Le Golfe, la montagne et la base militaire : chroniques d’un monde exonyme (et d’une purge fasciste).
Publication pour archivage de l’article paru sur AOC.media le 20 Février 2025 et titré « Blacklisté – sur le rapport fasciste de Trump au langage. »
Encore des mots, toujours des mots, rien que des mots. C’est une guerre sur la langue, sur le vocabulaire, sur les mots, sur la nomination et la dénomination possible. Sur ce qu’il est ou non possible de nommer. Une guerre avec ses frappes. Une guerre particulière car lorsque ce sont des mots qui sautent, c’est toute l’humanité qui est victime collatérale directe et immédiate.
Au lendemain de son accession au pouvoir et dans la longue liste des décrets de turpitude de cet homme décrépit, Trump donc annonçait vouloir changer le nom d’un golfe, d’une montagne et d’une base militaire.
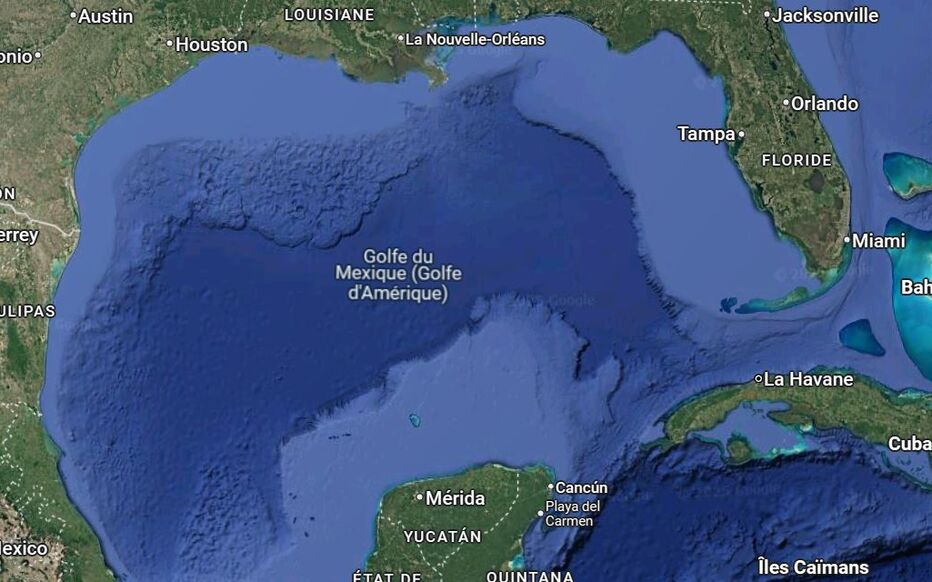
Le golfe c’est celui du Mexique que Trump a voulu (et obtenu) renommer en golfe d’Amérique. L’enjeu c’est d’ôter symboliquement cette dénomination à la population mexicaine qu’il assimile totalement à un danger migratoire. Il y est parvenu.
La montagne c’est le Mont Denali, situé en Alaska. Anciennement Mont McKinley, il avait été changé en 2015 par Barack Obama selon le souhait des populations autochtones. L’enjeu est donc ici une nouvelle fois re réaffirmer la primauté de l’Amérique blanche. Il n’y est pas parvenu, le sénat de l’Alaska a voté contre.
La base militaire c’est celle de Fort Liberty, anciennement Fort Bragg, le nom d’un ancien général confédéré symbole du passé esclavagiste des USA, et que l’administration Biden avait modifié tout comme celui de neuf autres bases pour les mêmes raisons. Trump l’a renommé Fort Bragg. Et son ministre de la défense annonce que les autres bases militaires « dénommées » seront, de la même manière et pour les mêmes motifs, « renommées ». Et le passé esclavagiste des USA ainsi « honoré ».
Un monde exonyme. C’est à dire un monde dans lequel « un groupe de personnes dénomme un autre groupe de personnes, un lieu, une langue par un nom distinct du nom régulier employé par l’autre groupe pour se désigner lui-même » (Wikipédia)
Je leur dirai les mots noirs.
Une liste. De mots interdits. De mots à retirer. De mots qui, si vous les utilisez, dans un article scientifique ou dans des sites web en lien quelconque avec une quelconque administration US vous vaudront, à votre article, à votre site et donc aussi à vous-même, d’être « flaggés », d’être « signalés » et vos subventions fédérales ensuite « retirées ».
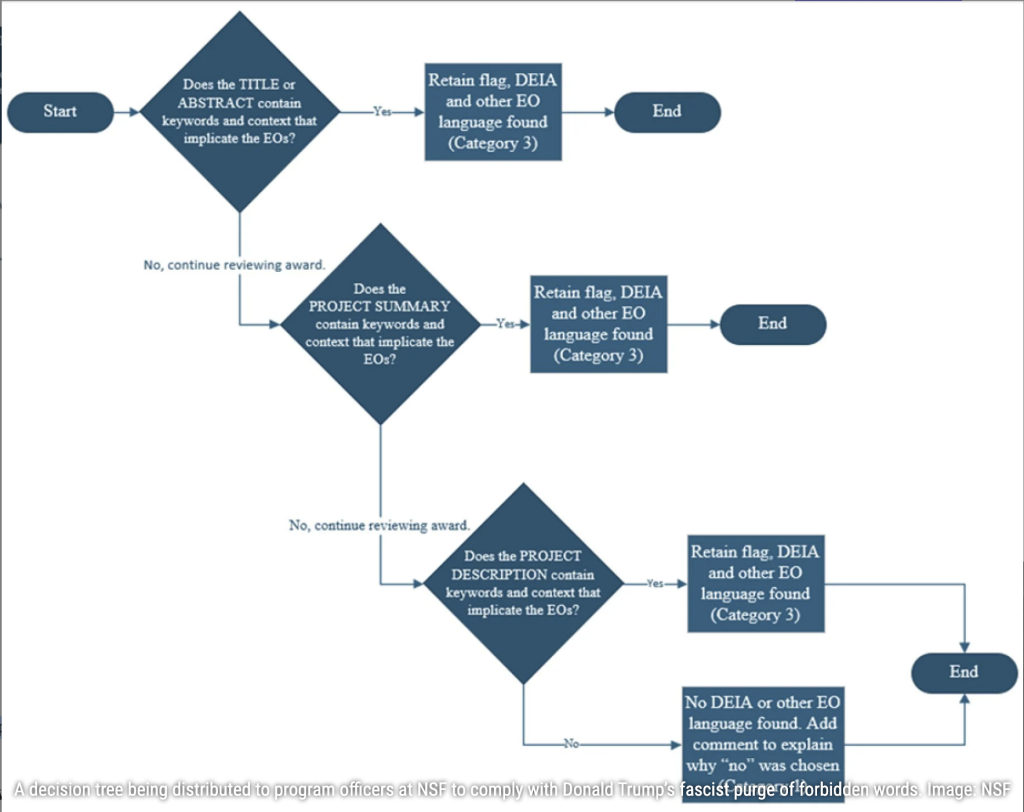
Comme cela a été révélé par le Washington Post, un arbre de décision, un logigramme a aussi été envoyé aux responsables des programmes scientifiques à la NSF (National Science Foundation) leur indiquant à quel moment prendre la décision de « couper » le déclenchement d’un financement si l’un des mots de la liste interdite apparaissait dans le descriptif général du projet, dans son titre, dans son résumé, etc. Une purge fasciste.
Des mots qui dans la tête de Trump ont vocation à disparaitre dans le présent inconditionnel qu’il instaure comme un temps politique majeur. La liste est longue. Elle mérite d’être affichée. Archivée. Mémorisée. Engrammée. Car Trump n’aime pas les archives. Il efface aussi des données. Ces mots-là :
- activism, activists, advocacy, advocate, advocates, barrier, barriers, biased, biased toward, biases, biases towards, bipoc, black and latinx, community diversity, community equity, cultural differences, cultural heritage, culturally responsive, disabilities, disability, discriminated, discrimination, discriminatory, diverse backgrounds, diverse communities, diverse community, diverse group, diverse groups, diversified, diversify, diversifying, diversity and inclusion, diversity equity, enhance the diversity, enhancing diversity, equal opportunity, equality, equitable, equity, ethnicity, excluded, female, females, fostering inclusivity, gender, gender diversity, genders, hate speech, excluded, female, females, fostering inclusivity, gender, gender diversity, genders, hate speech, hispanic minority, historically, implicit bias, implicit biases, inclusion, inclusive, inclusiveness, inclusivity, increase diversity, increase the diversity, indigenous community, inequalities, inequality, inequitable, inequities, institutional, Igbt, marginalize, marginalized, minorities, minority, multicultural, polarization, political, prejudice, privileges, promoting diversity, race and ethnicity, racial, racial diversity, racial inequality, racial justice, racially, racism, sense of belonging, sexual preferences, social justice, sociocultural, socioeconomic, status, stereotypes, systemic, trauma, under appreciated, under represented, under served, underrepresentation, underrepresented, underserved, undervalued, victim, women, women and underrepresented.
Diversité, équité et inclusion. La « DEI » contre laquelle Trump entre en guerre. Guerre qu’il remporte avec l’appui de son administration mais aussi et surtout de tout un large pan de l’industrie médiatique et numérique. La science aux ordres du pouvoir.
« Erase Baby, Erase ! »
Il faut effacer. « Erase Baby, Erase. » Comme Anne-Cécile Mailfert le rappelait dans sa chronique sur France Inter :
Son administration ne se contente pas de sabrer dans les budgets de la recherche ou de nier les faits scientifiques. Elle tente de supprimer les données qui la dérangent. Les indices de vulnérabilité sociale du Centre pour le contrôle et la prévention des maladies ? Supprimés. Les pages du ministère des Transports sur l’égalité, le genre et le climat ? Évaporées. Les études sur la santé publique qui mettent en lumière les inégalités croisées ? Effacées. Imaginez un immense autodafé numérique, où ce ne sont plus des livres qu’on brûle, mais des sites web, des pages Internet, des index, des bases de données. (…)
Trump et son administration ne se contentent pas de faire disparaître des informations. Ils empêchent que de nouvelles soient créées. Les chercheurs qui souhaitent être financés par l’État fédéral doivent maintenant éviter des termes comme « diversité », « inclusion », « femme », « LGBTQI « , « changement climatique ». Imaginez : des scientifiques contraints de parler d’ouragans sans pouvoir mentionner le climat, d’étudier les inégalités sans pouvoir dire « femme » ou “racisme”. C’est Orwell qui rencontre Kafka dans un épisode de Black Mirror.
Dans le cadre de la NSA (National Security Agency) c’est le « Big Delete », le grand effacement. Des pages et des sites entiers qui disparaissent, puis qui parfois réapparaissent sans jamais être capable de dire précisément ce qui a entre temps été modifié ou supprimé ou réécrit …
Ingénieries de l’effacement.
Il y a donc le langage, et puis il y a l’ensemble des ingénieries de l’effacement des mots, du travestissement de la langue, de la dissimulation du sens. Au premier rang desquelles les ingénieries du numérique. Dans l’une des dernières livraison de sa Newsletter « Cybernetica », Tariq Krim rappelait comment « lorsque vous utilisez Google Maps aux États-Unis, (…) l’application affiche désormais Gulf of America pour les utilisateurs américains, tout en conservant Gulf of Mexico pour les utilisateurs mexicains et en affichant les deux noms ailleurs. » Jusque-là le numérique et Google ne sont coupables de rien, ils se contentent d’appliquer les règles du droit. Mais ce faisant bien sûr ils s’exposent. Et la manière dont ils répondent à cette exposition est une entrave considérable à nos propres dénominations, à nos capacités à négocier ces dénominations au coeur même des espaces qui le mobilisent et les activent. Ainsi Tariq Krim rappelait également que « maintenant, Google Maps empêche les utilisateurs de laisser des avis sur cet emplacement. Cette restriction intervient après une vague de critiques et de review-bombing, où des centaines d’utilisateurs ont attribué une étoile à l’application pour dénoncer ce changement. »
Et puis il est d’autres exemples dans lesquels ce sont cette fois ces acteurs du numérique eux-mêmes qui se placent en situation de complaire aux politiques fascisantes en cours, non qu’elles en épousent nécessairement l’idéologie, mais par ce qui relève a minima d’une opportune lâcheté alignée sur un opportunisme économique. Ainsi la décision de Méta et de Zuckergerg de revenir (rien ne l’y obligeait) sur ses propres politiques en termes de DEI, ainsi la décision de Google (rien ne l’y obligeait non plus) de supprimer de Google Calendar l’affichage par défaut d’événements liés à la Gay Pride (marche des fiertés), au Black History Month (BHM), supprimant aussi les rappels calendaires suivants : « Indigenous People Month, Jewish Heritage, Holocaust Remembrance Day, and Hispanic Heritage. »
Les LGBTQIA+, les Noirs, les peuples indigènes, les Juifs et les Latinos. Le tout dans un monde où un salut Nazi n’est plus seulement inqualifiable sur le plan de l’éthique et de la morale, mais dans un monde où plus personne ne semble capable de simplement le qualifier pour ce qu’il est.
Un grand remplacement documentaire et linguistique.
Il y a les données, les discours, les dates et les mots qui s’effacent, que Trump, et Musk notamment effacent. Effacent et remplacent. Et il y a le grignotage en cours des espaces (notamment) numériques dans lesquels les contenus « générés artificiellement » sont un grand remplacement documentaire. Des contenus générés artificiellement, un web synthétique qui non seulement gagne du terrain mais qui a la double particularité, d’une part de se nourrir d’archives, et d’autre part d’être totalement inféodé aux règles de génération déterminées par les entreprises qui le déploient. Or ces archives (et ce besoin de bases de données pour être entraîné et pour pouvoir générer des contenus), ces archives et ces bases de données sont en train d’être littéralement purgées de certains contenus. Et les règles de génération sont de leur côté totalement inféodées à des idéologies fascisantes qui dictent leurs agendas.
Une boucle paradoxale dans laquelle les mêmes technologies d’IA utilisées pour générer des contenus jusqu’au-delà de la saturation sont également mobilisées et utilisées pour rechercher, détecter et supprimer les mots interdits. Et à partir de là de nouveau générer des contenus à saturation mais cette fois exempts autant qu’exsangues de cette langue et de ces mots.
La certitude d’une ingérence.
Avec ce que révèle et met en place le second mandat de Trump, avec l’évolution de la marche du monde qui l’accompagne et sa cohorte de régimes autoritaires, illibéraux ou carrément dictatoriaux d’un bout à l’autre de la planète, nous sommes à ce moment précis de bascule où nous mesurons à quel point tout ce qui jusqu’ici était disqualifié comme discours catastrophiste ou alarmiste se trouve soudainement requalifié en discours simplement programmatique.
Et l’abîme qui s’ouvre devant nous est vertigineux. Que fera une administration (celle de Trump aujourd’hui ou une autre, ailleurs, demain), que fera une telle administration de l’ensemble de ces données, aussi bien d’ailleurs de celles qu’elle choisit de conserver que de celles qu’elle choisit d’effacer ? Je l’avais (notamment) documenté dans ma série d’articles sur le mouvement des Gilets Jaunes, et plus particulièrement dans celui intitulé « Après avoir Liké, les Gilets Jaunes vont-ils voter ?« , il faut s’en rappeler aujourd’hui :
Quelle que soit l’issue du mouvement, la base de donnée « opinion » qui restera aux mains de Facebook est une bombe démocratique à retardement … Et nous n’avons à ce jour absolument aucune garantie qu’elle ne soit pas vendue à la découpe au(x) plus offrant(s).
Et ce qui est aux mains de Facebook est aujourd’hui aux mains de Trump. Le ralliement de Zuckerberg (et de l’ensemble des patrons des Big Tech) à Trump, l’état de la démocratie US autant que les enjeux à l’oeuvre dans le cadre de prochaines élections européennes et Françaises, ne laisse pas seulement « entrevoir » des « possibilités » d’ingérence, mais elle les constitue en certitude, certitude que seule limite (pour l’instant) l’incompétence analytique de ceux qui mettent en place ces outils de captation et leurs infrastructures techniques toxiques (ladite incompétence analytique pouvant aussi entraîner nombre d’autres errances et catastrophes).
Dans un autre genre, et alors que la Ligue des Drois de l’Homme vient de déposer plainte en France contre Apple au sujet de l’enregistrement (non consenti) de conversations via son assistant vocal Siri, et que l’on sait que ces enregistrements non-consentis couvrent toute la gamme des acteurs qui proposent de tels assistants vocaux et leur palette d’enceintes connectés, c’est à dire d’Apple à Amazon en passant par Facebook, Microsoft et Google, et par-delà ce qu’Olivier Tesquet qualifie de « Watergate domestique », qu’est-ce qu’une administration qui efface des mots, qui en interdit d’autres, qui réécrit des sites ou modifie et invisibilise des pans entiers de la recherche scientifique, qu’est-ce que ce genre d’administration est capable de faire de l’ensemble de ces conversations enregistrées et qui relèvent de l’intime et du privé ?
Il semble que nous n’ayons finalement rien appris, rien retenu et surtout rien compris de ce qu’ont révélé Edward Snowden et Julian Assange. Ils montraient la surveillance de masse et nous regardions le risque d’une surveillance de masse. Ils montraient le danger du politique et nous regardions le danger de la technique. Il est en tout cas évident que malgré les lanceurs d’alerte qui ont mis leur réputation et parfois leur vie en danger, que malgré le travail tenace et sans relâche des militantes et militants des libertés numériques, il semble que rien de tout cela n’ait été suffisant.
Calculer la langue.
Orwell en a fait un roman, d’immenses penseurs ont réfléchi à la question de la propagande, à celle de la langue et du vocabulaire à son service ; aujourd’hui en terre numérique et à l’aune de ce que l’on qualifie bien improprement « d’intelligence artificielle », en héritage aussi du capitalisme linguistique théorisé par Frédéric Kaplan, aujourd’hui la langue est attaquée à une échelle jamais atteinte. Aujourd’hui tout comme les possibilités de propagande, les possibilités de censure, d’effacement, de détournement n’ont jamais été aussi simples et aussi massives ; elles n’ont jamais été autant à disposition commode de puissances accommodantes ; et jamais l’écart avec les possibilités d’y résister, d’y échapper, de s’y soustraire ou même simplement de documenter ces effacements, ces travestissements et ces censures, jamais cet écart n’a été aussi grand. En partie parce que les puissances calculatoires sont aujourd’hui en situation et capacité d’atteindre la langue dans des mécanismes de production demeurés longtemps incalculables. On appelle cela en linguistique de corpus et dans le traitement automatique du langage, les « entités nommées« , c’est à dire cette capacité « à rechercher des objets textuels (c’est-à-dire un mot, ou un groupe de mots) catégorisables dans des classes telles que noms de personnes, noms d’organisations ou d’entreprises, noms de lieux, quantités, distances, valeurs, dates, etc. » Le travail sur ces entités nommées existe depuis les années 1990 ; elles ont été la base de tous les travaux d’ingénierie linguistique et sont actuellement l’un des coeurs de la puissance générative qui fait aujourd’hui illusion au travers d’outils comme ChatGPT : la recherche, la détection, l’analyse et la production sous stéroïdes d’entités nommées dans des corpus documentaires de l’ordre de l’aporie, c’est à dire à la fois calculables linguistiquement mais incommensurables pour l’entendement.
Quand il n’y aura plus rien à dire, il n’y aura plus rien à voter.
En conclusion il semble important de redire, de ré-expliquer et de réaffirmer qu’à chaque fois que nous utilisons des artefacts génératifs, et qu’à chaque fois que nous sommes confrontés à leurs productions (en le sachant ou sans le savoir), nous sommes avant toute chose face à un système de valeurs. Un article récent de Wired se fait l’écho des travaux de Dan Hendrycks (directeur du Center for AI Safety) et de ses collègues (l’article scientifique complet est également disponible en ligne en version préprint) :
Hendrycks et ses collègues ont mesuré les perspectives politiques de plusieurs modèles d’IA de premier plan, notamment Grok de xAI, GPT-4o d’OpenAI et Llama 3.3 de Meta. Grâce à cette technique, ils ont pu comparer les valeurs des différents modèles aux programmes de certains hommes politiques, dont Donald Trump, Kamala Harris, Bernie Sanders et la représentante républicaine Marjorie Taylor Greene. Tous étaient beaucoup plus proches de l’ancien président Joe Biden que de n’importe lequel des autres politiciens.
Les chercheurs proposent une nouvelle façon de modifier le comportement d’un modèle en changeant ses fonctions d’utilité sous-jacentes au lieu d’imposer des garde-fous qui bloquent certains résultats. En utilisant cette approche, Hendrycks et ses coauteurs développent ce qu’ils appellent une « assemblée citoyenne« . Il s’agit de collecter des données de recensement américaines sur des questions politiques et d’utiliser les réponses pour modifier les valeurs d’un modèle LLM open-source. Le résultat est un modèle dont les valeurs sont systématiquement plus proches de celles de Trump que de celles de Biden. [Traduction via DeepL et moi-même]
En forme de boutade je pourrais écrire que cette expérimentation qui tend à rapprocher le LLM (large modèle de langage) des valeurs de Donald Trump est, pour le coup, enfin une intelligence vraiment artificielle.
En forme d’angoisse (et c’est pour le coup l’une des seules et des rares qui me terrifie sincèrement et depuis longtemps) je pourrais également écrire que jamais nous n’avons été aussi proche d’une expérimentation grandeur nature de ce que décrit Asimov dans sa nouvelle : « Le votant ». Plus rien technologiquement n’empêche en tout cas de réaliser le scénario décrit par Asimov, à savoir un vote totalement électronique dans lequel un « super ordinateur » (Multivac dans la nouvelle) serait capable de choisir un seul citoyen américain considéré comme suffisamment représentatif de l’ensemble de tout un corps électoral sur la base d’analyses croisant la fine fleur des technologies de Data Mining et d’Intelligence artificielle. On peut même tout à fait imaginer l’étape d’après la nouvelle d’Asimov, une étape dans laquelle l’ordinateur seul serait capable de prédire et d’acter le vote, un monde dans lequel il ne serait tout simplement plus besoin de voter. Précisément le monde de Trump qui se faisait Augure de cette possibilité : « Dans quatre ans, vous n’aurez plus à voter. »
En forme d’analyse le seul enjeu démocratique du siècle à venir et des élections qui vont, à l’échelle de la planète se dérouler dans les 10 ou 20 prochaines années, sera de savoir au service de qui seront mis ces grands modèles de langage. Et avant cela de savoir s’il est possible de connaître leur système de valeurs. Et pour cela de connaître celles et ceux qui décident de ces systèmes de valeurs et de pouvoir leur en faire rendre publiquement compte. Et pour cela, enfin, de savoir au service et aux intérêts de qui travaillent celles et ceux qui décident du système de valeurs de ces machines de langage ; machines de langage qui ne seront jamais au service d’autres que celles et ceux qui en connaissent, en contrôlent et en définissent le système de valeurs. Et quand il n’y aura plus rien à dire, il n’y aura plus à voter.