à jour de l’application. En fait, ils ont été arrêtés.
Geo Group a développé une activité lucrative d’applications et de bracelets électroniques pour surveiller les immigrants pour le compte du gouvernement fédéral qui ont tous été mis au service des procédures d’expulsion lancées par l’administration Trump, constatent nombre d’associations d’aides aux étrangers. “Alors même que M. Trump réduit les dépenses du gouvernement fédéral, ses agences ont attribué à Geo Group de nouveaux contrats fédéraux pour héberger des immigrants sans papiers. Le DHS envisage également de renouveler un contrat de longue date avec l’entreprise – d’une valeur d’environ 350 millions de dollars l’an dernier – pour suivre les quelque 180 000 personnes actuellement sous surveillance”. Ce programme “d’alternative à la détention en centre de rétention » que Noor Zafar, avocate principale à l’American Civil Liberties Union, estime relever plutôt d’une “extension à la détention”, consiste en des applications et bracelets électroniques. Les programmes de Geo Group, coûteux, n’ont pas été ouverts à la concurrence, rapporte le New York Times, qui explique également que ses programmes sont en plein boom. Ces applications permettent aux employés de Geo Group de savoir en temps réel où se trouvent leurs porteurs, leur permettent de délimiter des zones dont ils ne peuvent pas sortir sans déclencher des alertes.
Une confiance impossible !
Ces exemples américains de changement de finalités sont emblématiques et profondément problématiques. Ils ne se posent pourtant pas que de l’autre côté de l’Atlantique. Utiliser des données produites dans un contexte pour d’autres enjeux et d’autres contextes est au cœur des fonctionnements des systèmes numériques, comme nous l’avions vu à l’époque du Covid. Les finalités des traitements des services numériques qu’on utilise sont rarement claires, notamment parce qu’elles peuvent être mises à jour unilatéralement et ce, sans garantie. Et le changement de finalité peut intervenir à tout moment, quelque soit l’application que vous utilisez. Remplir un simple questionnaire d’évaluation peut finalement, demain, être utilisé par le service qui le conçoit ou d’autres pour une toute autre finalité, et notamment pour réduire les droits des utilisateurs qui y ont répondu. Répondre à un questionnaire de satisfaction de votre banque ou d’un service public, qui semble anodin, peut divulguer des données qui seront utilisées pour d’autres enjeux. Sans renforcer la protection absolue des données, le risque est que ces exemples démultiplient la méfiance voire le rejet des citoyens et des administrés. A quoi va être utilisé le questionnaire qu’on me propose ? Pourra-t-il être utilisé contre moi ?Qu’est-ce qui me garantie qu’il ne le sera pas ?
La confiance dans l’utilisation qui est faite des données par les services, est en train d’être profondément remise en question par l’exemple américain et pourrait avoir des répercussions sur tous les services numériques, bien au-delà des Etats-Unis. La spécialiste de la sécurité informatique, Susan Landau, nous l’avait pourtant rappelé quand elle avait étudié les défaillances des applications de suivi de contact durant la pandémie : la confidentialité est toujours critique. Elle parlait bien sûr des données de santé des gens, mais on comprend qu’assurer la confidentialité des données personnelles que les autorités détiennent sur les gens est tout aussi critique. Les défaillances de confidentialité sapent la confiance des autorités qui sont censées pourtant être les premières garantes des données personnelles des citoyens.
Aurait-on oublié pourquoi les données sont cloisonnées ?
« Ces systèmes sont cloisonnés pour une raison », rappelle Victoria Noble, avocate à l’Electronic Frontier Foundation. « Lorsque vous centralisez toutes les données d’une agence dans un référentiel central accessible à tous les membres de l’agence, voire à d’autres agences, vous augmentez considérablement le risque que ces informations soient consultées par des personnes qui n’en ont pas besoin et qui les utilisent à des fins inappropriées ou répressives, pour les instrumentaliser, les utiliser contre des personnes qu’elles détestent, des dissidents, surveiller des immigrants ou d’autres groupes. »
« La principale inquiétude désormais est la création d’une base de données fédérale unique contenant tout ce que le gouvernement sait sur chaque personne de ce pays », estime Cody Venzke de l’Union américaine pour les libertés civiles (ACLU). « Ce que nous voyons est probablement la première étape vers la création d’un dossier centralisé sur chaque habitant.» Wired rapporte d’ailleurs que l’ACLU a déposé plainte contre l’Administration de la Sécurité Sociale (SSA) et le Département des Anciens Combattants (VA) qui ont ouvert des accès de données sensibles au Doge en violation de la loi sur la liberté d’information, après en avoir déjà déposé une en février contre le Trésor américain pour les mêmes raisons (alors que ce n’est pas nécessairement la seule manière de procéder. Confronté aux demandes du Doge, le régulateur des marchés financiers américains, rapporte Reuters, a pour l’instant pu créer une équipe de liaison spécifique pour répondre aux demandes d’information du Doge, afin que ses équipes n’aient pas accès aux données de l’autorité des marchés financiers).
En déposant plainte, l’ACLU cherche notamment à obtenir des documents pour saisir exactement ce à quoi a accès le Doge. “Les Américains méritent de savoir qui a accès à leurs numéros de sécurité sociale, à leurs informations bancaires et à leurs dossiers médicaux”, explique une avocate de l’ACLU.
Le cloisonnement des données, des bases, selon leurs finalités et les agences qui les administrent, est un moyen non seulement d’en préserver l’intégrité, mais également d’en assurer la sécurité et la confidentialité. Ce sont ces verrous qui sont en train de sauter dans toutes les administrations sous la pression du Doge, posant des questions de sécurité inédites, comme nous nous en inquiétons avec Jean Cattan dans une lettre du Conseil national du numérique. Ce sont les mesures de protection d’une démocratie numérique qui sont en train de voler en éclat.
Pour Wired, Brian Barrett estime que les données qu’agrège le Doge ne sont pas tant un outil pour produire une hypothétique efficacité, qu’une arme au service des autorités. La question de l’immigration n’est qu’un terrain d’application parmi d’autres. La brutalité qui s’abat sur les étrangers, les plus vulnérables, les plus démunis, est bien souvent une préfiguration de son extension à toutes les autres populations, nous disait le philosophe Achille Mbembe dans Brutalisme.
Et maintenant que les croisements de données sont opérationnels, que les données ont été récupérées par les équipes du Doge, l’enjeu va être de les faire parler, de les mettre en pratique.
Finalement, le départ annoncé ou probable de Musk de son poste en première ligne du Doge ne signe certainement pas la fin de cette politique, toute impopulaire qu’elle soit (enfin, Musk est bien plus impopulaire que les économies dans les services publics qu’il propose), mais au contraire, le passage à une autre phase. Le Doge a pris le contrôle, etil s’agit désormais de rendre les données productives. L’efficacité n’est plus de réduire les dépenses publiques de 2 000 milliards de dollars, comme le promettait Musk à son arrivée. Il a lui-même reconnu qu’il ne visait plus que 150 milliards de dollars de coupe en 2025, soit 15 % de l’objectif initial, comme le soulignait Le Monde. Mais le débat sur les coupes et l’efficacité, sont d’abord un quolifichet qu’on agite pour détourner l’attention de ce qui se déroule vraiment, à savoir la fin de la vie privée aux Etats-Unis. En fait, la politique initiée par le Doge ne s’arrêtera pas avec le retrait probable de Musk. IL n’en a été que le catalyseur.
Elizabeth Lopatto pour The Verge explique elle aussi que l’ère du Doge ne fait que commencer. Malgré ses échecs patents et l’explosion des plaintes judiciaires à son encontre (Bloomberg a dénombré plus de 300 actions en justice contre les décisions prises par le président Trump : dans 128 affaires, ils ont suspendu les décisions de l’administration Trump). Pour elle, Musk ne va pas moins s’immiscer dans la politique publique. Son implication risque surtout d’être moins publique et moins visible dans ses ingérences, afin de préserver son égo et surtout son portefeuille. Mais surtout, estime-t-elle, les tribunaux ne sauveront pas les Américains des actions du Doge, notamment parce que dans la plupart des cas, les décisions tardent à être prises et à être effectives. Pourtant, si les tribunaux étaient favorables à « l’élimination de la fraude et des abus », comme le dit Musk – à ce stade, ils devraient surtout œuvrer à “éliminer le Doge” !
Ce n’est malgré tout pas la direction qui est prise, au contraire. Même si Musk s’en retire, l’administration continue à renforcer le pouvoir du Doge qu’à l’éteindre. C’est ainsi qu’il faut lire le récent hackathon aux services fiscaux ou le projet qui s’esquisse avec Palantir. L’ICE, sous la coupe du Doge, vient de demander à Palantir, la sulfureuse entreprise de Thiel, de construire une plateforme dédiée, explique Wired : “ImmigrationOS”, « le système d’exploitation de l’immigration » (sic). Un outil pour “choisir les personnes à expulser”, en accordant une priorité particulière aux personnes dont le visa est dépassé qui doivent, selon la demande de l’administration, prendre leurs dispositions pour “s’expulser elles-mêmes des Etats-Unis”. L’outil qui doit être livré en septembre a pour fonction de cibler et prioriser les mesures d’application, c’est-à-dire d’aider à sélectionner les étrangers en situation irrégulière, les localiser pour les arrêter. Il doit permettre de suivre que les étrangers en situation irrégulière prennent bien leur disposition pour quitter les Etats-Unis, afin de mesurer la réalité des départs, et venir renforcer les efforts des polices locales, bras armées des mesures de déportation, comme le pointait The Markup.
De ImmigrationOS au panoptique américain : le démantèlement des mesures de protection de la vie privée
Dans un article pour Gizmodo qui donne la parole à nombre d’opposants à la politique de destructions des silos de données, plusieurs rappellent les propos du sénateur démocrate Sam Ervin, auteur de la loi sur la protection des informations personnelles suite au scandale du Watergate, qui redoutait le caractère totalitaire des informations gouvernementales sur les citoyens. Pour Victoria Noble de l’Electronic Frontier Foundation, ce contrôle pourrait conduire les autorités à « exercer des représailles contre les critiques adressées aux représentants du gouvernement, à affaiblir les opposants politiques ou les ennemis personnels perçus, et à cibler les groupes marginalisés. » N’oubliez pas qu’il s’agit du même président qui a qualifié d’« ennemis » les agents électoraux, les journalistes, les juges et, en fait, toute personne en désaccord avec lui. Selon Reuters, le Doge a déjà utilisé l’IA pour détecter les cas de déloyauté parmi les fonctionnaires fédéraux. Pour les défenseurs des libertés et de la confidentialité, il est encore temps de renforcer les protections citoyennes. Et de rappeler que le passage de la sûreté à la sécurité, de la défense contre l’arbitraire à la défense de l’arbitraire, vient de ce que les élus ont passé bien plus d’énergie à légiférer pour la surveillance qu’à établir des garde-fous contre celle-ci, autorisant toujours plus de dérives, comme d’autoriser la surveillance des individus sans mandats de justice.
Pour The Atlantic, Ian Bogost et Charlie Warzel estiment que le Doge est en train de construire le panoptique américain. Ils rappellent que l’administration est l’univers de l’information, composée de constellations de bases de données. Des impôts au travail, toutes les administrations collectent et produisent des données sur les Américains, et notamment des données particulièrement sensibles et personnelles. Jusqu’à présent, de vieilles lois et des normes fragiles ont empêché que les dépôts de données ne soient regroupés. Mais le Doge vient de faire voler cela en éclat, préparant la construction d’un Etat de surveillance centralisé. En mars, le président Trump a publié un décret visant à éliminer les silos de données qui maintiennent les informations séparément.
Dans leur article, Bogost et Warzel listent d’innombrables bases de données maintenues par des agences administratives : bases de données de revenus, bases de données sur les lanceurs d’alerte, bases de données sur la santé mentale d’anciens militaires… L’IA promet de transformer ces masses de données en outils “consultables, exploitables et rentables”. Mais surtout croisables, interconnectables. Les entreprises bénéficiant de prêts fédéraux et qui ont du mal à rembourser, pourraient désormais être punies au-delà de ce qui est possible, par la révocation de leurs licences, le gel des aides ou de leurs comptes bancaires. Une forme d’application universelle permettant de tout croiser et de tout inter-relier. Elles pourraient permettre de cibler la population en fonction d’attributs spécifiques. L’utilisation actuelle par le gouvernement de ces données pour expulser des étrangers, et son refus de fournir des preuves d’actes répréhensibles reprochées à certaines personnes expulsées, suggère que l’administration a déjà franchi la ligne rouge de l’utilisation des données à des fins politiques.
Le Doge ne se contente pas de démanteler les mesures de protection de la vie privée, il ignore qu’elles ont été rédigées. Beaucoup de bases ont été conçues sans interconnectivité par conception, pour protéger la vie privée. “Dans les cas où le partage d’informations ou de données est nécessaire, la loi sur la protection de la vie privée de 1974 exige un accord de correspondance informatique (Computer Matching Agreement, CMA), un contrat écrit qui définit les conditions de ce partage et assure la protection des informations personnelles. Un CMA est « un véritable casse-tête », explique un fonctionnaire, et constitue l’un des moyens utilisés par le gouvernement pour décourager l’échange d’informations comme mode de fonctionnement par défaut”.
La centralisation des données pourrait peut-être permettre d’améliorer l’efficacité gouvernementale, disent bien trop rapidement Bogost et Warzel, alors que rien ne prouve que ces croisements de données produiront autre chose qu’une discrimination toujours plus étendue car parfaitement granulaire. La protection de la vie privée vise à limiter les abus de pouvoir, notamment pour protéger les citoyens de mesures de surveillance illégales du gouvernement.
Derrière les bases de données, rappellent encore les deux journalistes, les données ne sont pas toujours ce que l’on imagine. Toutes les données de ces bases ne sont pas nécessairement numérisées. Les faire parler et les croiser ne sera pas si simple. Mais le Doge a eu accès à des informations inédites. “Ce que nous ignorons, c’est ce qu’ils ont copié, exfiltré ou emporté avec eux”.
“Doge constitue l’aboutissement logique du mouvement Big Data” : les données sont un actif. Les collecter et les croiser est un moyen de leur donner de la valeur. Nous sommes en train de passer d’une administration pour servir les citoyens à une administration pour les exploiter, suggèrent certains agents publics. Ce renversement de perspective “correspond parfaitement à l’éthique transactionnelle de Trump”. Ce ne sont plus les intérêts des américains qui sont au centre de l’équation, mais ceux des intérêts commerciaux des services privés, des intérêts des amis et alliés de Trump et Musk.
La menace totalitaire de l’accaparement des données personnelles gouvernementales
C’est la même inquiétude qu’exprime la politiste Allison Stanger dans un article pour The Conversation, qui rappelle que l’accès aux données gouvernementales n’a rien à voir avec les données personnelles que collectent les entreprises privées. Les référentiels gouvernementaux sont des enregistrements vérifiés du comportement humain réel de populations entières. « Les publications sur les réseaux sociaux et les historiques de navigation web révèlent des comportements ciblés ou intentionnels, tandis que les bases de données gouvernementales capturent les décisions réelles et leurs conséquences. Par exemple, les dossiers Medicare révèlent les choix et les résultats en matière de soins de santé. Les données de l’IRS et du Trésor révèlent les décisions financières et leurs impacts à long terme. Les statistiques fédérales sur l’emploi et l’éducation révèlent les parcours scolaires et les trajectoires professionnelles. » Ces données là, capturées pour faire tourner et entraîner des IA sont à la fois longitudinales et fiables. « Chaque versement de la Sécurité sociale, chaque demande de remboursement Medicare et chaque subvention fédérale constituent un point de données vérifié sur les comportements réels. Ces données n’existent nulle part ailleurs aux États-Unis avec une telle ampleur et une telle authenticité. »« Les bases de données gouvernementales suivent des populations entières au fil du temps, et pas seulement les utilisateurs actifs en ligne. Elles incluent les personnes qui n’utilisent jamais les réseaux sociaux, n’achètent pas en ligne ou évitent activement les services numériques. Pour une entreprise d’IA, cela impliquerait de former les systèmes à la diversité réelle de l’expérience humaine, plutôt qu’aux simples reflets numériques que les gens projettent en ligne.« A terme, explique Stanger, ce n’est pas la même IA à laquelle nous serions confrontés. « Imaginez entraîner un système d’IA non seulement sur les opinions concernant les soins de santé, mais aussi sur les résultats réels des traitements de millions de patients. Imaginez la différence entre tirer des enseignements des discussions sur les réseaux sociaux concernant les politiques économiques et analyser leurs impacts réels sur différentes communautés et groupes démographiques sur des décennies ». Pour une entreprise développant des IA, l’accès à ces données constituerait un avantage quasi insurmontable. « Un modèle d’IA, entraîné à partir de ces données gouvernementales pourrait identifier les schémas thérapeutiques qui réussissent là où d’autres échouent, et ainsi dominer le secteur de la santé. Un tel modèle pourrait comprendre comment différentes interventions affectent différentes populations au fil du temps, en tenant compte de facteurs tels que la localisation géographique, le statut socio-économique et les pathologies concomitantes. » Une entreprise d’IA qui aurait accès aux données fiscales, pourrait « développer des capacités exceptionnelles de prévision économique et de prévision des marchés. Elle pourrait modéliser les effets en cascade des changements réglementaires, prédire les vulnérabilités économiques avant qu’elles ne se transforment en crises et optimiser les stratégies d’investissement avec une précision impossible à atteindre avec les méthodes traditionnelles ». Explique Stanger, en étant peut-être un peu trop dithyrambique sur les potentialités de l’IA, quand rien ne prouve qu’elles puissent faire mieux que nos approches plus classiques. Pour Stanger, la menace de l’accès aux données gouvernementales par une entreprise privée transcende les préoccupations relatives à la vie privée des individus. Nous deviendrons des sujets numériques plutôt que des citoyens, prédit-elle. Les données absolues corrompt absolument, rappelle Stanger. Oubliant peut-être un peu rapidement que ce pouvoir totalitaire est une menace non seulement si une entreprise privée se l’accapare, mais également si un Etat le déploie. La menace d’un Etat totalitaire par le croisement de toutes les données ne réside pas seulement par l’accaparement de cette puissance au profit d’une entreprise, comme celles de Musk, mais également au profit d’un Etat.
Nombre de citoyens étaient déjà résignés face à l’accumulation de données du secteur privé, face à leur exploitation sans leur consentement, concluent Bogost et Warzel. L’idée que le gouvernement cède à son tour ses données à des fins privées est scandaleuse, mais est finalement prévisible. La surveillance privée comme publique n’a cessé de se développer et de se renforcer. La rupture du barrage, la levée des barrières morales, limitant la possibilité à recouper l’ensemble des données disponibles, n’était peut-être qu’une question de temps. Certes, le pire est désormais devant nous, car cette rupture de barrière morale en annonce d’autres. Dans la kleptocratie des données qui s’est ouverte, celles-ci pourront être utilisées contre chacun, puisqu’elles permettront désormais de trouver une justification rétroactive voire de l’inventer, puisque l’intégrité des bases de données publiques ne saurait plus être garantie. Bogost et Warzel peuvent imaginer des modalités, en fait, désormais, les systèmes n’ont même pas besoin de corréler vos dons à des associations pro-palestiniennes pour vous refuser une demande de prêt ou de subvention. Il suffit de laisser croire que désormais, le croisement de données le permet.
Pire encore, “les Américains sont tenus de fournir de nombreuses données sensibles au gouvernement, comme des informations sur le divorce d’une personne pour garantir le versement d’une pension alimentaire, ou des dossiers détaillés sur son handicap pour percevoir les prestations d’assurance invalidité de la Sécurité sociale”, rappelle Sarah Esty, ancienne conseillère principale pour la technologie et la prestation de services au ministère américain de la Santé et des Services sociaux. “Ils ont agi ainsi en étant convaincus que le gouvernement protégerait ces données et que seules les personnes autorisées et absolument nécessaires à la prestation des services y auraient accès. Si ces garanties sont violées, ne serait-ce qu’une seule fois, la population perdra confiance dans le gouvernement, ce qui compromettra à jamais sa capacité à gérer ces services”. C’est exactement là où l’Amérique est plongée. Et le risque, devant nous, est que ce qui se passe aux Etats-Unis devienne un modèle pour saper partout les garanties et la protection des données personnelles.
Si Zuck peut dire que les médias sociaux sont morts, c’est parce qu’il sait très bien qui a tenu le couteau : lui-même !, explique Kyle Chayka pour le New Yorker. Même constat pour Rob Horning : “Les entreprises technologiques ont construit une infrastructure sociale uniquement pour la saper, pour contribuer à la démanteler en tant que lieu de résistance à la commercialisation, à la marchandisation et à la médiatisation. Saboter le graphe social a été plus rémunérateur que l’exploiter, car les p
Si Zuck peut dire que les médias sociaux sont morts, c’est parce qu’il sait très bien qui a tenu le couteau : lui-même !, explique Kyle Chayka pour le New Yorker. Même constat pour Rob Horning : “Les entreprises technologiques ont construit une infrastructure sociale uniquement pour la saper, pour contribuer à la démanteler en tant que lieu de résistance à la commercialisation, à la marchandisation et à la médiatisation. Saboter le graphe social a été plus rémunérateur que l’exploiter, car les personnes isolées sont des consommateurs plus fiables” (…) “Les réseaux sociaux ont toujours voulu que vous détestiez vos amis”.
Si Zuck peut dire que les médias sociaux sont morts, c’est parce qu’il sait très bien qui a tenu le couteau : lui-même !, explique Kyle Chayka pour le New Yorker. Même constat pour Rob Horning : “Les entreprises technologiques ont construit une infrastructure sociale uniquement pour la saper, pour contribuer à la démanteler en tant que lieu de résistance à la commercialisation, à la marchandisation et à la médiatisation. Saboter le graphe social a été plus rémunérateur que l’exploiter, car les p
Si Zuck peut dire que les médias sociaux sont morts, c’est parce qu’il sait très bien qui a tenu le couteau : lui-même !, explique Kyle Chayka pour le New Yorker. Même constat pour Rob Horning : “Les entreprises technologiques ont construit une infrastructure sociale uniquement pour la saper, pour contribuer à la démanteler en tant que lieu de résistance à la commercialisation, à la marchandisation et à la médiatisation. Saboter le graphe social a été plus rémunérateur que l’exploiter, car les personnes isolées sont des consommateurs plus fiables” (…) “Les réseaux sociaux ont toujours voulu que vous détestiez vos amis”.
Les grands entrepreneurs de la Silicon Valley, ces « intellectuels oligarques » ont conçu des « portefeuilles d’investissement qui fonctionnent comme des arguments philosophiques, des positions de marché qui opérationnalisent leurs convictions. Et tandis que les milliardaires de l’ère industrielle construisaient des fondations pour immortaliser leurs visions du monde, ces figures érigent des fonds d’investissement qui font également office de forteresses idéologiques. » Evgeny Morozov sort la ka
Les grands entrepreneurs de la Silicon Valley, ces « intellectuels oligarques » ont conçu des « portefeuilles d’investissement qui fonctionnent comme des arguments philosophiques, des positions de marché qui opérationnalisent leurs convictions. Et tandis que les milliardaires de l’ère industrielle construisaient des fondations pour immortaliser leurs visions du monde, ces figures érigent des fonds d’investissement qui font également office de forteresses idéologiques. »Evgeny Morozov sort la kalach pour montrer que leurs idées ne sont que des arguments pour défendre leurs positions ! « Ils ont colonisé à la fois le média et le message, le système et le monde réel ».
Pour les nouveaux législateurs de la tech, l’intellectuel archéologue d’hier est mort, il l’ont eux-mêmes remplacé. Experts en démolition, ils n’écrivent plus sur l’avenir, mais l’installe. Ils ne financent plus de think tank, mais les suppriment. Ils dirigent eux-mêmes le débat « dans une production torrentielle qui épuiserait même Balzac », à coups de mèmes sur X repris en Une des journaux internationaux. « Leur droit divin de prédire découle de leur divinité avérée ». « Leurs déclarations présentent l’ancrage et l’expansion de leurs propres programmes non pas comme l’intérêt personnel de leurs entreprises, mais comme la seule chance de salut du capitalisme ».
L’accélération et l’audace entrepreneuriale sont pour eux le seul antidote à la sclérose systémique. Leur objectif : réaligner l’intelligentsia technologique sur le pouvoir de l’argent traditionnel en purifiant ses rangs des pensées subversives. Dans le Washington de Trump, ils n’arrivent pas en invités, mais en architectes, pour faire ce qu’ils ne cessent de faire : manipuler la réalité. « En réécrivant les réglementations, en canalisant les subventions et en réajustant les attentes du public, les intellectuels oligarques transforment des rêves fiévreux – fiefs de la blockchain, fermes martiennes – en futurs apparemment plausibles ».
Reste que le déni de réalité risque bien de les rattraper, prédit Morozov.
Les grands entrepreneurs de la Silicon Valley, ces « intellectuels oligarques » ont conçu des « portefeuilles d’investissement qui fonctionnent comme des arguments philosophiques, des positions de marché qui opérationnalisent leurs convictions. Et tandis que les milliardaires de l’ère industrielle construisaient des fondations pour immortaliser leurs visions du monde, ces figures érigent des fonds d’investissement qui font également office de forteresses idéologiques. » Evgeny Morozov sort la ka
Les grands entrepreneurs de la Silicon Valley, ces « intellectuels oligarques » ont conçu des « portefeuilles d’investissement qui fonctionnent comme des arguments philosophiques, des positions de marché qui opérationnalisent leurs convictions. Et tandis que les milliardaires de l’ère industrielle construisaient des fondations pour immortaliser leurs visions du monde, ces figures érigent des fonds d’investissement qui font également office de forteresses idéologiques. »Evgeny Morozov sort la kalach pour montrer que leurs idées ne sont que des arguments pour défendre leurs positions ! « Ils ont colonisé à la fois le média et le message, le système et le monde réel ».
Pour les nouveaux législateurs de la tech, l’intellectuel archéologue d’hier est mort, il l’ont eux-mêmes remplacé. Experts en démolition, ils n’écrivent plus sur l’avenir, mais l’installe. Ils ne financent plus de think tank, mais les suppriment. Ils dirigent eux-mêmes le débat « dans une production torrentielle qui épuiserait même Balzac », à coups de mèmes sur X repris en Une des journaux internationaux. « Leur droit divin de prédire découle de leur divinité avérée ». « Leurs déclarations présentent l’ancrage et l’expansion de leurs propres programmes non pas comme l’intérêt personnel de leurs entreprises, mais comme la seule chance de salut du capitalisme ».
L’accélération et l’audace entrepreneuriale sont pour eux le seul antidote à la sclérose systémique. Leur objectif : réaligner l’intelligentsia technologique sur le pouvoir de l’argent traditionnel en purifiant ses rangs des pensées subversives. Dans le Washington de Trump, ils n’arrivent pas en invités, mais en architectes, pour faire ce qu’ils ne cessent de faire : manipuler la réalité. « En réécrivant les réglementations, en canalisant les subventions et en réajustant les attentes du public, les intellectuels oligarques transforment des rêves fiévreux – fiefs de la blockchain, fermes martiennes – en futurs apparemment plausibles ».
Reste que le déni de réalité risque bien de les rattraper, prédit Morozov.