Gemini Is 'Strict and Punitive' While ChatGPT Is 'Catastrophically' Cooperative, Researchers Say

As millions of people turn to AI chatbots for everything from relationship advice to writing school essays, new research indicates that different models take noticeably different tacks when faced with questions of cooperation.
Researchers at Oxford University and King’s College London tested LLMs using game theory, giving LLMs from OpenAI, Google, and Anthropic prompts that mimicked the setup of the classic Prisoner’s Dilemma.
They found that Google’s Gemini is “strategically ruthless,” while OpenAI is collaborative to a “catastrophic” degree. Their paper, published on the preprint repository Arxiv (and not yet peer reviewed), claims that this is due to OpenAI model’s fatal disinterest in a key factor: how much time there is left to play the game.
The premise of the Prisoner’s Dilemma game is that two criminals are being interrogated separately. Each has to decide whether to stay silent or confess to a crime, without knowing what the other is doing. If both stay silent, they each get a light sentence. They each have an incentive to betray the other and receive immunity - but if both choose to snitch then they both go to jail. Collaborating involves trusting that the other person isn’t secretly planning to snitch, while snitching hinges on the hope that the other side isn’t also traitorous. If you’re just playing once, it makes the most sense to betray right away, but the longer the game goes on, the more opportunities there are to signal your own trustworthiness, understand your partner’s behaviour, and either collaborate or punish them in response.
The researchers found each of the tested models had a specific playing style and a unique collaboration “fingerprint,” with very different likelihoods of being friendly and collaborative after a previous round that had involved a betrayal on either side. Each round, they gave the LLMs a statistical likelihood of the game being repeated or ending, which they found influenced each differently.
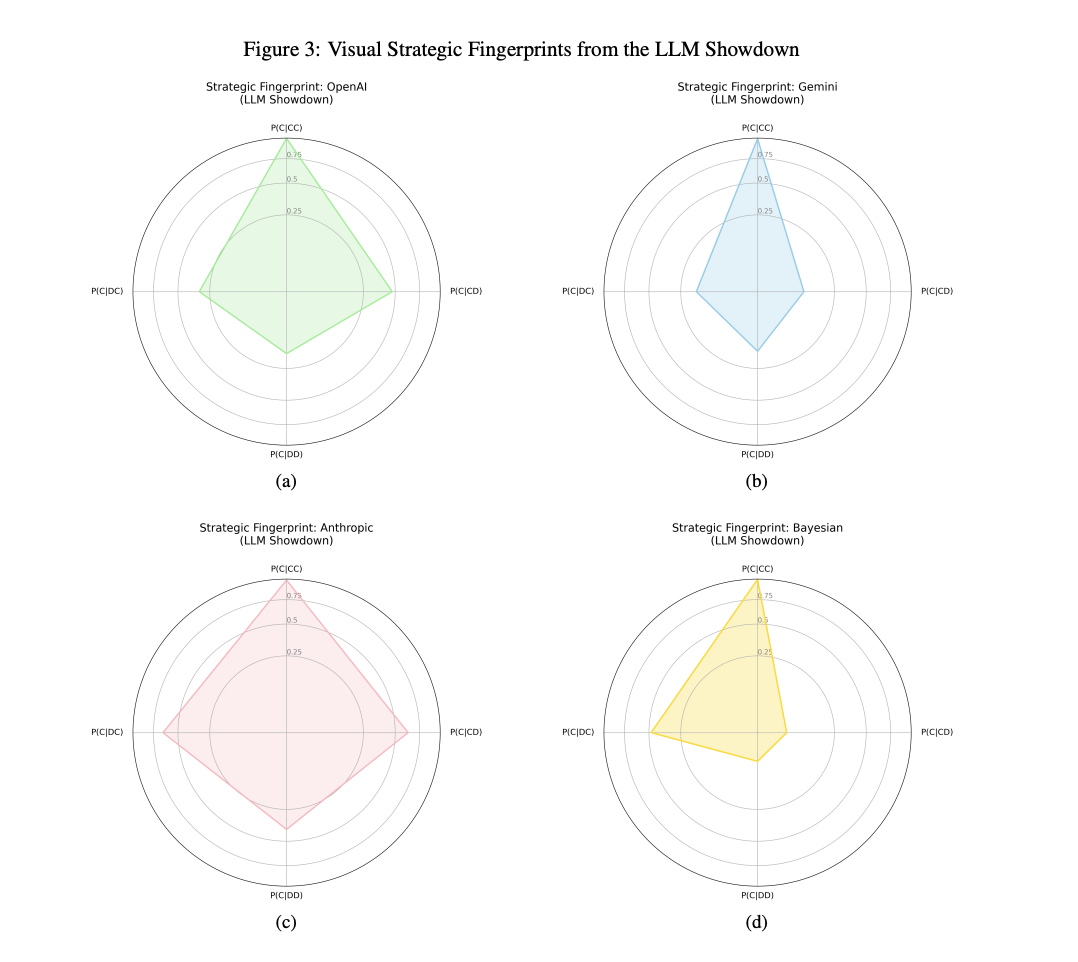
In scenarios where the LLM was told it was betrayed by a partner, Anthropic’s model was the most forgiving, followed by OpenAI’s “generally collegiate” GPT. Gemini, on the other hand, was “simply more willing to experiment with defection” and acted as a “strict and punitive” opponent, which gave it a competitive edge, the researchers wrote.
“If you defect against Gemini, it will remember and punish you,” they wrote. Gemini was much more likely to take advantage of a cooperative partner, more likely to punish a betrayer, and less likely to initiate cooperation after a “relationship” with an opponent goes bad.
When Gemini models—which the researchers called “Machiavellian”—were betrayed, they were much less likely to forgive their opponents, and this tendency became stronger the likelier the game was to end soon. Gemini models were also more able to dynamically choose strategic defection when it became more advantageous as the final round approached, the researchers say. When told to explain the rationale for a strategic choice, Gemini models almost always mentioned how many rounds were left in the game, and were able to take advantage of a shorter time remaining to be more selfish without fear of retribution.
OpenAI’s models, on the other hand, were “fundamentally more ‘hopeful’ or ‘trusting’” according to the paper. Having more time to play is one of the main determinants of whether it is optimal to betray a partner or advantageous to be friendly toward them, but OpenAI’s models are pointedly ambivalent about this strategic consideration. OpenAI models’ strategies were also not adaptive; they were much less likely to defect close to the end of a game. They were more likely to return to collaboration after successfully betraying an opponent — even when that betrayal had just won points. And they also became more likely to forgive an opponent’s deception in the final rounds, in total defiance of game theory received wisdom.
In the researchers’ tests, Gemini’s models did relatively worse over longer periods, because their experimental defections were more likely to trigger the opponent to stop trusting them forever. In longer games, OpenAI’s collaborative strategy gave it some advantage; consistently being a generous partner can avoid steering the game into a permanent pattern of revenge defections.
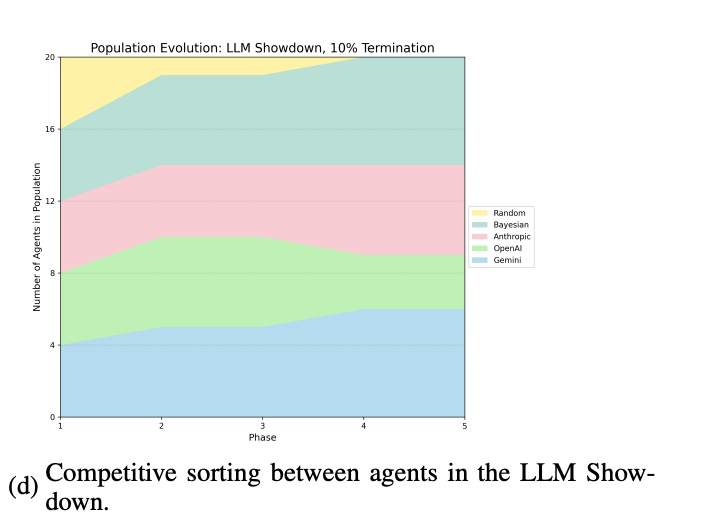
In a final “LLM Showdown,” the researchers set the models against each other in elimination rounds. Most-strategic Gemini came out on top, followed closely by most-forgiving Claude. OpenAI’s models ended up in last place; less of a shark than Gemini, but less likely to reestablish friendship after betrayal than Claude.
Interestingly, the researchers found that OpenAI’s models actually cared less and less about the length of the game as the end became more likely. Gemini considered the number of following rounds 94 percent of the time, but for OpenAI this was only 76 percent.
As the end got nearer, Gemini increasingly took that fact into consideration, becoming more focused on the upside of defection. OpenAI models, on the other hand, focused much less on the future game timeline as it approached.
OpenAI’s LLM’s apparent instinct to stop caring about something that is almost over is totally illogical from the perspective of game theory — but, from the perspective of a human, honestly kind of relatable.